 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Hierarchy for Learning and Transfer in KL-regularized RL
Paper and Code
Mar 18, 2019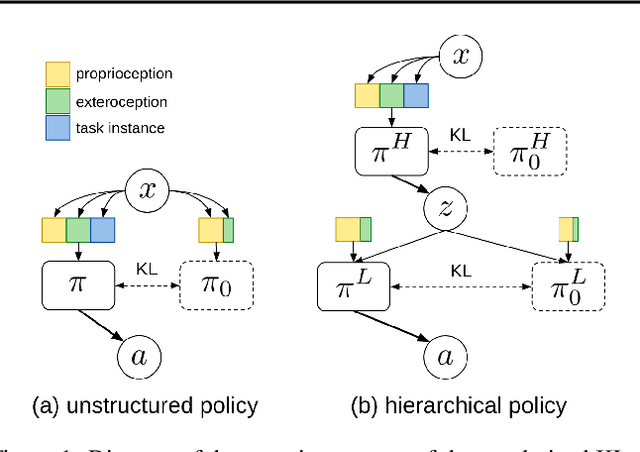
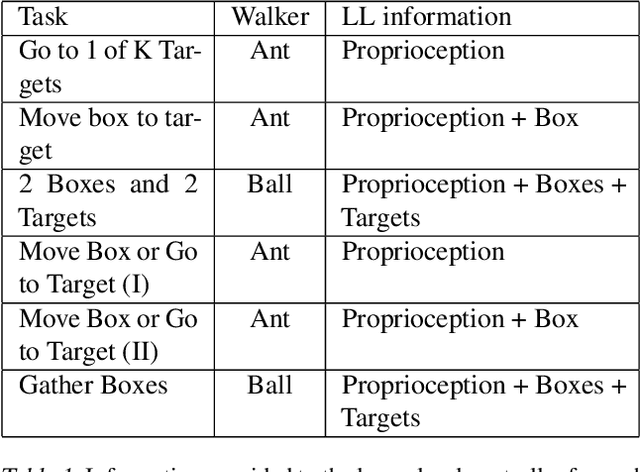

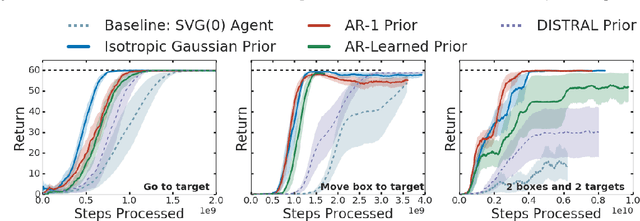
As reinforcement learning agents are tasked with solving more challenging and diverse tasks, the ability to incorporate prior knowledge into the learning system and to exploit reusable structure in solution space is likely to become increasingly important. The KL-regularized expected reward objective constitutes one possible tool to this end. It introduces an additional component, a default or prior behavior, which can be learned alongside the policy and as such partially transforms the reinforcement learning problem into one of behavior modelling. In this work we consider the implications of this framework in cases where both the policy and default behavior are augmented with latent variables. We discuss how the resulting hierarchical structures can be used to implement different inductive biases and how their modularity can benefit transfer. Empirically we find that they can lead to faster learning and transfer on a range of continuous control tasks.