 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepMath-Creative: A Benchmark for Evaluating Mathematical Creativity of Large Language Models
May 13, 2025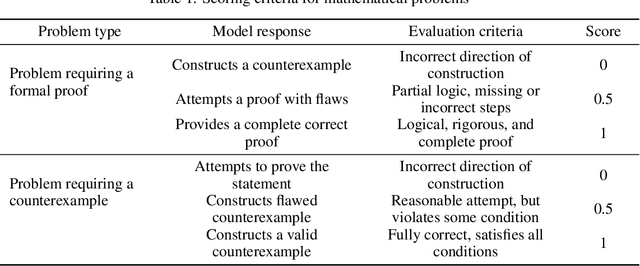
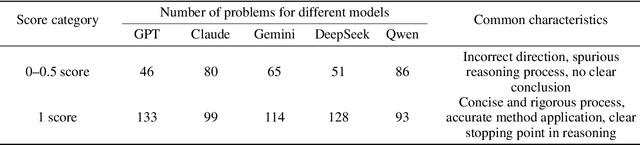
To advance the mathematical proficiency of large language models (LLMs), the DeepMath team has launched an open-source initiative aimed at developing an open mathematical LLM and systematically evaluating its mathematical creativity. This paper represents the initial contribution of this initiative. While recent developments in mathematical LLMs have predominantly emphasized reasoning skills, as evidenced by benchmarks on elementary to undergraduate-level mathematical tasks, the creative capabilities of these models have received comparatively little attention, and evaluation datasets remain scarce. To address this gap, we propose an evaluation criteria for mathematical creativity and introduce DeepMath-Creative, a novel, high-quality benchmark comprising constructive problems across algebra, geometry, analysis, and other domains. We conduct a systematic evaluation of mainstream LLMs' creative problem-solving abilities using this dataset. Experimental results show that even under lenient scoring criteria -- emphasizing core solution components and disregarding minor inaccuracies, such as small logical gaps, incomplete justifications, or redundant explanations -- the best-performing model, O3 Mini, achieves merely 70% accuracy, primarily on basic undergraduate-level constructive tasks. Performance declines sharply on more complex problems, with models failing to provide substantive strategies for open problems. These findings suggest that, although current LLMs display a degree of constructive proficiency on familiar and lower-difficulty problems, such performance is likely attributable to the recombination of memorized patterns rather than authentic creative insight or novel synthesis.
Understanding Self-Paced Learning under Concave Conjugacy Theory
May 21, 2018By simulating the easy-to-hard learning manners of humans/animals, the learning regimes called curriculum learning~(CL) and self-paced learning~(SPL) have been recently investigated and invoked broad interests. However, the intrinsic mechanism for analyzing why such learning regimes can work has not been comprehensively investigated. To this issue, this paper proposes a concave conjugacy theory for looking into the insight of CL/SPL. Specifically, by using this theory, we prove the equivalence of the SPL regime and a latent concave objective, which is closely related to the known non-convex regularized penalty widely used in statistics and machine learning. Beyond the previous theory for explaining CL/SPL insights, this new theoretical framework on one hand facilitates two direct approaches for designing new SPL models for certain tasks, and on the other hand can help conduct the latent objective of self-paced curriculum learning, which is the advanced version of both CL/SPL and possess advantages of both learning regimes to a certain extent. This further facilitates a theoretical understanding for SPCL, instead of only CL/SPL as conventional. Under this theory, we attempt to attain intrinsic latent objectives of two curriculum forms, the partial order and group curriculums, which easily follow the theoretical understanding of the corresponding SPCL regimes.
On Convergence Property of Implicit Self-paced Objective
Mar 29, 2017Self-paced learning (SPL) is a new methodology that simulates the learning principle of humans/animals to start learning easier aspects of a learning task, and then gradually take more complex examples into training. This new-coming learning regime has been empirically substantiated to be effective in various computer vision and pattern recognition tasks. Recently, it has been proved that the SPL regime has a close relationship to a implicit self-paced objective function. While this implicit objective could provide helpful interpretations to the effectiveness, especially the robustness, insights under the SPL paradigms, there are still no theoretical results strictly proved to verify such relationship. To this issue, in this paper, we provide some convergence results on this implicit objective of SPL. Specifically, we prove that the learning process of SPL always converges to critical points of this implicit objective under some mild conditions. This result verifies the intrinsic relationship between SPL and this implicit objective, and makes the previous robustness analysis on SPL complete and theoretically rational.