 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised Online Hashing via Similarity Distribution Learning
Paper and Code
May 31, 2019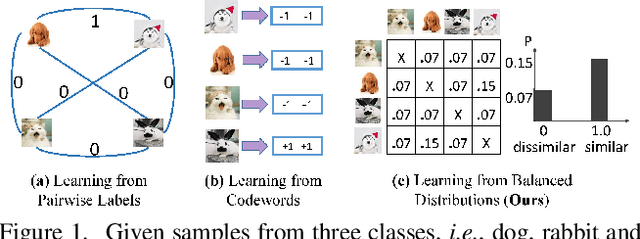
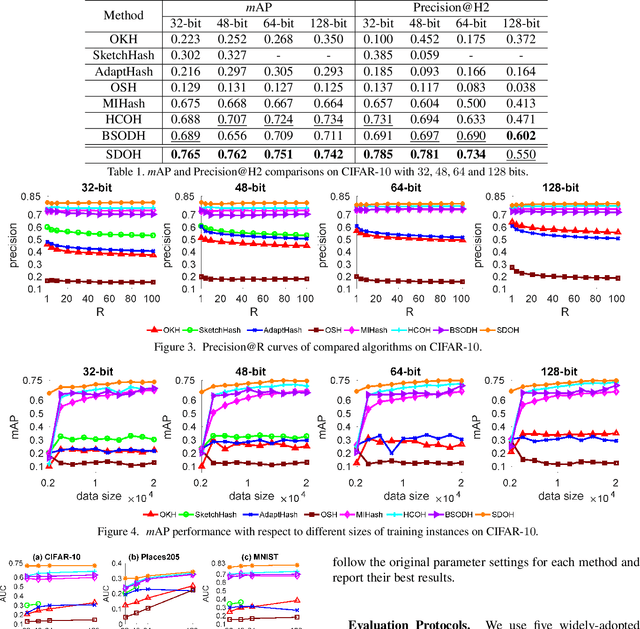
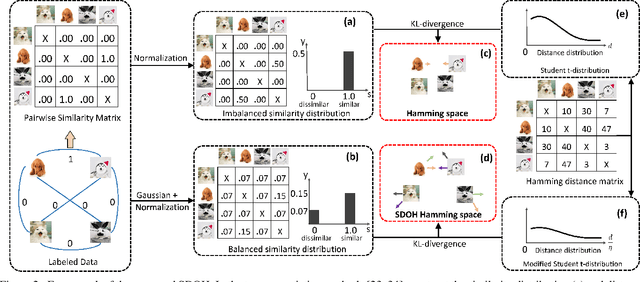
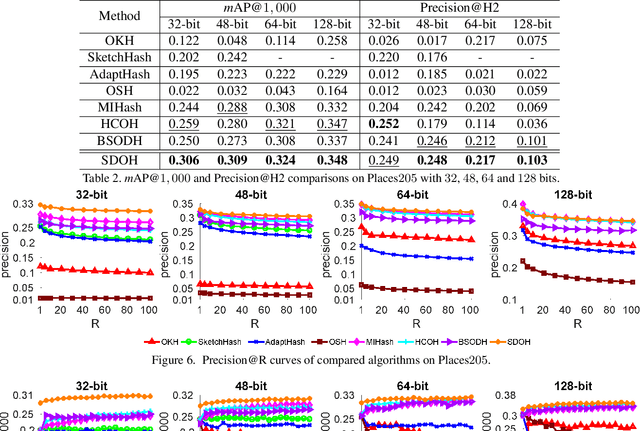
Online hashing has attracted extensive research attention when facing streaming data. Most online hashing methods, learning binary codes based on pairwise similarities of training instances, fail to capture the semantic relationship, and suffer from a poor generalization in large-scale applications due to large variations. In this paper, we propose to model the similarity distributions between the input data and the hashing codes, upon which a novel supervised online hashing method, dubbed as Similarity Distribution based Online Hashing (SDOH), is proposed, to keep the intrinsic semantic relationship in the produced Hamming space. Specifically, we first transform the discrete similarity matrix into a probability matrix via a Gaussian-based normalization to address the extremely imbalanced distribution issue. And then, we introduce a scaling Student t-distribution to solve the challenging initialization problem, and efficiently bridge the gap between the known and unknown distributions. Lastly, we align the two distributions via minimizing the Kullback-Leibler divergence (KL-diverence) with stochastic gradient descent (SGD), by which an intuitive similarity constraint is imposed to update hashing model on the new streaming data with a powerful generalizing ability to the past data. Extensive experiments on three widely-used benchmarks validate the superiority of the proposed SDOH over the state-of-the-art methods in the online retrieval task.