 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Resolution Representations for Labeling Pixels and Regions
Paper and Code

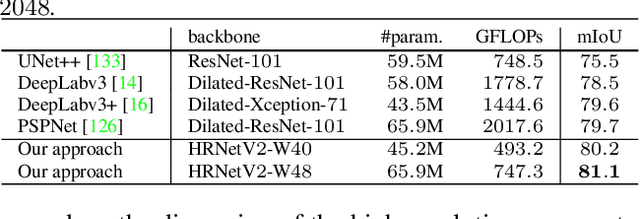
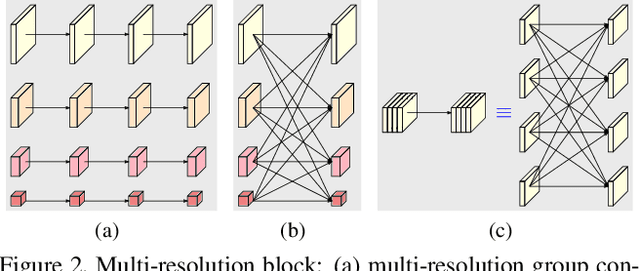
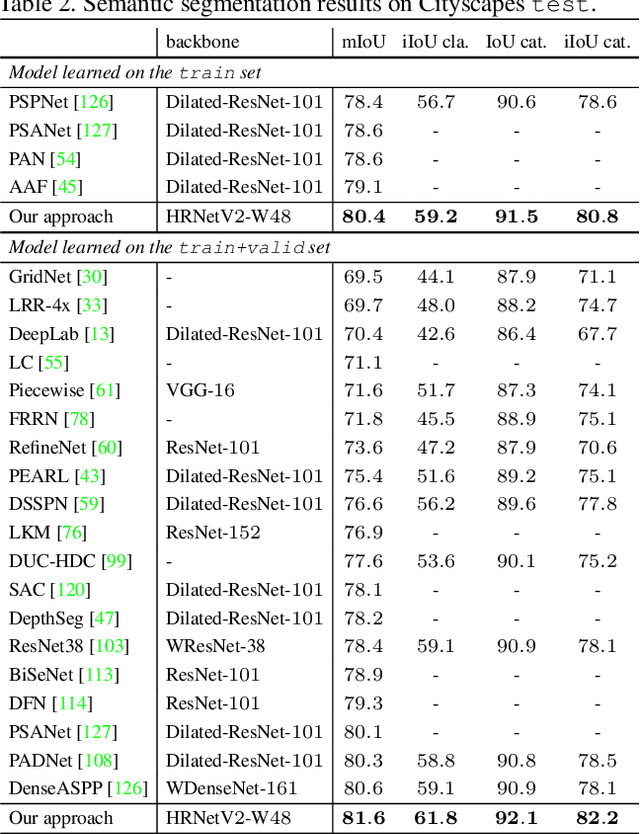
High-resolution representation learning plays an essential role in many vision problems, e.g., pose estimation and semantic segmentation. The high-resolution network (HRNet)~\cite{SunXLW19}, recently developed for human pose estimation, maintains high-resolution representations through the whole process by connecting high-to-low resolution convolutions in \emph{parallel} and produces strong high-resolution representations by repeatedly conducting fusions across parallel convolutions. In this paper, we conduct a further study on high-resolution representations by introducing a simple yet effective modification and apply it to a wide range of vision tasks. We augment the high-resolution representation by aggregating the (upsampled) representations from all the parallel convolutions rather than only the representation from the high-resolution convolution as done in~\cite{SunXLW19}. This simple modification leads to stronger representations, evidenced by superior results. We show top results in semantic segmentation on Cityscapes, LIP, and PASCAL Context, and facial landmark detection on AFLW, COFW, $300$W, and WFLW. In addition, we build a multi-level representation from the high-resolution representation and apply it to the Faster R-CNN object detection framework and the extended frameworks. The proposed approach achieves superior results to existing single-model networks on COCO object detection. The code and models have been publicly available at \url{https://github.com/HRNet}.