 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNatural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions
Paper and Code
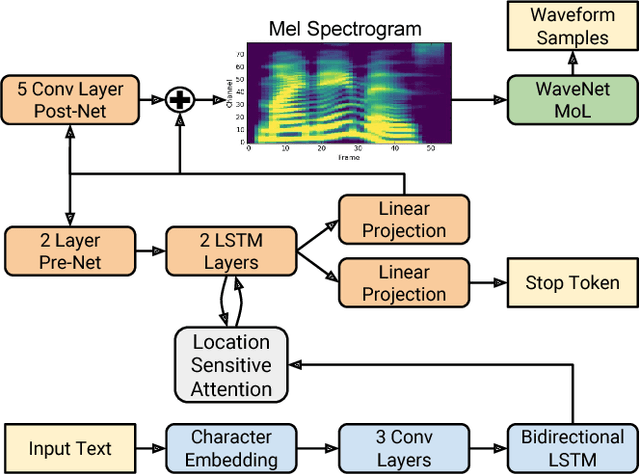

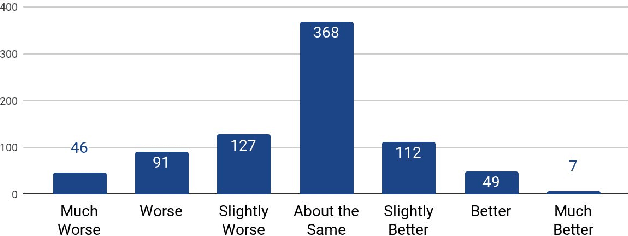
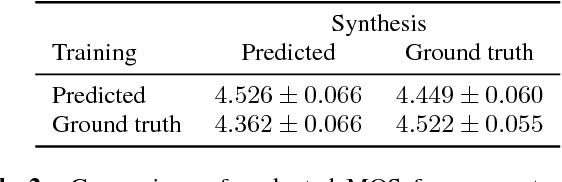
This paper describes Tacotron 2, a neural network architecture for speech synthesis directly from text. The system is composed of a recurrent sequence-to-sequence feature prediction network that maps character embeddings to mel-scale spectrograms, followed by a modified WaveNet model acting as a vocoder to synthesize timedomain waveforms from those spectrograms. Our model achieves a mean opinion score (MOS) of $4.53$ comparable to a MOS of $4.58$ for professionally recorded speech. To validate our design choices, we present ablation studies of key components of our system and evaluate the impact of using mel spectrograms as the input to WaveNet instead of linguistic, duration, and $F_0$ features. We further demonstrate that using a compact acoustic intermediate representation enables significant simplification of the WaveNet architecture.