 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Task Requirements Writing Evaluation via Machine Reading Comprehension
Jul 15, 2021
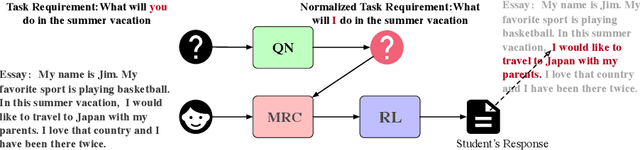
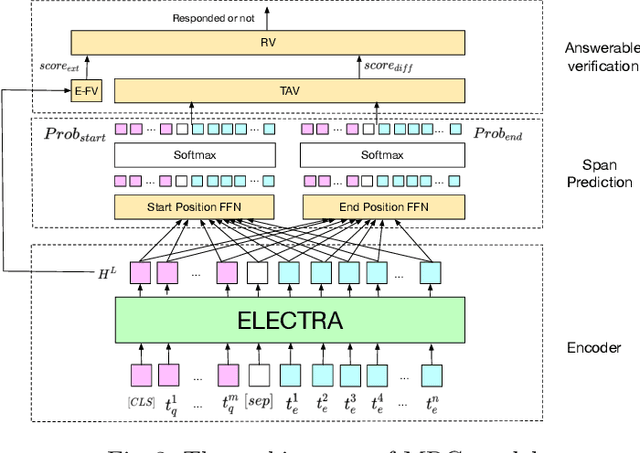
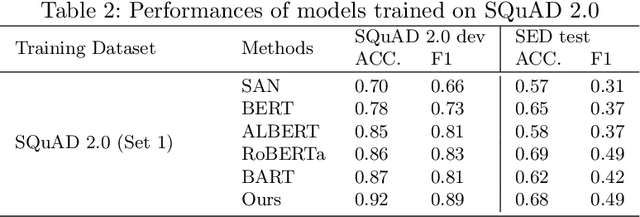
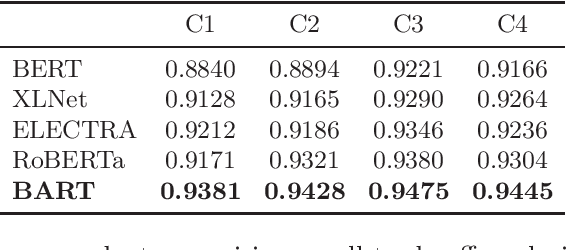
Task requirements (TRs) writing is an important question type in Key English Test and Preliminary English Test. A TR writing question may include multiple requirements and a high-quality essay must respond to each requirement thoroughly and accurately. However, the limited teacher resources prevent students from getting detailed grading instantly. The majority of existing automatic essay scoring systems focus on giving a holistic score but rarely provide reasons to support it. In this paper, we proposed an end-to-end framework based on machine reading comprehension (MRC) to address this problem to some extent. The framework not only detects whether an essay responds to a requirement question, but clearly marks where the essay answers the question. Our framework consists of three modules: question normalization module, ELECTRA based MRC module and response locating module. We extensively explore state-of-the-art MRC methods. Our approach achieves 0.93 accuracy score and 0.85 F1 score on a real-world educational dataset. To encourage reproducible results, we make our code publicly available at \url{https://github.com/aied2021TRMRC/AIED_2021_TRMRC_code}.
A Multimodal Machine Learning Framework for Teacher Vocal Delivery Evaluation
Jul 15, 2021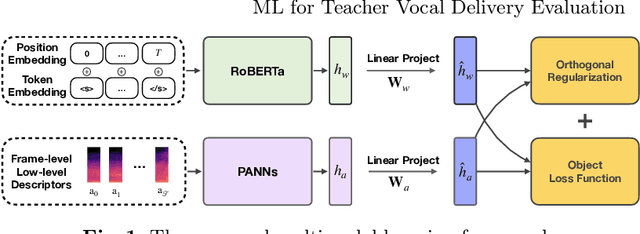
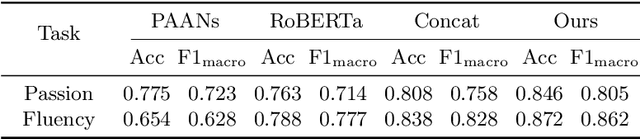
The quality of vocal delivery is one of the key indicators for evaluating teacher enthusiasm, which has been widely accepted to be connected to the overall course qualities. However, existing evaluation for vocal delivery is mainly conducted with manual ratings, which faces two core challenges: subjectivity and time-consuming. In this paper, we present a novel machine learning approach that utilizes pairwise comparisons and a multimodal orthogonal fusing algorithm to generate large-scale objective evaluation results of the teacher vocal delivery in terms of fluency and passion. We collect two datasets from real-world education scenarios and the experiment results demonstrate the effectiveness of our algorithm. To encourage reproducible results, we make our code public available at \url{https://github.com/tal-ai/ML4VocalDelivery.git}.
Solving ESL Sentence Completion Questions via Pre-trained Neural Language Models
Jul 15, 2021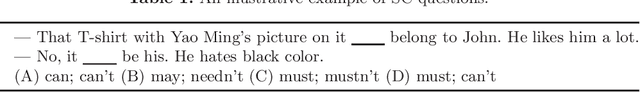
Sentence completion (SC) questions present a sentence with one or more blanks that need to be filled in, three to five possible words or phrases as options. SC questions are widely used for students learning English as a Second Language (ESL) and building computational approaches to automatically solve such questions is beneficial to language learners. In this work, we propose a neural framework to solve SC questions in English examinations by utilizing pre-trained language models. We conduct extensive experiments on a real-world K-12 ESL SC question dataset and the results demonstrate the superiority of our model in terms of prediction accuracy. Furthermore, we run precision-recall trade-off analysis to discuss the practical issues when deploying it in real-life scenarios. To encourage reproducible results, we make our code publicly available at \url{https://github.com/AIED2021/ESL-SentenceCompletion}.
Multi-Task Learning based Online Dialogic Instruction Detection with Pre-trained Language Models
Jul 15, 2021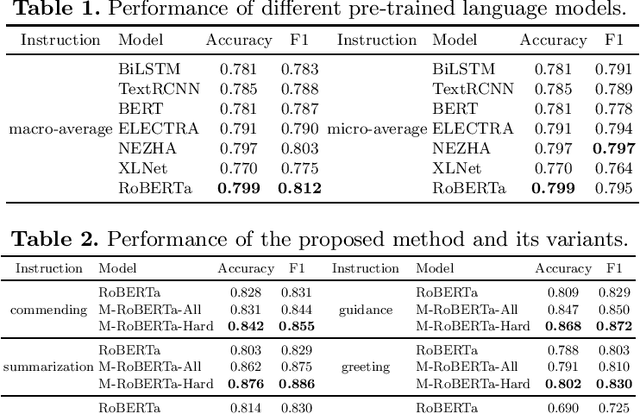
In this work, we study computational approaches to detect online dialogic instructions, which are widely used to help students understand learning materials, and build effective study habits. This task is rather challenging due to the widely-varying quality and pedagogical styles of dialogic instructions. To address these challenges, we utilize pre-trained language models, and propose a multi-task paradigm which enhances the ability to distinguish instances of different classes by enlarging the margin between categories via contrastive loss. Furthermore, we design a strategy to fully exploit the misclassified examples during the training stage. Extensive experiments on a real-world online educational data set demonstrate that our approach achieves superior performance compared to representative baselines. To encourage reproducible results, we make our implementation online available at \url{https://github.com/AIED2021/multitask-dialogic-instruction}.
Robust Learning for Text Classification with Multi-source Noise Simulation and Hard Example Mining
Jul 15, 2021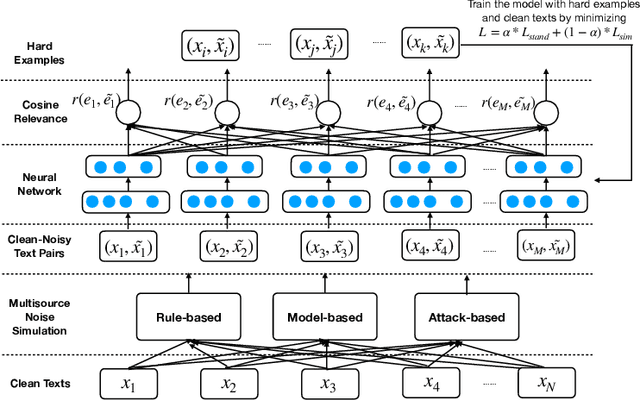
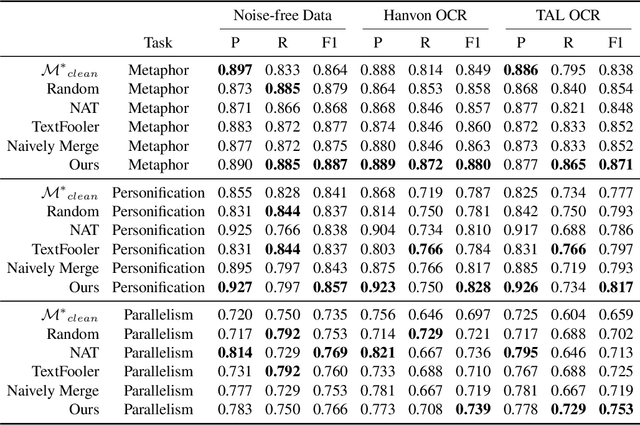
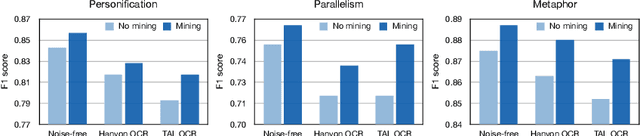
Many real-world applications involve the use of Optical Character Recognition (OCR) engines to transform handwritten images into transcripts on which downstream Natural Language Processing (NLP) models are applied. In this process, OCR engines may introduce errors and inputs to downstream NLP models become noisy. Despite that pre-trained models achieve state-of-the-art performance in many NLP benchmarks, we prove that they are not robust to noisy texts generated by real OCR engines. This greatly limits the application of NLP models in real-world scenarios. In order to improve model performance on noisy OCR transcripts, it is natural to train the NLP model on labelled noisy texts. However, in most cases there are only labelled clean texts. Since there is no handwritten pictures corresponding to the text, it is impossible to directly use the recognition model to obtain noisy labelled data. Human resources can be employed to copy texts and take pictures, but it is extremely expensive considering the size of data for model training. Consequently, we are interested in making NLP models intrinsically robust to OCR errors in a low resource manner. We propose a novel robust training framework which 1) employs simple but effective methods to directly simulate natural OCR noises from clean texts and 2) iteratively mines the hard examples from a large number of simulated samples for optimal performance. 3) To make our model learn noise-invariant representations, a stability loss is employed. Experiments on three real-world datasets show that the proposed framework boosts the robustness of pre-trained models by a large margin. We believe that this work can greatly promote the application of NLP models in actual scenarios, although the algorithm we use is simple and straightforward. We make our codes and three datasets publicly available\footnote{https://github.com/tal-ai/Robust-learning-MSSHEM}.
Towards the Memorization Effect of Neural Networks in Adversarial Training
Jun 09, 2021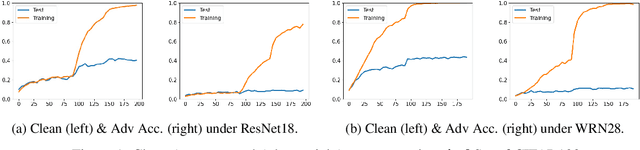

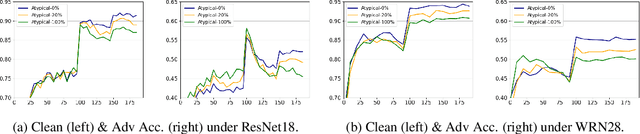
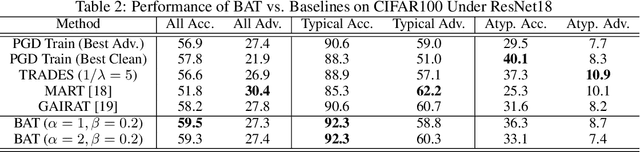
Recent studies suggest that ``memorization'' is one important factor for overparameterized deep neural networks (DNNs) to achieve optimal performance. Specifically, the perfectly fitted DNNs can memorize the labels of many atypical samples, generalize their memorization to correctly classify test atypical samples and enjoy better test performance. While, DNNs which are optimized via adversarial training algorithms can also achieve perfect training performance by memorizing the labels of atypical samples, as well as the adversarially perturbed atypical samples. However, adversarially trained models always suffer from poor generalization, with both relatively low clean accuracy and robustness on the test set. In this work, we study the effect of memorization in adversarial trained DNNs and disclose two important findings: (a) Memorizing atypical samples is only effective to improve DNN's accuracy on clean atypical samples, but hardly improve their adversarial robustness and (b) Memorizing certain atypical samples will even hurt the DNN's performance on typical samples. Based on these two findings, we propose Benign Adversarial Training (BAT) which can facilitate adversarial training to avoid fitting ``harmful'' atypical samples and fit as more ``benign'' atypical samples as possible. In our experiments, we validate the effectiveness of BAT, and show it can achieve better clean accuracy vs. robustness trade-off than baseline methods, in benchmark datasets such as CIFAR100 and Tiny~ImageNet.
Multi-Scale Attention Neural Network for Acoustic Echo Cancellation
May 31, 2021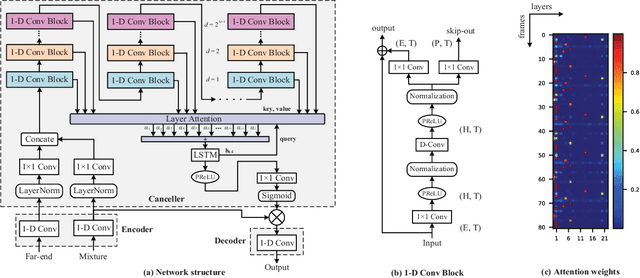
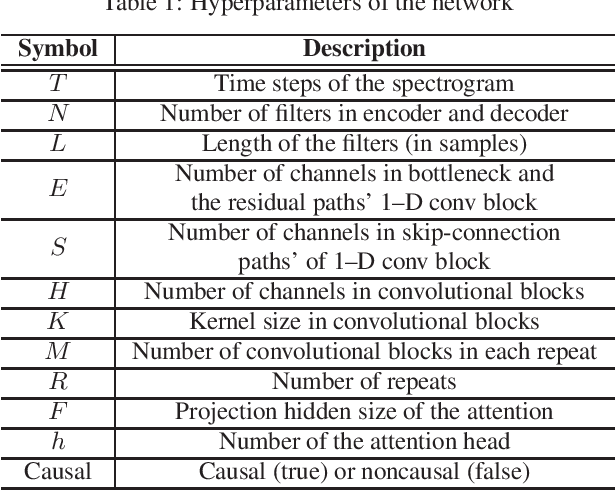
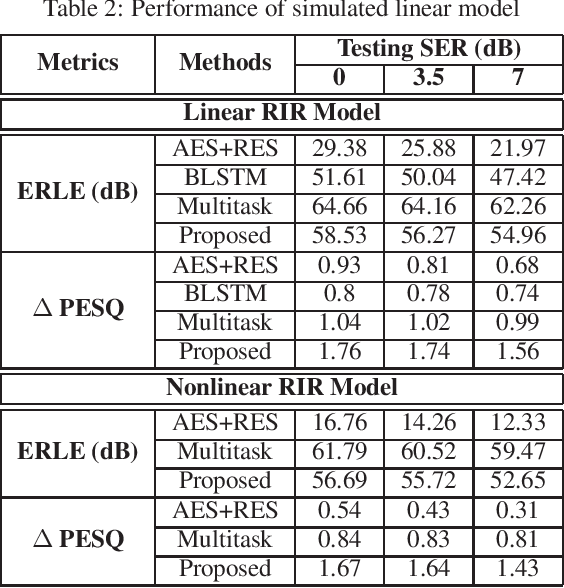
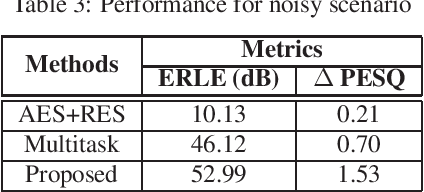
Acoustic Echo Cancellation (AEC) plays a key role in speech interaction by suppressing the echo received at microphone introduced by acoustic reverberations from loudspeakers. Since the performance of linear adaptive filter (AF) would degrade severely due to nonlinear distortions, background noises, and microphone clipping in real scenarios, deep learning has been employed for AEC for its good nonlinear modelling ability. In this paper, we constructed an end-to-end multi-scale attention neural network for AEC. Temporal convolution is first used to transform waveform into spectrogram. The spectrograms of the far-end reference and the near-end mixture are concatenated, and fed to a temporal convolution network (TCN) with stacked dilated convolution layers. Attention mechanism is performed among these representations from different layers to adaptively extract relevant features by referring to the previous hidden state in the encoder long short-term memory (LSTM) unit. The representations are weighted averaged and fed to the encoder LSTM for the near-end speech estimation. Experiments show the superiority of our method in terms of the echo return loss enhancement (ERLE) for single-talk periods and the perceptual evaluation of speech quality (PESQ) score for double-talk periods in background noise and nonlinear distortion scenarios.
Noise Classification Aided Attention-Based Neural Network for Monaural Speech Enhancement
May 31, 2021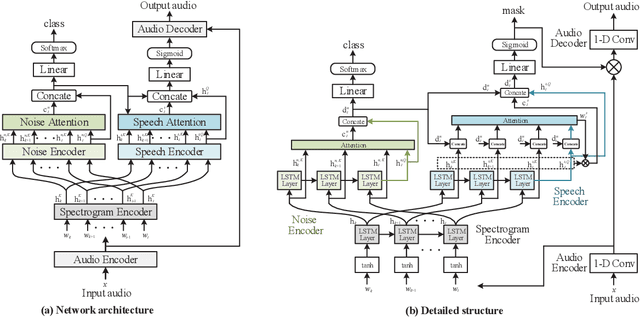
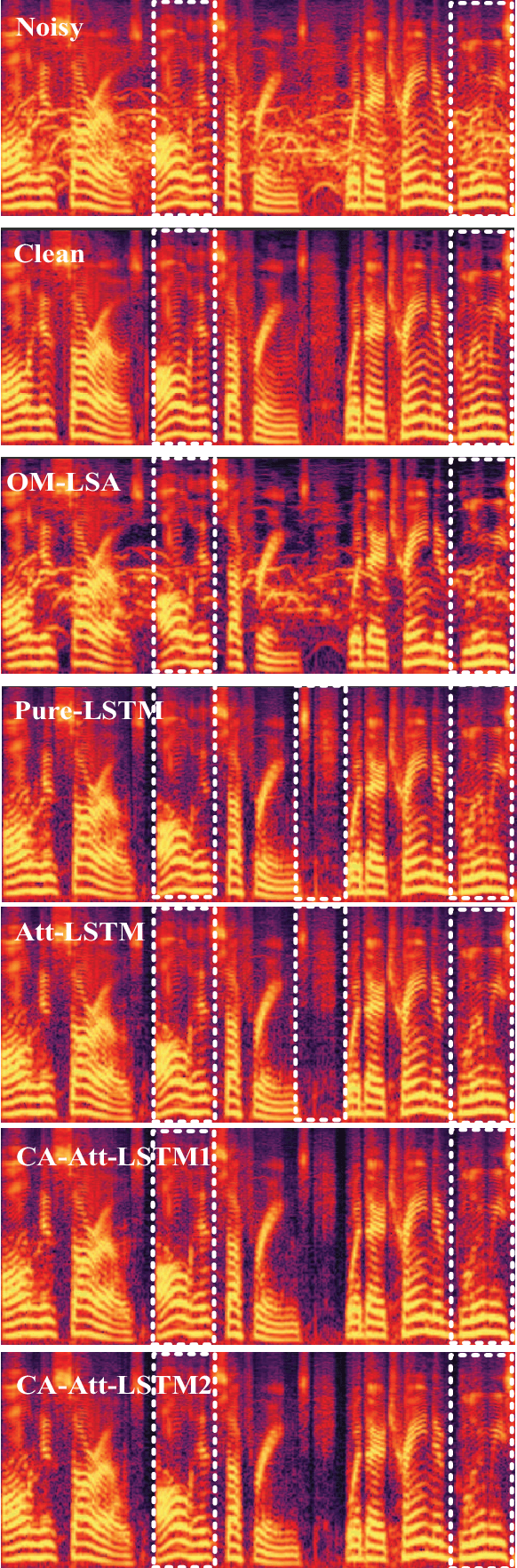
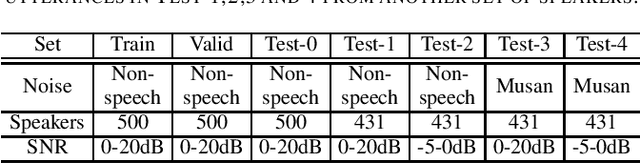

This paper proposes an noise type classification aided attention-based neural network approach for monaural speech enhancement. The network is constructed based on a previous work by introducing a noise classification subnetwork into the structure and taking the classification embedding into the attention mechanism for guiding the network to make better feature extraction. Specifically, to make the network an end-to-end way, an audio encoder and decoder constructed by temporal convolution is used to make transformation between waveform and spectrogram. Additionally, our model is composed of two long short term memory (LSTM) based encoders, two attention mechanism, a noise classifier and a speech mask generator. Experiments show that, compared with OM-LSA and the previous work, the proposed noise classification aided attention-based approach can achieve better performance in terms of speech quality (PESQ). More promisingly, our approach has better generalization ability to unseen noise conditions.
Multi-Scale Temporal Convolution Network for Classroom Voice Detection
May 31, 2021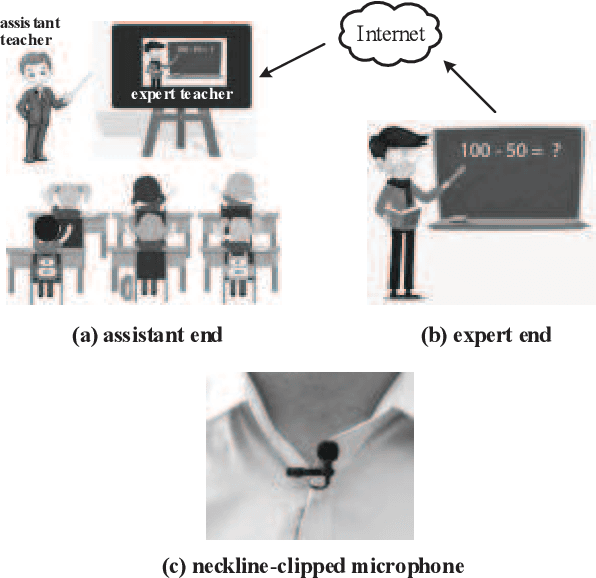
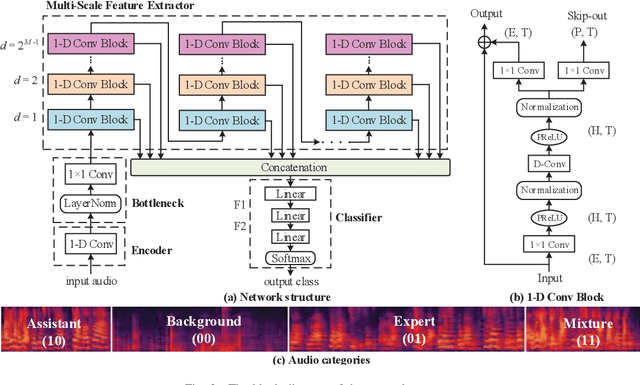
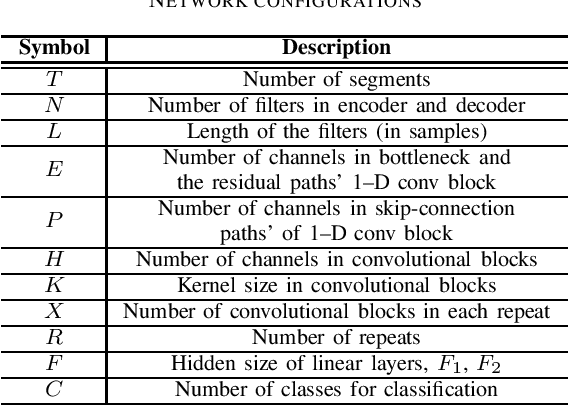
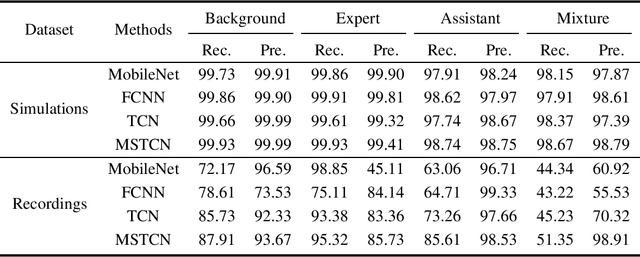
Teaching with the cooperation of expert teacher and assistant teacher, which is the so-called "double-teachers classroom", i.e., the course is giving by the expert online and presented through projection screen at the classroom, and the teacher at the classroom performs as an assistant for guiding the students in learning, is becoming more prevalent in today's teaching method for K-12 education. For monitoring the teaching quality, a microphone clipped on the assistant's neckline is always used for voice recording, then fed to the downstream tasks of automatic speech recognition (ASR) and neural language processing (NLP). However, besides its voice, there would be some other interfering voices, including the expert's one and the student's one. Here, we propose to extract the assistant' voices from the perspective of sound event detection, i.e., the voices are classified into four categories, namely the expert, the teacher, the mixture of them, and the background. To make frame-level identification, which is important for grabbing sensitive words for the downstream tasks, a multi-scale temporal convolution neural network is constructed with stacked dilated convolutions for considering both local and global properties. These features are concatenated and fed to a classification network constructed by three linear layers. The framework is evaluated on simulated data and real-world recordings, giving considerable performance in terms of precision and recall, compared with some classical classification methods.
EchoFilter: End-to-End Neural Network for Acoustic Echo Cancellation
May 31, 2021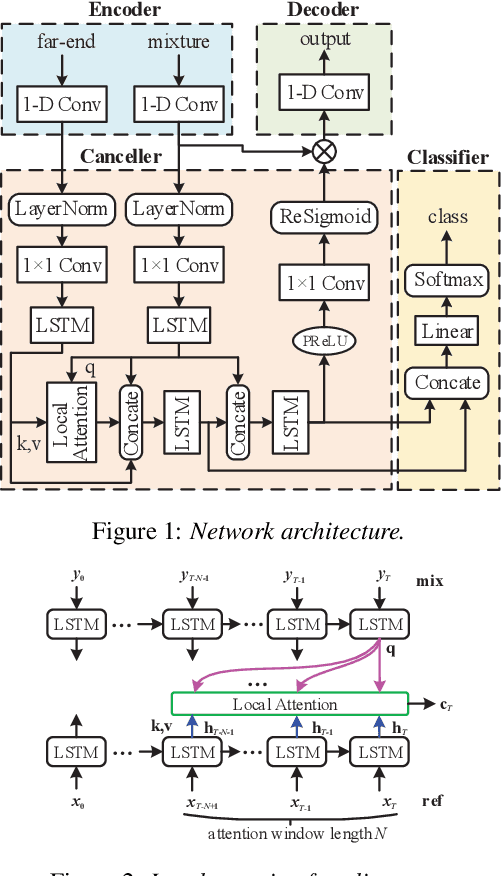

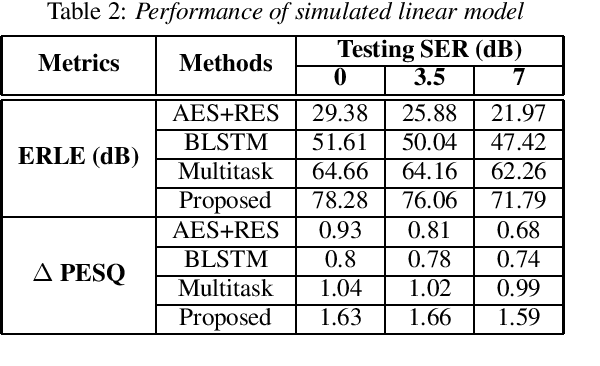
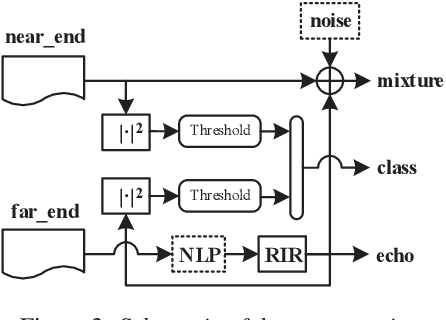
Acoustic Echo Cancellation (AEC) whose aim is to suppress the echo originated from acoustic coupling between loudspeakers and microphones, plays a key role in voice interaction. Linear adaptive filter (AF) is always used for handling this problem. However, since there would be some severe effects in real scenarios, such nonlinear distortions, background noises, and microphone clipping, it would lead to considerable residual echo, giving poor performance in practice. In this paper, we propose an end-to-end network structure for echo cancellation, which is directly done on time-domain audio waveform. It is transformed to deep representation by temporal convolution, and modelled by Long Short-Term Memory (LSTM) for considering temporal property. Since time delay and severe reverberation may exist at the near-end with respect to the far-end, a local attention is employed for alignment. The network is trained using multitask learning by employing an auxiliary classification network for double-talk detection. Experiments show the superiority of our proposed method in terms of the echo return loss enhancement (ERLE) for single-talk periods and the perceptual evaluation of speech quality (PESQ) score for double-talk periods in background noise and nonlinear distortion scenarios.