 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvably Efficient Generative Adversarial Imitation Learning for Online and Offline Setting with Linear Function Approximation
Aug 19, 2021In generative adversarial imitation learning (GAIL), the agent aims to learn a policy from an expert demonstration so that its performance cannot be discriminated from the expert policy on a certain predefined reward set. In this paper, we study GAIL in both online and offline settings with linear function approximation, where both the transition and reward function are linear in the feature maps. Besides the expert demonstration, in the online setting the agent can interact with the environment, while in the offline setting the agent only accesses an additional dataset collected by a prior. For online GAIL, we propose an optimistic generative adversarial policy optimization algorithm (OGAP) and prove that OGAP achieves $\widetilde{\mathcal{O}}(H^2 d^{3/2}K^{1/2}+KH^{3/2}dN_1^{-1/2})$ regret. Here $N_1$ represents the number of trajectories of the expert demonstration, $d$ is the feature dimension, and $K$ is the number of episodes. For offline GAIL, we propose a pessimistic generative adversarial policy optimization algorithm (PGAP). For an arbitrary additional dataset, we obtain the optimality gap of PGAP, achieving the minimax lower bound in the utilization of the additional dataset. Assuming sufficient coverage on the additional dataset, we show that PGAP achieves $\widetilde{\mathcal{O}}(H^{2}dK^{-1/2} +H^2d^{3/2}N_2^{-1/2}+H^{3/2}dN_1^{-1/2} \ )$ optimality gap. Here $N_2$ represents the number of trajectories of the additional dataset with sufficient coverage.
Online Bootstrap Inference For Policy Evaluation in Reinforcement Learning
Aug 08, 2021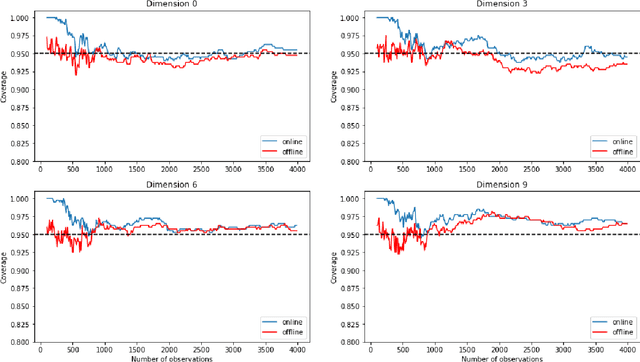
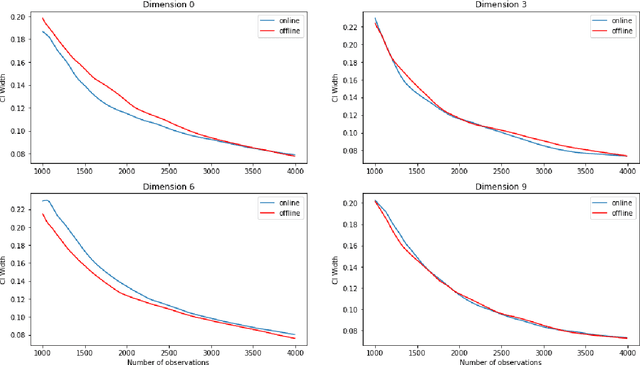
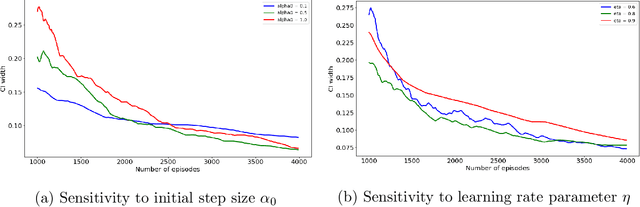
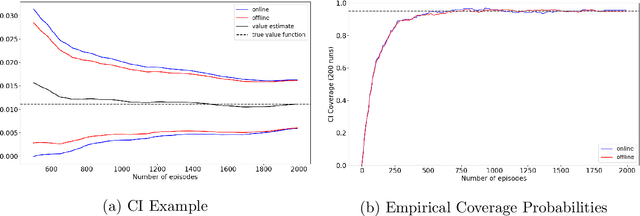
The recent emergence of reinforcement learning has created a demand for robust statistical inference methods for the parameter estimates computed using these algorithms. Existing methods for statistical inference in online learning are restricted to settings involving independently sampled observations, while existing statistical inference methods in reinforcement learning (RL) are limited to the batch setting. The online bootstrap is a flexible and efficient approach for statistical inference in linear stochastic approximation algorithms, but its efficacy in settings involving Markov noise, such as RL, has yet to be explored. In this paper, we study the use of the online bootstrap method for statistical inference in RL. In particular, we focus on the temporal difference (TD) learning and Gradient TD (GTD) learning algorithms, which are themselves special instances of linear stochastic approximation under Markov noise. The method is shown to be distributionally consistent for statistical inference in policy evaluation, and numerical experiments are included to demonstrate the effectiveness of this algorithm at statistical inference tasks across a range of real RL environments.
Towards General Function Approximation in Zero-Sum Markov Games
Jul 30, 2021This paper considers two-player zero-sum finite-horizon Markov games with simultaneous moves. The study focuses on the challenging settings where the value function or the model is parameterized by general function classes. Provably efficient algorithms for both decoupled and {coordinated} settings are developed. In the {decoupled} setting where the agent controls a single player and plays against an arbitrary opponent, we propose a new model-free algorithm. The sample complexity is governed by the Minimax Eluder dimension -- a new dimension of the function class in Markov games. As a special case, this method improves the state-of-the-art algorithm by a $\sqrt{d}$ factor in the regret when the reward function and transition kernel are parameterized with $d$-dimensional linear features. In the {coordinated} setting where both players are controlled by the agent, we propose a model-based algorithm and a model-free algorithm. In the model-based algorithm, we prove that sample complexity can be bounded by a generalization of Witness rank to Markov games. The model-free algorithm enjoys a $\sqrt{K}$-regret upper bound where $K$ is the number of episodes. Our algorithms are based on new techniques of alternate optimism.
A Unified Off-Policy Evaluation Approach for General Value Function
Jul 06, 2021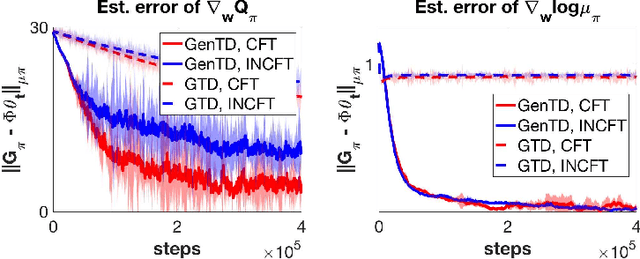
General Value Function (GVF) is a powerful tool to represent both the {\em predictive} and {\em retrospective} knowledge in reinforcement learning (RL). In practice, often multiple interrelated GVFs need to be evaluated jointly with pre-collected off-policy samples. In the literature, the gradient temporal difference (GTD) learning method has been adopted to evaluate GVFs in the off-policy setting, but such an approach may suffer from a large estimation error even if the function approximation class is sufficiently expressive. Moreover, none of the previous work have formally established the convergence guarantee to the ground truth GVFs under the function approximation settings. In this paper, we address both issues through the lens of a class of GVFs with causal filtering, which cover a wide range of RL applications such as reward variance, value gradient, cost in anomaly detection, stationary distribution gradient, etc. We propose a new algorithm called GenTD for off-policy GVFs evaluation and show that GenTD learns multiple interrelated multi-dimensional GVFs as efficiently as a single canonical scalar value function. We further show that unlike GTD, the learned GVFs by GenTD are guaranteed to converge to the ground truth GVFs as long as the function approximation power is sufficiently large. To our best knowledge, GenTD is the first off-policy GVF evaluation algorithm that has global optimality guarantee.
Gap-Dependent Bounds for Two-Player Markov Games
Jul 01, 2021As one of the most popular methods in the field of reinforcement learning, Q-learning has received increasing attention. Recently, there have been more theoretical works on the regret bound of algorithms that belong to the Q-learning class in different settings. In this paper, we analyze the cumulative regret when conducting Nash Q-learning algorithm on 2-player turn-based stochastic Markov games (2-TBSG), and propose the very first gap dependent logarithmic upper bounds in the episodic tabular setting. This bound matches the theoretical lower bound only up to a logarithmic term. Furthermore, we extend the conclusion to the discounted game setting with infinite horizon and propose a similar gap dependent logarithmic regret bound. Also, under the linear MDP assumption, we obtain another logarithmic regret for 2-TBSG, in both centralized and independent settings.
Randomized Exploration for Reinforcement Learning with General Value Function Approximation
Jun 15, 2021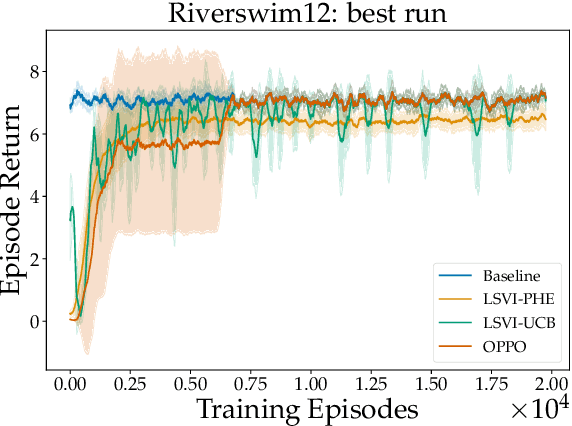
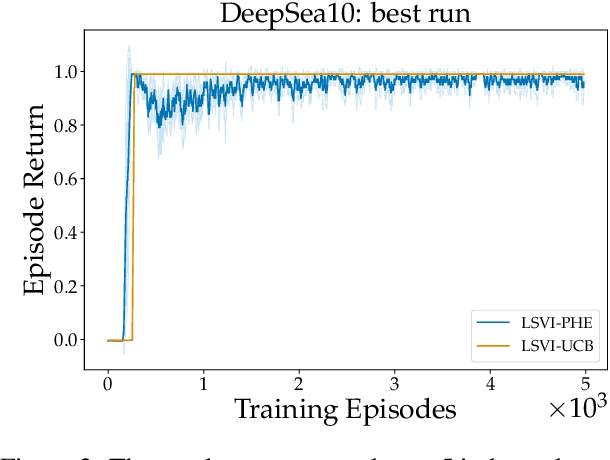
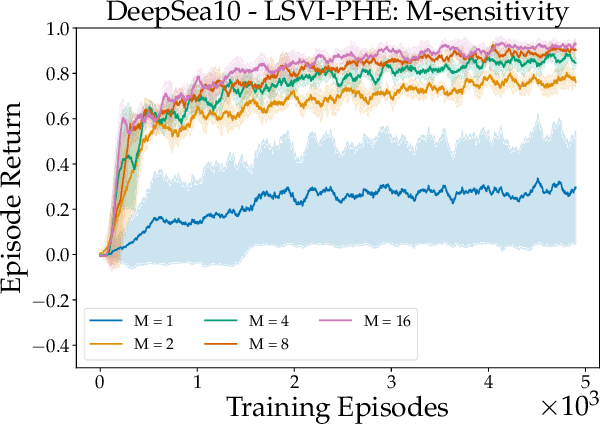
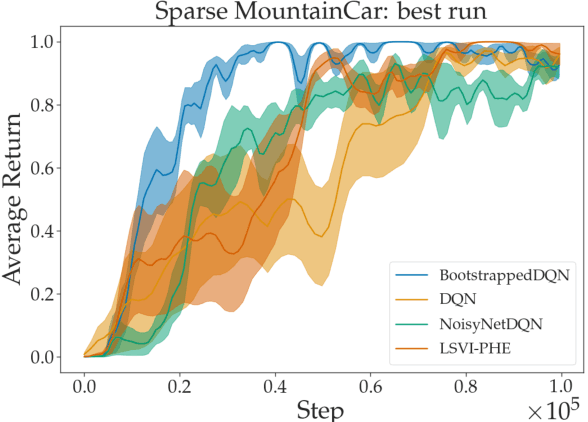
We propose a model-free reinforcement learning algorithm inspired by the popular randomized least squares value iteration (RLSVI) algorithm as well as the optimism principle. Unlike existing upper-confidence-bound (UCB) based approaches, which are often computationally intractable, our algorithm drives exploration by simply perturbing the training data with judiciously chosen i.i.d. scalar noises. To attain optimistic value function estimation without resorting to a UCB-style bonus, we introduce an optimistic reward sampling procedure. When the value functions can be represented by a function class $\mathcal{F}$, our algorithm achieves a worst-case regret bound of $\widetilde{O}(\mathrm{poly}(d_EH)\sqrt{T})$ where $T$ is the time elapsed, $H$ is the planning horizon and $d_E$ is the $\textit{eluder dimension}$ of $\mathcal{F}$. In the linear setting, our algorithm reduces to LSVI-PHE, a variant of RLSVI, that enjoys an $\widetilde{\mathcal{O}}(\sqrt{d^3H^3T})$ regret. We complement the theory with an empirical evaluation across known difficult exploration tasks.
Doubly Robust Off-Policy Actor-Critic: Convergence and Optimality
Feb 27, 2021
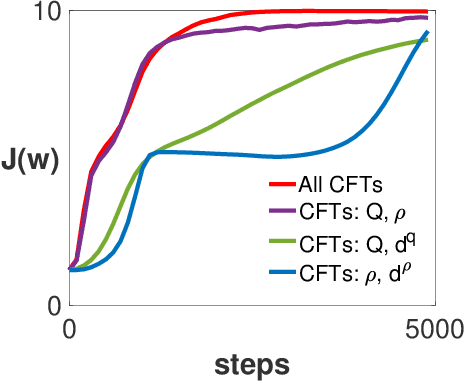
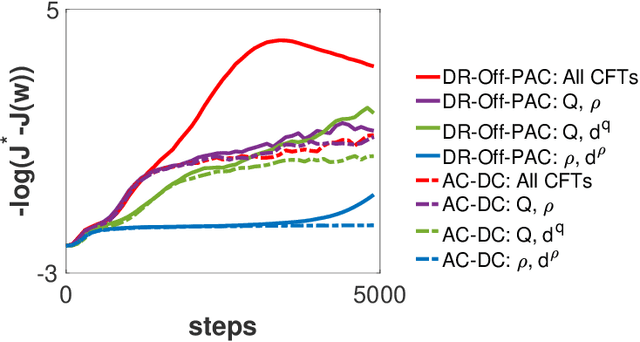
Designing off-policy reinforcement learning algorithms is typically a very challenging task, because a desirable iteration update often involves an expectation over an on-policy distribution. Prior off-policy actor-critic (AC) algorithms have introduced a new critic that uses the density ratio for adjusting the distribution mismatch in order to stabilize the convergence, but at the cost of potentially introducing high biases due to the estimation errors of both the density ratio and value function. In this paper, we develop a doubly robust off-policy AC (DR-Off-PAC) for discounted MDP, which can take advantage of learned nuisance functions to reduce estimation errors. Moreover, DR-Off-PAC adopts a single timescale structure, in which both actor and critics are updated simultaneously with constant stepsize, and is thus more sample efficient than prior algorithms that adopt either two timescale or nested-loop structure. We study the finite-time convergence rate and characterize the sample complexity for DR-Off-PAC to attain an $\epsilon$-accurate optimal policy. We also show that the overall convergence of DR-Off-PAC is doubly robust to the approximation errors that depend only on the expressive power of approximation functions. To the best of our knowledge, our study establishes the first overall sample complexity analysis for a single time-scale off-policy AC algorithm.
Instrumental Variable Value Iteration for Causal Offline Reinforcement Learning
Feb 19, 2021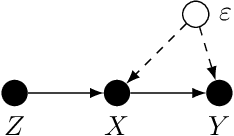
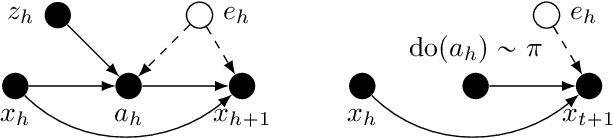
In offline reinforcement learning (RL) an optimal policy is learnt solely from a priori collected observational data. However, in observational data, actions are often confounded by unobserved variables. Instrumental variables (IVs), in the context of RL, are the variables whose influence on the state variables are all mediated through the action. When a valid instrument is present, we can recover the confounded transition dynamics through observational data. We study a confounded Markov decision process where the transition dynamics admit an additive nonlinear functional form. Using IVs, we derive a conditional moment restriction (CMR) through which we can identify transition dynamics based on observational data. We propose a provably efficient IV-aided Value Iteration (IVVI) algorithm based on a primal-dual reformulation of CMR. To the best of our knowledge, this is the first provably efficient algorithm for instrument-aided offline RL.
A Momentum-Assisted Single-Timescale Stochastic Approximation Algorithm for Bilevel Optimization
Feb 15, 2021
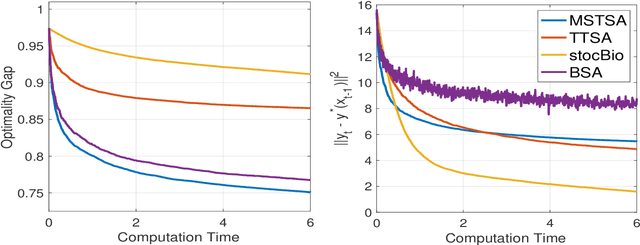
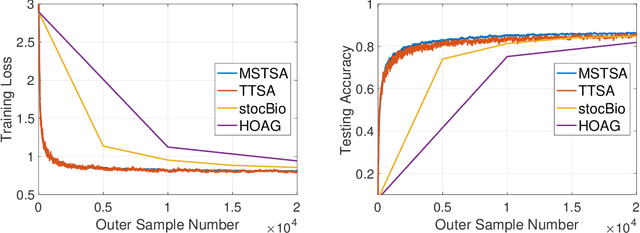

This paper proposes a new algorithm -- the Momentum-assisted Single-timescale Stochastic Approximation (MSTSA) -- for tackling unconstrained bilevel optimization problems. We focus on bilevel problems where the lower level subproblem is strongly-convex. Unlike prior works which rely on two timescale or double loop techniques that track the optimal solution to the lower level subproblem, we design a stochastic momentum assisted gradient estimator for the upper level subproblem's updates. The latter allows us to gradually control the error in stochastic gradient updates due to inaccurate solution to the lower level subproblem. We show that if the upper objective function is smooth but possibly non-convex (resp. strongly-convex), MSTSA requires $\mathcal{O}(\epsilon^{-2})$ (resp. $\mathcal{O}(\epsilon^{-1})$) iterations (each using constant samples) to find an $\epsilon$-stationary (resp. $\epsilon$-optimal) solution. This achieves the best-known guarantees for stochastic bilevel problems. We validate our theoretical results by showing the efficiency of the MSTSA algorithm on hyperparameter optimization and data hyper-cleaning problems.
Is Pessimism Provably Efficient for Offline RL?
Dec 30, 2020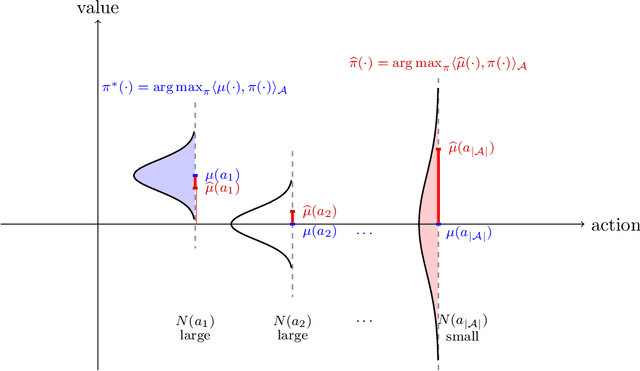
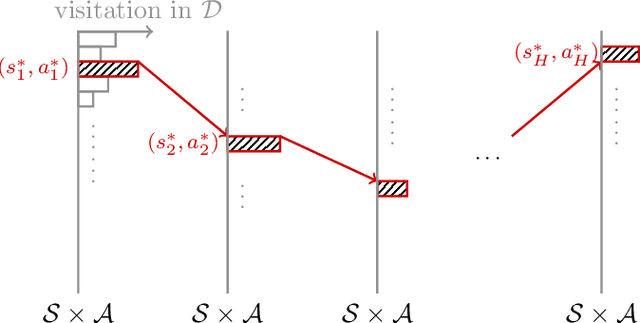
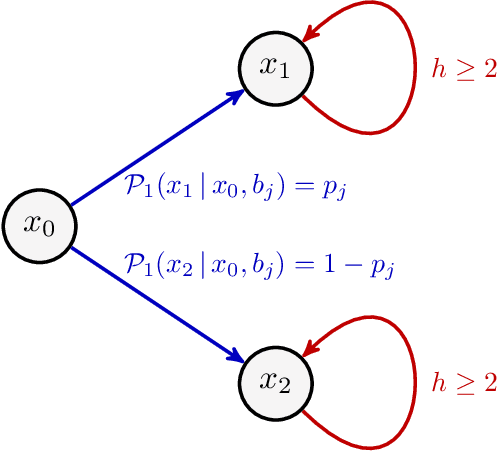
We study offline reinforcement learning (RL), which aims to learn an optimal policy based on a dataset collected a priori. Due to the lack of further interactions with the environment, offline RL suffers from the insufficient coverage of the dataset, which eludes most existing theoretical analysis. In this paper, we propose a pessimistic variant of the value iteration algorithm (PEVI), which incorporates an uncertainty quantifier as the penalty function. Such a penalty function simply flips the sign of the bonus function for promoting exploration in online RL, which makes it easily implementable and compatible with general function approximators. Without assuming the sufficient coverage of the dataset, we establish a data-dependent upper bound on the suboptimality of PEVI for general Markov decision processes (MDPs). When specialized to linear MDPs, it matches the information-theoretic lower bound up to multiplicative factors of the dimension and horizon. In other words, pessimism is not only provably efficient but also minimax optimal. In particular, given the dataset, the learned policy serves as the ``best effort'' among all policies, as no other policies can do better. Our theoretical analysis identifies the critical role of pessimism in eliminating a notion of spurious correlation, which emerges from the ``irrelevant'' trajectories that are less covered by the dataset and not informative for the optimal policy.