 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning for Multi-Model and Multi-Type Fitting
Jan 29, 2019

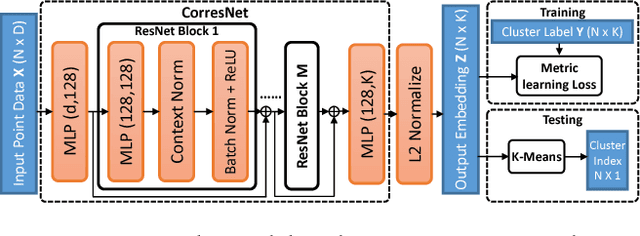
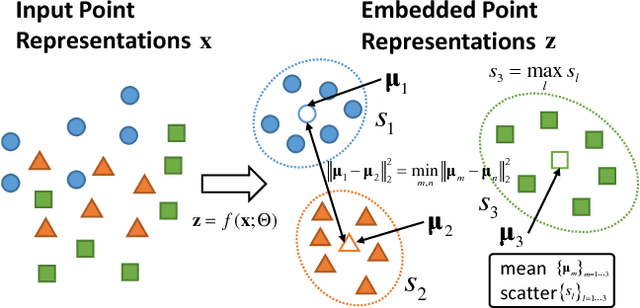
Multi-model fitting has been extensively studied from the random sampling and clustering perspectives. Most assume that only a single type/class of model is present and their generalizations to fitting multiple types of models/structures simultaneously are non-trivial. The inherent challenges include choice of types and numbers of models, sampling imbalance and parameter tuning, all of which render conventional approaches ineffective. In this work, we formulate the multi-model multi-type fitting problem as one of learning deep feature embedding that is clustering-friendly. In other words, points of the same clusters are embedded closer together through the network. For inference, we apply K-means to cluster the data in the embedded feature space and model selection is enabled by analyzing the K-means residuals. Experiments are carried out on both synthetic and real world multi-type fitting datasets, producing state-of-the-art results. Comparisons are also made on single-type multi-model fitting tasks with promising results as well.
Combinatorial Optimization with Graph Convolutional Networks and Guided Tree Search
Oct 25, 2018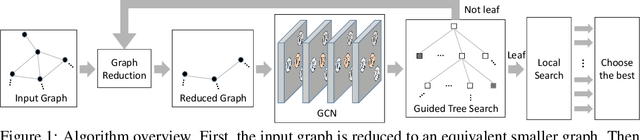
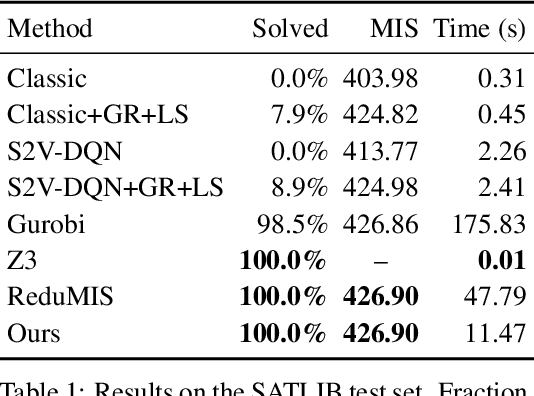
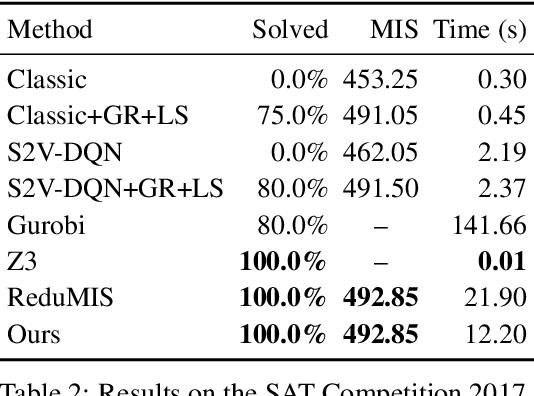
We present a learning-based approach to computing solutions for certain NP-hard problems. Our approach combines deep learning techniques with useful algorithmic elements from classic heuristics. The central component is a graph convolutional network that is trained to estimate the likelihood, for each vertex in a graph, of whether this vertex is part of the optimal solution. The network is designed and trained to synthesize a diverse set of solutions, which enables rapid exploration of the solution space via tree search. The presented approach is evaluated on four canonical NP-hard problems and five datasets, which include benchmark satisfiability problems and real social network graphs with up to a hundred thousand nodes. Experimental results demonstrate that the presented approach substantially outperforms recent deep learning work, and performs on par with highly optimized state-of-the-art heuristic solvers for some NP-hard problems. Experiments indicate that our approach generalizes across datasets, and scales to graphs that are orders of magnitude larger than those used during training.
Pixel2Mesh: Generating 3D Mesh Models from Single RGB Images
Aug 03, 2018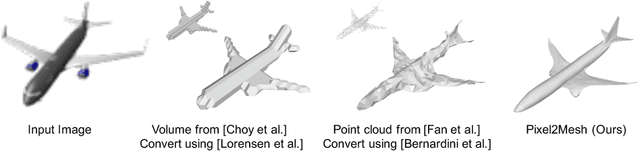
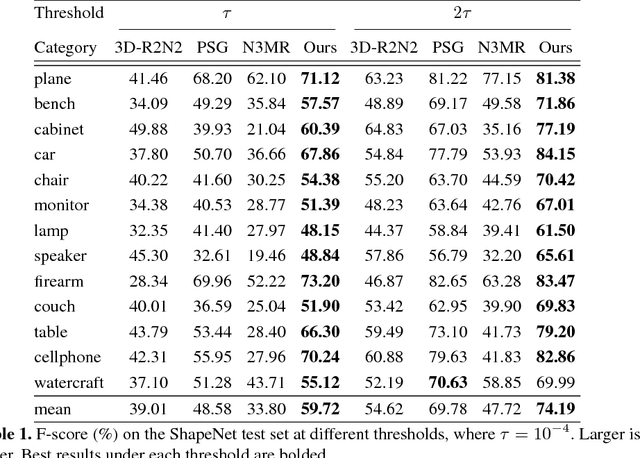
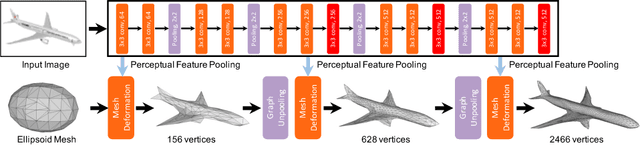
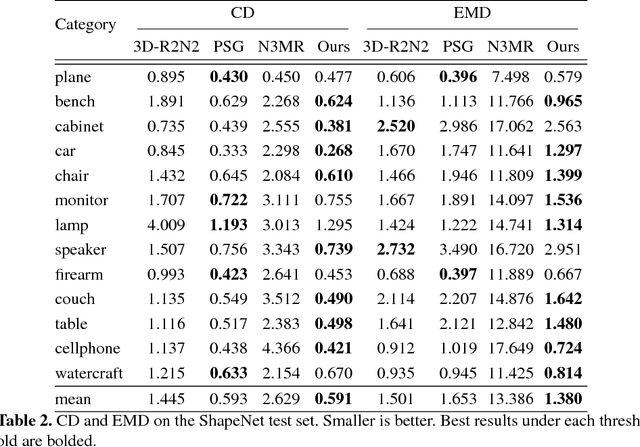
We propose an end-to-end deep learning architecture that produces a 3D shape in triangular mesh from a single color image. Limited by the nature of deep neural network, previous methods usually represent a 3D shape in volume or point cloud, and it is non-trivial to convert them to the more ready-to-use mesh model. Unlike the existing methods, our network represents 3D mesh in a graph-based convolutional neural network and produces correct geometry by progressively deforming an ellipsoid, leveraging perceptual features extracted from the input image. We adopt a coarse-to-fine strategy to make the whole deformation procedure stable, and define various of mesh related losses to capture properties of different levels to guarantee visually appealing and physically accurate 3D geometry. Extensive experiments show that our method not only qualitatively produces mesh model with better details, but also achieves higher 3D shape estimation accuracy compared to the state-of-the-art.
Motion Segmentation by Exploiting Complementary Geometric Models
Apr 06, 2018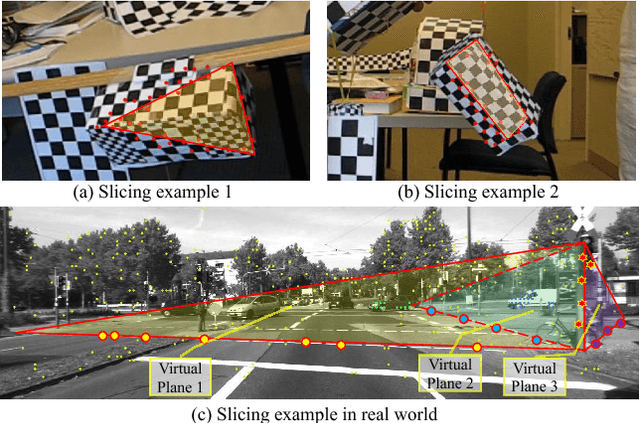
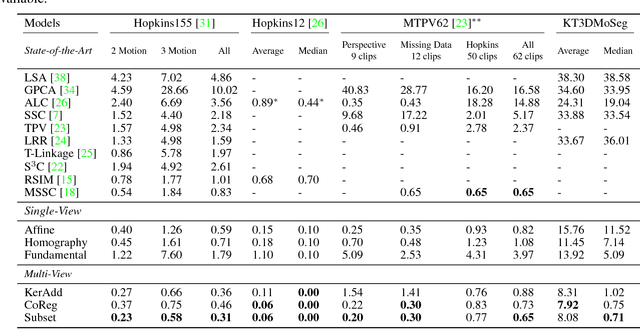
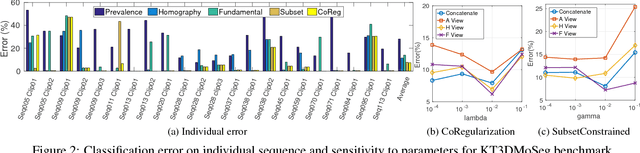

Many real-world sequences cannot be conveniently categorized as general or degenerate; in such cases, imposing a false dichotomy in using the fundamental matrix or homography model for motion segmentation would lead to difficulty. Even when we are confronted with a general scene-motion, the fundamental matrix approach as a model for motion segmentation still suffers from several defects, which we discuss in this paper. The full potential of the fundamental matrix approach could only be realized if we judiciously harness information from the simpler homography model. From these considerations, we propose a multi-view spectral clustering framework that synergistically combines multiple models together. We show that the performance can be substantially improved in this way. We perform extensive testing on existing motion segmentation datasets, achieving state-of-the-art performance on all of them; we also put forth a more realistic and challenging dataset adapted from the KITTI benchmark, containing real-world effects such as strong perspectives and strong forward translations not seen in the traditional datasets.