 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeACGNet: Action Complement Graph Network for Weakly-supervised Temporal Action Localization
Dec 21, 2021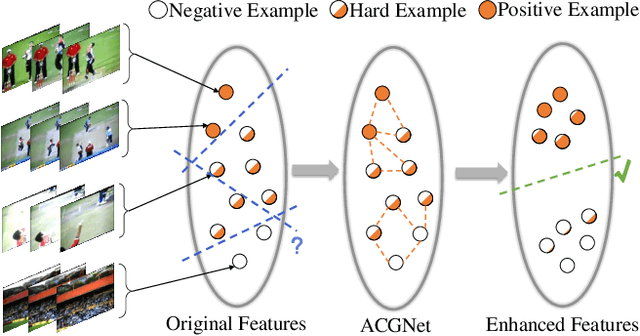
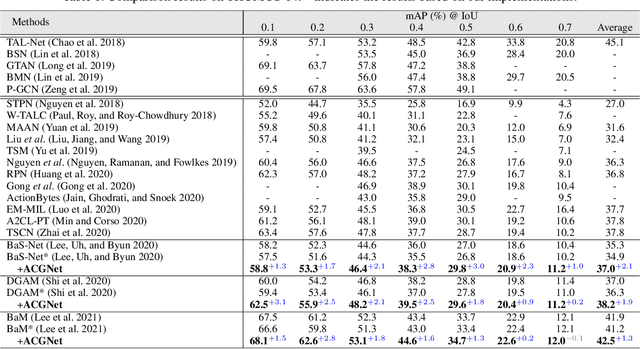
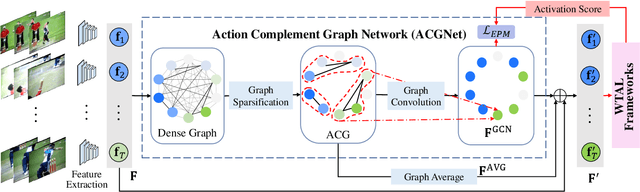
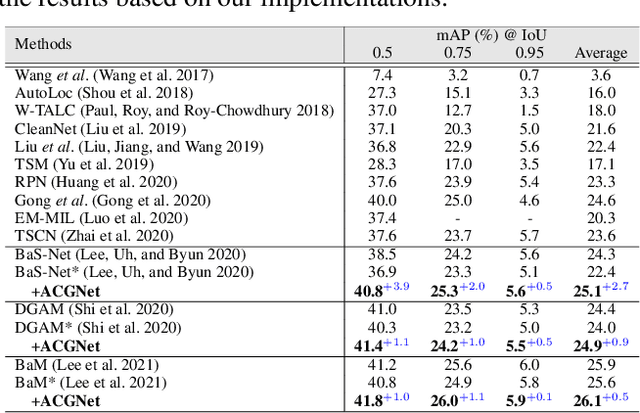
Weakly-supervised temporal action localization (WTAL) in untrimmed videos has emerged as a practical but challenging task since only video-level labels are available. Existing approaches typically leverage off-the-shelf segment-level features, which suffer from spatial incompleteness and temporal incoherence, thus limiting their performance. In this paper, we tackle this problem from a new perspective by enhancing segment-level representations with a simple yet effective graph convolutional network, namely action complement graph network (ACGNet). It facilitates the current video segment to perceive spatial-temporal dependencies from others that potentially convey complementary clues, implicitly mitigating the negative effects caused by the two issues above. By this means, the segment-level features are more discriminative and robust to spatial-temporal variations, contributing to higher localization accuracies. More importantly, the proposed ACGNet works as a universal module that can be flexibly plugged into different WTAL frameworks, while maintaining the end-to-end training fashion. Extensive experiments are conducted on the THUMOS'14 and ActivityNet1.2 benchmarks, where the state-of-the-art results clearly demonstrate the superiority of the proposed approach.
BlockQNN: Efficient Block-wise Neural Network Architecture Generation
Aug 16, 2018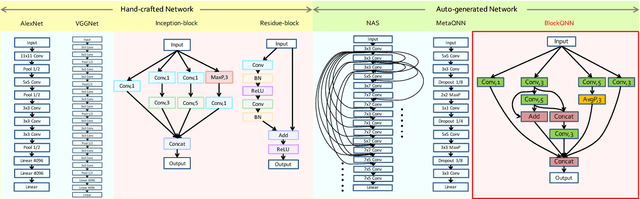
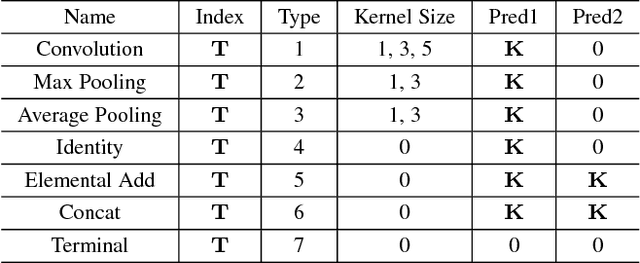
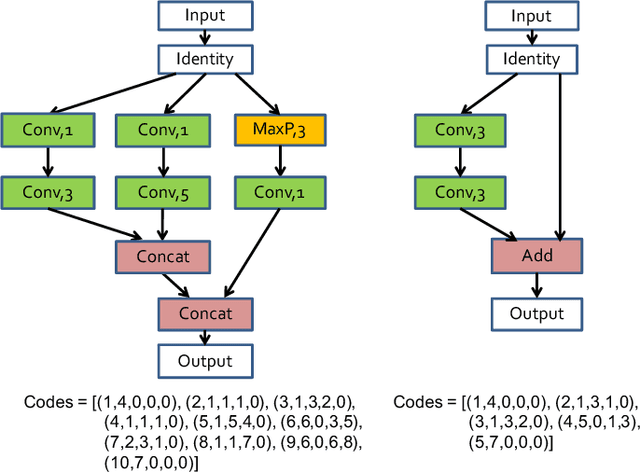

Convolutional neural networks have gained a remarkable success in computer vision. However, most usable network architectures are hand-crafted and usually require expertise and elaborate design. In this paper, we provide a block-wise network generation pipeline called BlockQNN which automatically builds high-performance networks using the Q-Learning paradigm with epsilon-greedy exploration strategy. The optimal network block is constructed by the learning agent which is trained to choose component layers sequentially. We stack the block to construct the whole auto-generated network. To accelerate the generation process, we also propose a distributed asynchronous framework and an early stop strategy. The block-wise generation brings unique advantages: (1) it yields state-of-the-art results in comparison to the hand-crafted networks on image classification, particularly, the best network generated by BlockQNN achieves 2.35% top-1 error rate on CIFAR-10. (2) it offers tremendous reduction of the search space in designing networks, spending only 3 days with 32 GPUs. A faster version can yield a comparable result with only 1 GPU in 20 hours. (3) it has strong generalizability in that the network built on CIFAR also performs well on the larger-scale dataset. The best network achieves very competitive accuracy of 82.0% top-1 and 96.0% top-5 on ImageNet.
Deep Rotation Equivariant Network
Feb 28, 2018



Recently, learning equivariant representations has attracted considerable research attention. Dieleman et al. introduce four operations which can be inserted into convolutional neural network to learn deep representations equivariant to rotation. However, feature maps should be copied and rotated four times in each layer in their approach, which causes much running time and memory overhead. In order to address this problem, we propose Deep Rotation Equivariant Network consisting of cycle layers, isotonic layers and decycle layers. Our proposed layers apply rotation transformation on filters rather than feature maps, achieving a speed up of more than 2 times with even less memory overhead. We evaluate DRENs on Rotated MNIST and CIFAR-10 datasets and demonstrate that it can improve the performance of state-of-the-art architectures.
On the Diversity of Realistic Image Synthesis
Dec 20, 2017


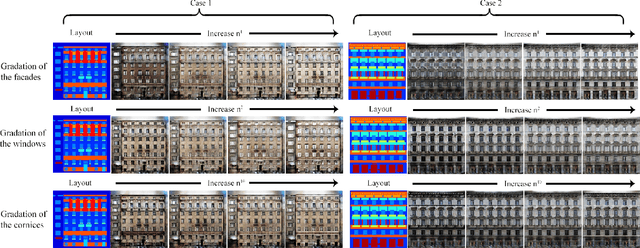
Many image processing tasks can be formulated as translating images between two image domains, such as colorization, super resolution and conditional image synthesis. In most of these tasks, an input image may correspond to multiple outputs. However, current existing approaches only show very minor diversity of the outputs. In this paper, we present a novel approach to synthesize diverse realistic images corresponding to a semantic layout. We introduce a diversity loss objective, which maximizes the distance between synthesized image pairs and links the input noise to the semantic segments in the synthesized images. Thus, our approach can not only produce diverse images, but also allow users to manipulate the output images by adjusting the noise manually. Experimental results show that images synthesized by our approach are significantly more diverse than that of the current existing works and equipping our diversity loss does not degrade the reality of the base networks.