 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBinaryBERT: Pushing the Limit of BERT Quantization
Paper and Code
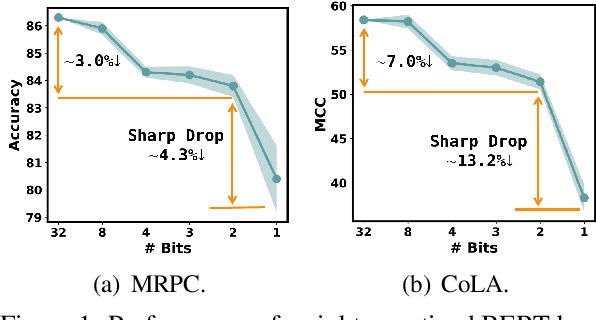
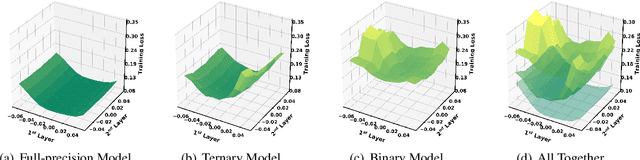
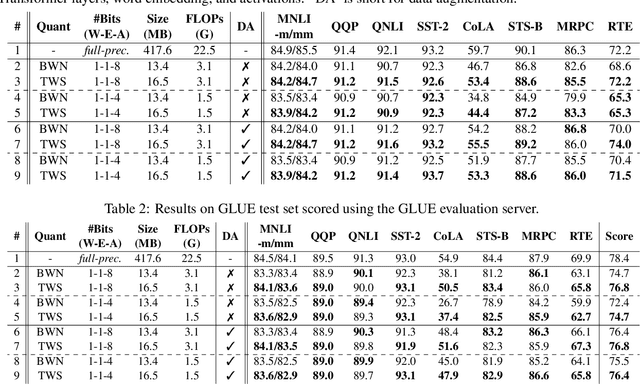
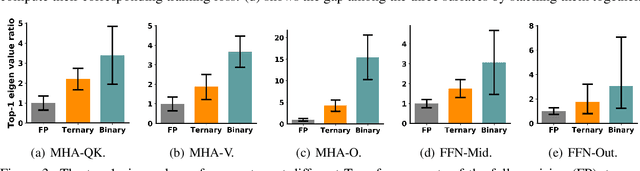
The rapid development of large pre-trained language models has greatly increased the demand for model compression techniques, among which quantization is a popular solution. In this paper, we propose BinaryBERT, which pushes BERT quantization to the limit with weight binarization. We find that a binary BERT is hard to be trained directly than a ternary counterpart due to its complex and irregular loss landscapes. Therefore, we propose ternary weight splitting, which initializes the binary model by equivalent splitting from a half-sized ternary network. The binary model thus inherits the good performance of the ternary model, and can be further enhanced by fine-tuning the new architecture after splitting. Empirical results show that BinaryBERT has negligible performance drop compared to the full-precision BERT-base while being $24\times$ smaller, achieving the state-of-the-art results on GLUE and SQuAD benchmarks.