 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisCUIT: Visual Auditor for Bias in CNN Image Classifier
Apr 13, 2022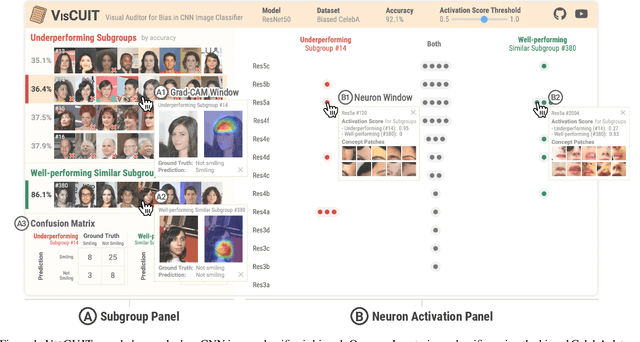

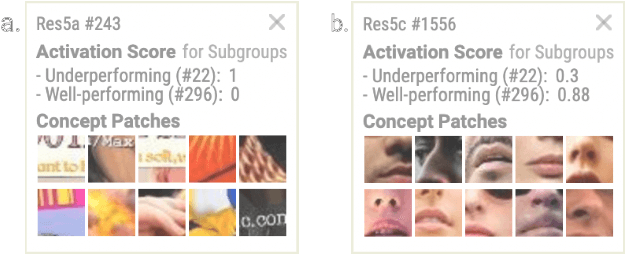

CNN image classifiers are widely used, thanks to their efficiency and accuracy. However, they can suffer from biases that impede their practical applications. Most existing bias investigation techniques are either inapplicable to general image classification tasks or require significant user efforts in perusing all data subgroups to manually specify which data attributes to inspect. We present VisCUIT, an interactive visualization system that reveals how and why a CNN classifier is biased. VisCUIT visually summarizes the subgroups on which the classifier underperforms and helps users discover and characterize the cause of the underperformances by revealing image concepts responsible for activating neurons that contribute to misclassifications. VisCUIT runs in modern browsers and is open-source, allowing people to easily access and extend the tool to other model architectures and datasets. VisCUIT is available at the following public demo link: https://poloclub.github.io/VisCUIT. A video demo is available at https://youtu.be/eNDbSyM4R_4.
StickyLand: Breaking the Linear Presentation of Computational Notebooks
Feb 22, 2022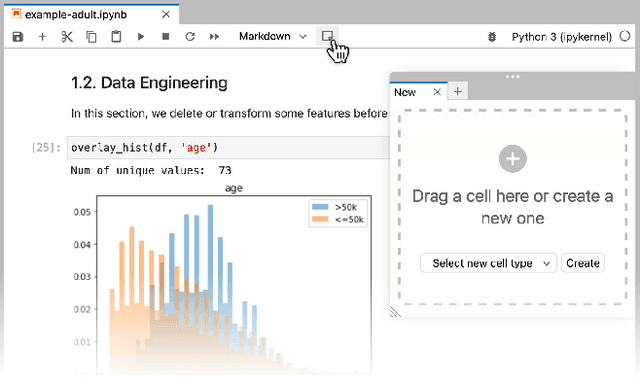
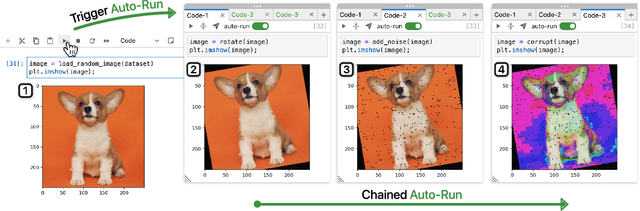
How can we better organize code in computational notebooks? Notebooks have become a popular tool among data scientists, as they seamlessly weave text and code together, supporting users to rapidly iterate and document code experiments. However, it is often challenging to organize code in notebooks, partially because there is a mismatch between the linear presentation of code and the non-linear process of exploratory data analysis. We present StickyLand, a notebook extension for empowering users to freely organize their code in non-linear ways. With sticky cells that are always shown on the screen, users can quickly access their notes, instantly observe experiment results, and easily build interactive dashboards that support complex visual analytics. Case studies highlight how our tool can enhance notebook users's productivity and identify opportunities for future notebook designs. StickyLand is available at https://github.com/xiaohk/stickyland.
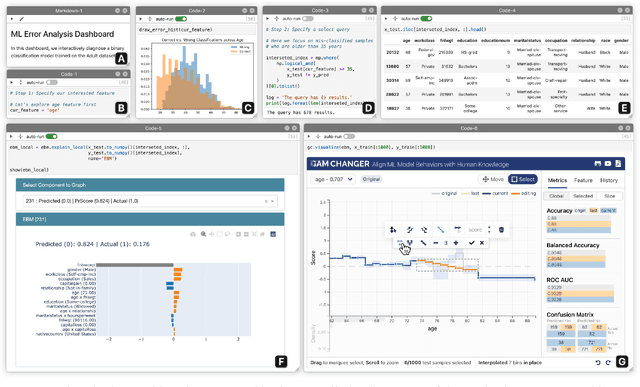
GAM Changer: Editing Generalized Additive Models with Interactive Visualization
Dec 06, 2021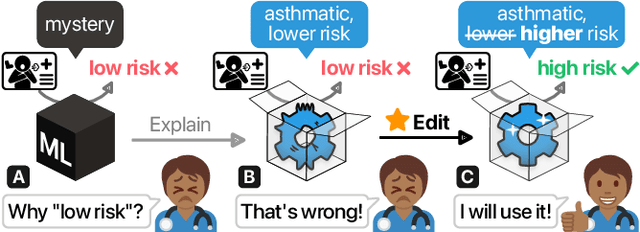

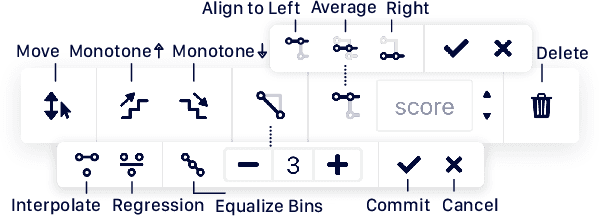
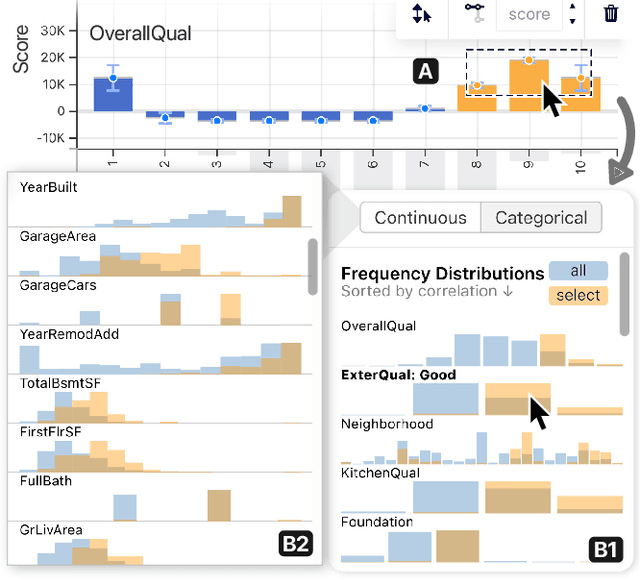
Recent strides in interpretable machine learning (ML) research reveal that models exploit undesirable patterns in the data to make predictions, which potentially causes harms in deployment. However, it is unclear how we can fix these models. We present our ongoing work, GAM Changer, an open-source interactive system to help data scientists and domain experts easily and responsibly edit their Generalized Additive Models (GAMs). With novel visualization techniques, our tool puts interpretability into action -- empowering human users to analyze, validate, and align model behaviors with their knowledge and values. Built using modern web technologies, our tool runs locally in users' computational notebooks or web browsers without requiring extra compute resources, lowering the barrier to creating more responsible ML models. GAM Changer is available at https://interpret.ml/gam-changer.
NL-Augmenter: A Framework for Task-Sensitive Natural Language Augmentation
Dec 06, 2021



Data augmentation is an important component in the robustness evaluation of models in natural language processing (NLP) and in enhancing the diversity of the data they are trained on. In this paper, we present NL-Augmenter, a new participatory Python-based natural language augmentation framework which supports the creation of both transformations (modifications to the data) and filters (data splits according to specific features). We describe the framework and an initial set of 117 transformations and 23 filters for a variety of natural language tasks. We demonstrate the efficacy of NL-Augmenter by using several of its transformations to analyze the robustness of popular natural language models. The infrastructure, datacards and robustness analysis results are available publicly on the NL-Augmenter repository (\url{https://github.com/GEM-benchmark/NL-Augmenter}).
Dodrio: Exploring Transformer Models with Interactive Visualization
Apr 12, 2021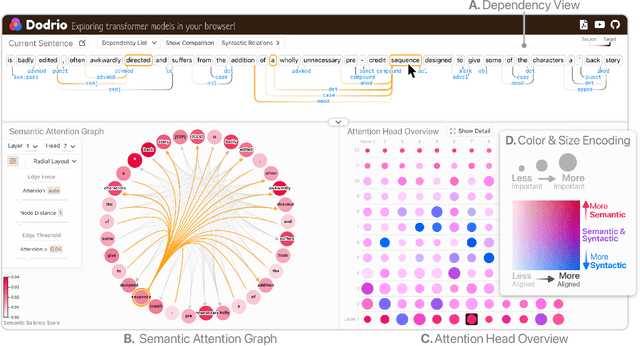
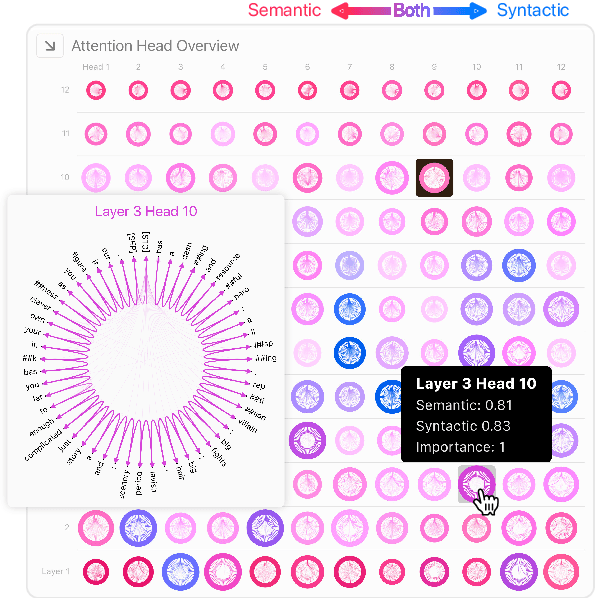
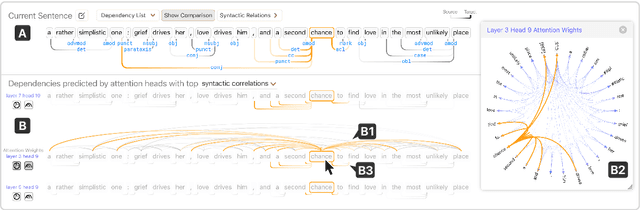
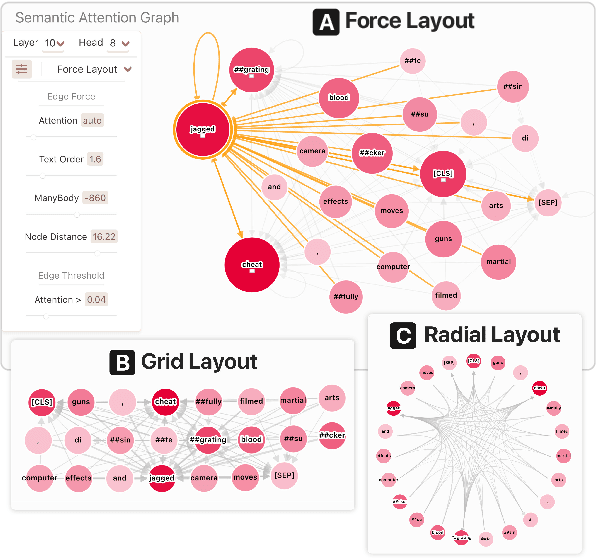
Why do large pre-trained transformer-based models perform so well across a wide variety of NLP tasks? Recent research suggests the key may lie in multi-headed attention mechanism's ability to learn and represent linguistic information. Understanding how these models represent both syntactic and semantic knowledge is vital to investigate why they succeed and fail, what they have learned, and how they can improve. We present Dodrio, an open-source interactive visualization tool to help NLP researchers and practitioners analyze attention mechanisms in transformer-based models with linguistic knowledge. Dodrio tightly integrates an overview that summarizes the roles of different attention heads, and detailed views that help users compare attention weights with the syntactic structure and semantic information in the input text. To facilitate the visual comparison of attention weights and linguistic knowledge, Dodrio applies different graph visualization techniques to represent attention weights scalable to longer input text. Case studies highlight how Dodrio provides insights into understanding the attention mechanism in transformer-based models. Dodrio is available at https://poloclub.github.io/dodrio/.
Putting Humans in the Natural Language Processing Loop: A Survey
Mar 06, 2021
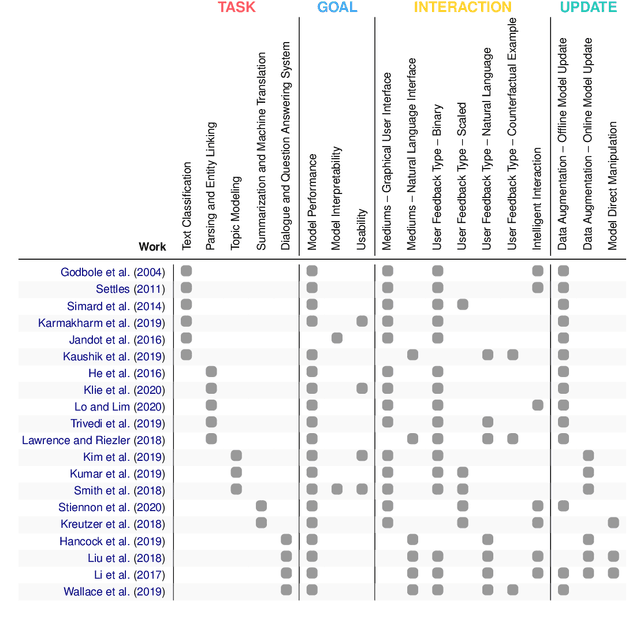
How can we design Natural Language Processing (NLP) systems that learn from human feedback? There is a growing research body of Human-in-the-loop (HITL) NLP frameworks that continuously integrate human feedback to improve the model itself. HITL NLP research is nascent but multifarious -- solving various NLP problems, collecting diverse feedback from different people, and applying different methods to learn from collected feedback. We present a survey of HITL NLP work from both Machine Learning (ML) and Human-Computer Interaction (HCI) communities that highlights its short yet inspiring history, and thoroughly summarize recent frameworks focusing on their tasks, goals, human interactions, and feedback learning methods. Finally, we discuss future directions for integrating human feedback in the NLP development loop.
SkeletonVis: Interactive Visualization for Understanding Adversarial Attacks on Human Action Recognition Models
Jan 26, 2021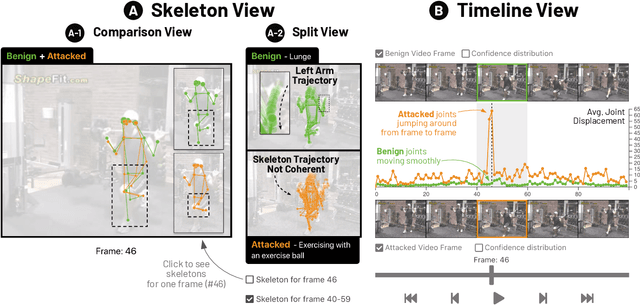
Skeleton-based human action recognition technologies are increasingly used in video based applications, such as home robotics, healthcare on aging population, and surveillance. However, such models are vulnerable to adversarial attacks, raising serious concerns for their use in safety-critical applications. To develop an effective defense against attacks, it is essential to understand how such attacks mislead the pose detection models into making incorrect predictions. We present SkeletonVis, the first interactive system that visualizes how the attacks work on the models to enhance human understanding of attacks.
Bluff: Interactively Deciphering Adversarial Attacks on Deep Neural Networks
Sep 08, 2020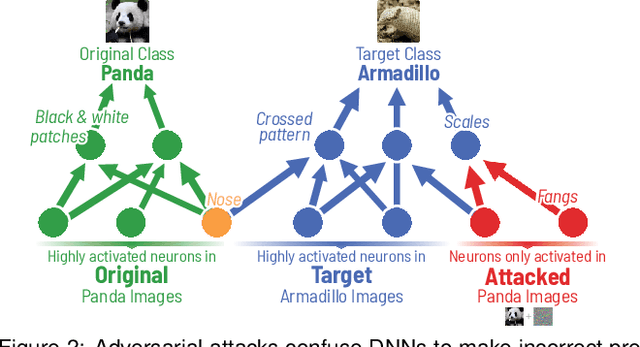
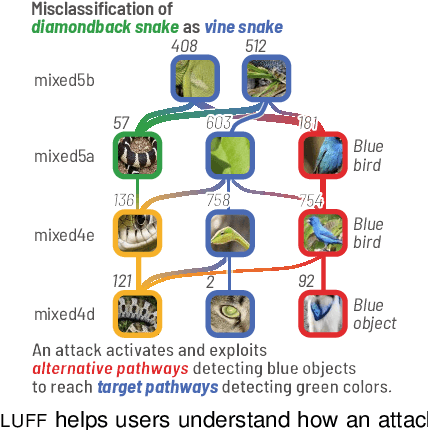
Deep neural networks (DNNs) are now commonly used in many domains. However, they are vulnerable to adversarial attacks: carefully crafted perturbations on data inputs that can fool a model into making incorrect predictions. Despite significant research on developing DNN attack and defense techniques, people still lack an understanding of how such attacks penetrate a model's internals. We present Bluff, an interactive system for visualizing, characterizing, and deciphering adversarial attacks on vision-based neural networks. Bluff allows people to flexibly visualize and compare the activation pathways for benign and attacked images, revealing mechanisms that adversarial attacks employ to inflict harm on a model. Bluff is open-sourced and runs in modern web browsers.
Mapping Researchers with PeopleMap
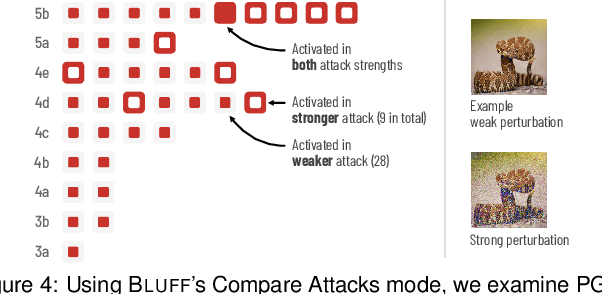
Aug 31, 2020Discovering research expertise at universities can be a difficult task. Directories routinely become outdated, and few help in visually summarizing researchers' work or supporting the exploration of shared interests among researchers. This results in lost opportunities for both internal and external entities to discover new connections, nurture research collaboration, and explore the diversity of research. To address this problem, at Georgia Tech, we have been developing PeopleMap, an open-source interactive web-based tool that uses natural language processing (NLP) to create visual maps for researchers based on their research interests and publications. Requiring only the researchers' Google Scholar profiles as input, PeopleMap generates and visualizes embeddings for the researchers, significantly reducing the need for manual curation of publication information. To encourage and facilitate easy adoption and extension of PeopleMap, we have open-sourced it under the permissive MIT license at https://github.com/poloclub/people-map. PeopleMap has received positive feedback and enthusiasm for expanding its adoption across Georgia Tech.
PeopleMap: Visualization Tool for Mapping Out Researchers using Natural Language Processing
Jun 10, 2020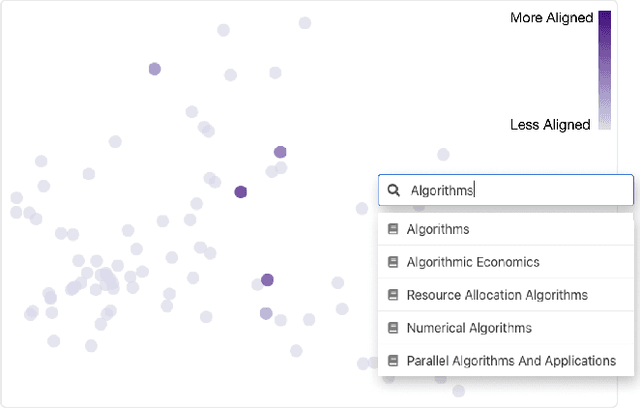
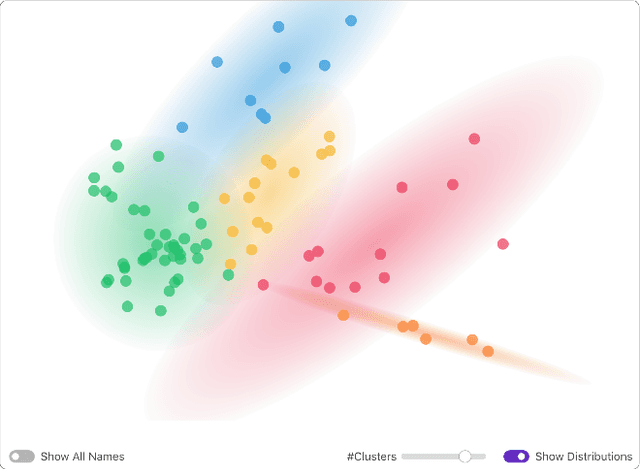
Discovering research expertise at institutions can be a difficult task. Manually curated university directories easily become out of date and they often lack the information necessary for understanding a researcher's interests and past work, making it harder to explore the diversity of research at an institution and identify research talents. This results in lost opportunities for both internal and external entities to discover new connections and nurture research collaboration. To solve this problem, we have developed PeopleMap, the first interactive, open-source, web-based tool that visually "maps out" researchers based on their research interests and publications by leveraging embeddings generated by natural language processing (NLP) techniques. PeopleMap provides a new engaging way for institutions to summarize their research talents and for people to discover new connections. The platform is developed with ease-of-use and sustainability in mind. Using only researchers' Google Scholar profiles as input, PeopleMap can be readily adopted by any institution using its publicly-accessible repository and detailed documentation.