 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructural Correspondence Learning for Cross-lingual Sentiment Classification with One-to-many Mappings
Nov 26, 2016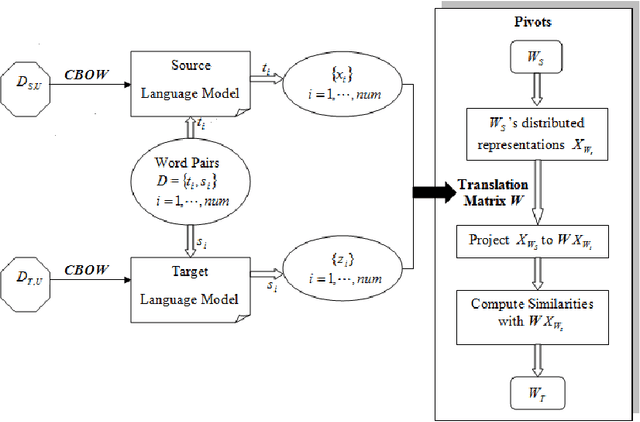
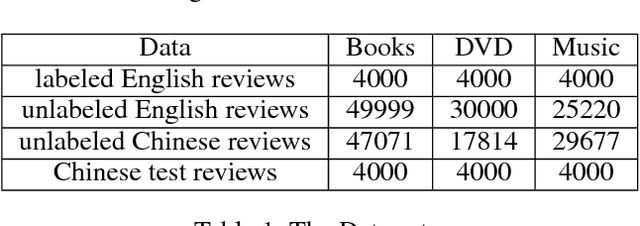
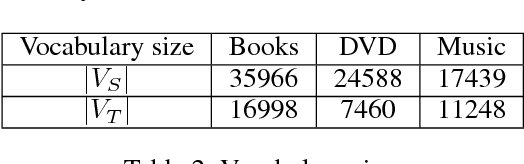
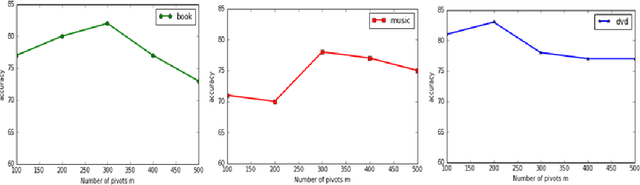
Structural correspondence learning (SCL) is an effective method for cross-lingual sentiment classification. This approach uses unlabeled documents along with a word translation oracle to automatically induce task specific, cross-lingual correspondences. It transfers knowledge through identifying important features, i.e., pivot features. For simplicity, however, it assumes that the word translation oracle maps each pivot feature in source language to exactly only one word in target language. This one-to-one mapping between words in different languages is too strict. Also the context is not considered at all. In this paper, we propose a cross-lingual SCL based on distributed representation of words; it can learn meaningful one-to-many mappings for pivot words using large amounts of monolingual data and a small dictionary. We conduct experiments on NLP\&CC 2013 cross-lingual sentiment analysis dataset, employing English as source language, and Chinese as target language. Our method does not rely on the parallel corpora and the experimental results show that our approach is more competitive than the state-of-the-art methods in cross-lingual sentiment classification.
S3Pool: Pooling with Stochastic Spatial Sampling
Nov 16, 2016
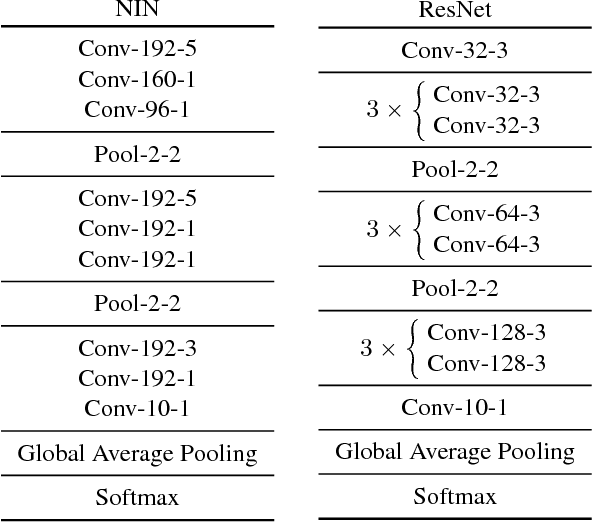
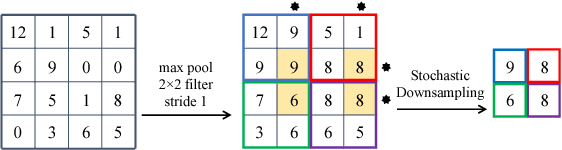
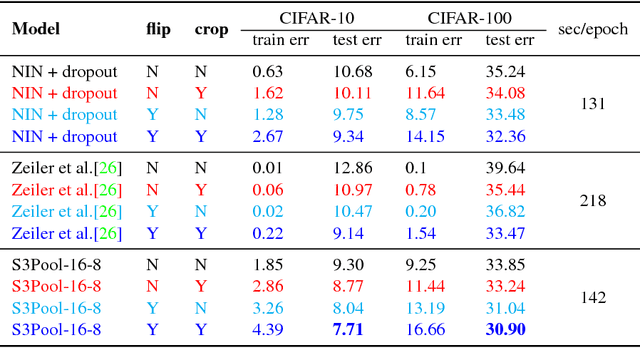
Feature pooling layers (e.g., max pooling) in convolutional neural networks (CNNs) serve the dual purpose of providing increasingly abstract representations as well as yielding computational savings in subsequent convolutional layers. We view the pooling operation in CNNs as a two-step procedure: first, a pooling window (e.g., $2\times 2$) slides over the feature map with stride one which leaves the spatial resolution intact, and second, downsampling is performed by selecting one pixel from each non-overlapping pooling window in an often uniform and deterministic (e.g., top-left) manner. Our starting point in this work is the observation that this regularly spaced downsampling arising from non-overlapping windows, although intuitive from a signal processing perspective (which has the goal of signal reconstruction), is not necessarily optimal for \emph{learning} (where the goal is to generalize). We study this aspect and propose a novel pooling strategy with stochastic spatial sampling (S3Pool), where the regular downsampling is replaced by a more general stochastic version. We observe that this general stochasticity acts as a strong regularizer, and can also be seen as doing implicit data augmentation by introducing distortions in the feature maps. We further introduce a mechanism to control the amount of distortion to suit different datasets and architectures. To demonstrate the effectiveness of the proposed approach, we perform extensive experiments on several popular image classification benchmarks, observing excellent improvements over baseline models. Experimental code is available at https://github.com/Shuangfei/s3pool.
Generative Adversarial Networks as Variational Training of Energy Based Models
Nov 06, 2016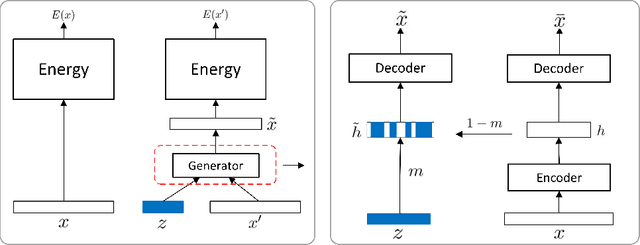


In this paper, we study deep generative models for effective unsupervised learning. We propose VGAN, which works by minimizing a variational lower bound of the negative log likelihood (NLL) of an energy based model (EBM), where the model density $p(\mathbf{x})$ is approximated by a variational distribution $q(\mathbf{x})$ that is easy to sample from. The training of VGAN takes a two step procedure: given $p(\mathbf{x})$, $q(\mathbf{x})$ is updated to maximize the lower bound; $p(\mathbf{x})$ is then updated one step with samples drawn from $q(\mathbf{x})$ to decrease the lower bound. VGAN is inspired by the generative adversarial networks (GANs), where $p(\mathbf{x})$ corresponds to the discriminator and $q(\mathbf{x})$ corresponds to the generator, but with several notable differences. We hence name our model variational GANs (VGANs). VGAN provides a practical solution to training deep EBMs in high dimensional space, by eliminating the need of MCMC sampling. From this view, we are also able to identify causes to the difficulty of training GANs and propose viable solutions. \footnote{Experimental code is available at https://github.com/Shuangfei/vgan}
Doubly Convolutional Neural Networks
Oct 30, 2016
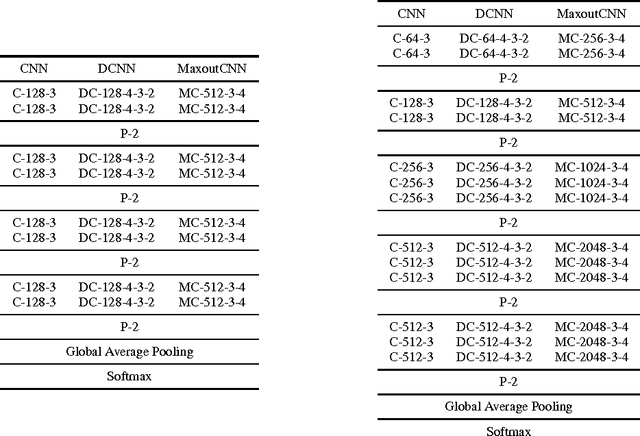

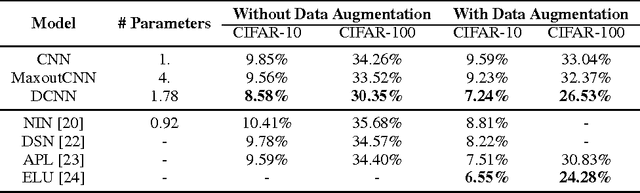
Building large models with parameter sharing accounts for most of the success of deep convolutional neural networks (CNNs). In this paper, we propose doubly convolutional neural networks (DCNNs), which significantly improve the performance of CNNs by further exploring this idea. In stead of allocating a set of convolutional filters that are independently learned, a DCNN maintains groups of filters where filters within each group are translated versions of each other. Practically, a DCNN can be easily implemented by a two-step convolution procedure, which is supported by most modern deep learning libraries. We perform extensive experiments on three image classification benchmarks: CIFAR-10, CIFAR-100 and ImageNet, and show that DCNNs consistently outperform other competing architectures. We have also verified that replacing a convolutional layer with a doubly convolutional layer at any depth of a CNN can improve its performance. Moreover, various design choices of DCNNs are demonstrated, which shows that DCNN can serve the dual purpose of building more accurate models and/or reducing the memory footprint without sacrificing the accuracy.
Zero-Shot Learning with Multi-Battery Factor Analysis
Jun 30, 2016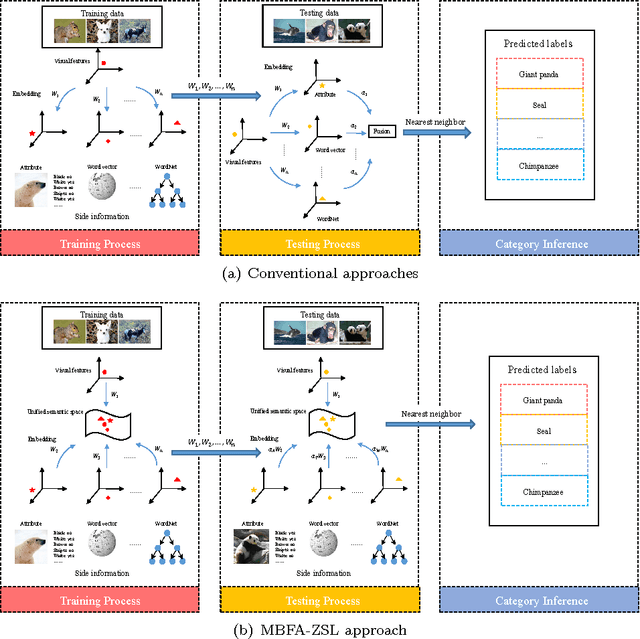
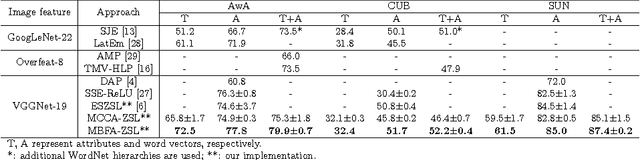


Zero-shot learning (ZSL) extends the conventional image classification technique to a more challenging situation where the test image categories are not seen in the training samples. Most studies on ZSL utilize side information such as attributes or word vectors to bridge the relations between the seen classes and the unseen classes. However, existing approaches on ZSL typically exploit a shared space for each type of side information independently, which cannot make full use of the complementary knowledge of different types of side information. To this end, this paper presents an MBFA-ZSL approach to embed different types of side information as well as the visual feature into one shared space. Specifically, we first develop an algorithm named Multi-Battery Factor Analysis (MBFA) to build a unified semantic space, and then employ multiple types of side information in it to achieve the ZSL. The close-form solution makes MBFA-ZSL simple to implement and efficient to run on large datasets. Extensive experiments on the popular AwA, CUB, and SUN datasets show its significant superiority over the state-of-the-art approaches.
Deep Structured Energy Based Models for Anomaly Detection
Jun 16, 2016
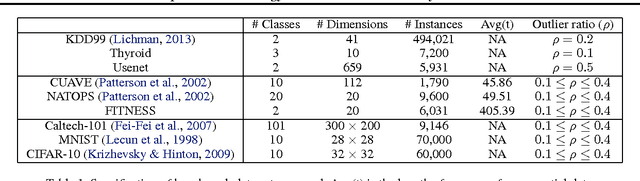
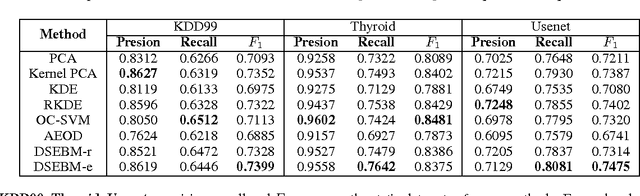
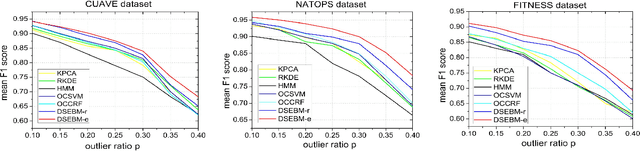
In this paper, we attack the anomaly detection problem by directly modeling the data distribution with deep architectures. We propose deep structured energy based models (DSEBMs), where the energy function is the output of a deterministic deep neural network with structure. We develop novel model architectures to integrate EBMs with different types of data such as static data, sequential data, and spatial data, and apply appropriate model architectures to adapt to the data structure. Our training algorithm is built upon the recent development of score matching \cite{sm}, which connects an EBM with a regularized autoencoder, eliminating the need for complicated sampling method. Statistically sound decision criterion can be derived for anomaly detection purpose from the perspective of the energy landscape of the data distribution. We investigate two decision criteria for performing anomaly detection: the energy score and the reconstruction error. Extensive empirical studies on benchmark tasks demonstrate that our proposed model consistently matches or outperforms all the competing methods.
Deep Learning Driven Visual Path Prediction from a Single Image
Jan 27, 2016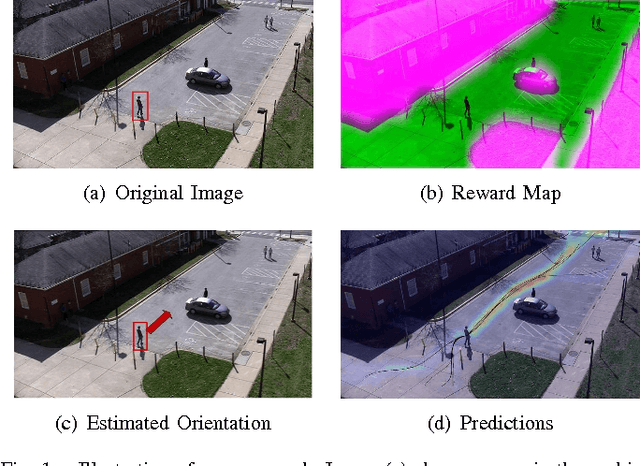
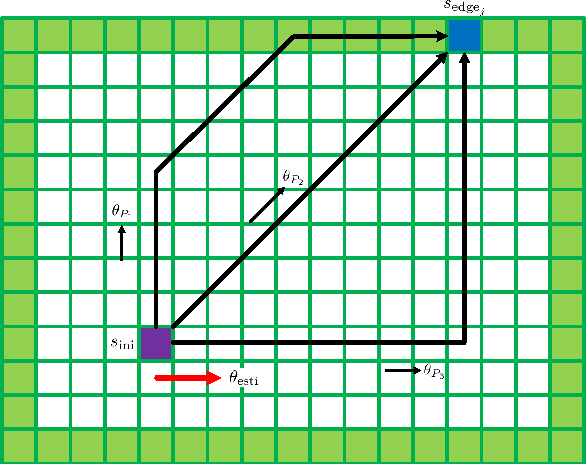
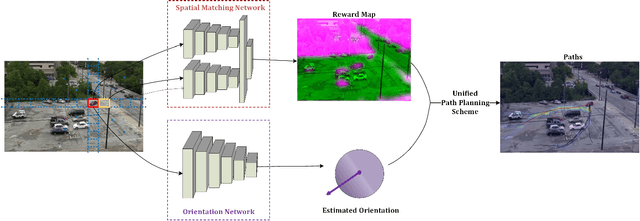
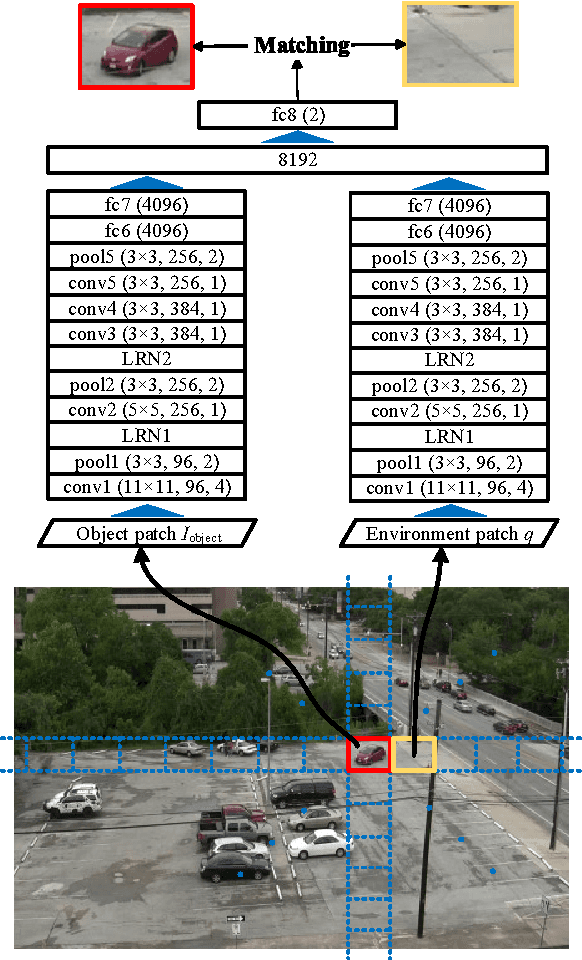
Capabilities of inference and prediction are significant components of visual systems. In this paper, we address an important and challenging task of them: visual path prediction. Its goal is to infer the future path for a visual object in a static scene. This task is complicated as it needs high-level semantic understandings of both the scenes and motion patterns underlying video sequences. In practice, cluttered situations have also raised higher demands on the effectiveness and robustness of the considered models. Motivated by these observations, we propose a deep learning framework which simultaneously performs deep feature learning for visual representation in conjunction with spatio-temporal context modeling. After that, we propose a unified path planning scheme to make accurate future path prediction based on the analytic results of the context models. The highly effective visual representation and deep context models ensure that our framework makes a deep semantic understanding of the scene and motion pattern, consequently improving the performance of the visual path prediction task. In order to comprehensively evaluate the model's performance on the visual path prediction task, we construct two large benchmark datasets from the adaptation of video tracking datasets. The qualitative and quantitative experimental results show that our approach outperforms the existing approaches and owns a better generalization capability.
Manifold Regularized Discriminative Neural Networks
Jan 07, 2016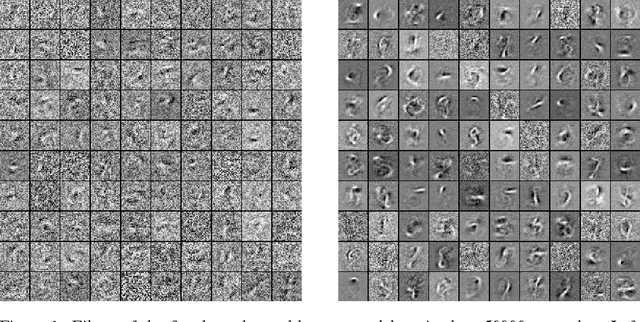
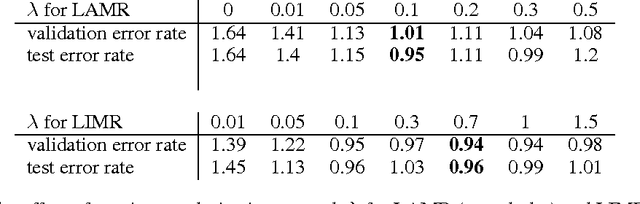
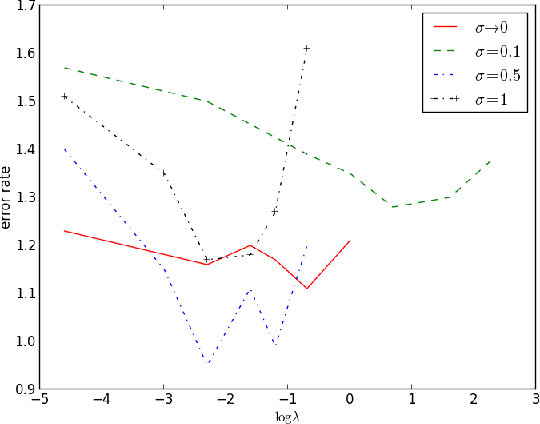

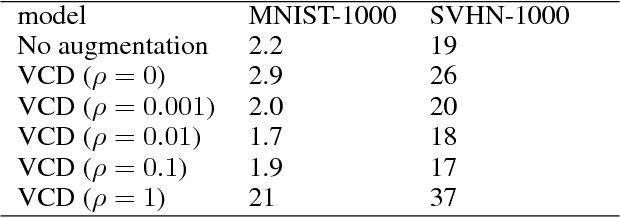
Unregularized deep neural networks (DNNs) can be easily overfit with a limited sample size. We argue that this is mostly due to the disriminative nature of DNNs which directly model the conditional probability (or score) of labels given the input. The ignorance of input distribution makes DNNs difficult to generalize to unseen data. Recent advances in regularization techniques, such as pretraining and dropout, indicate that modeling input data distribution (either explicitly or implicitly) greatly improves the generalization ability of a DNN. In this work, we explore the manifold hypothesis which assumes that instances within the same class lie in a smooth manifold. We accordingly propose two simple regularizers to a standard discriminative DNN. The first one, named Label-Aware Manifold Regularization, assumes the availability of labels and penalizes large norms of the loss function w.r.t. data points. The second one, named Label-Independent Manifold Regularization, does not use label information and instead penalizes the Frobenius norm of the Jacobian matrix of prediction scores w.r.t. data points, which makes semi-supervised learning possible. We perform extensive control experiments on fully supervised and semi-supervised tasks using the MNIST, CIFAR10 and SVHN datasets and achieve excellent results.
Dropout Training of Matrix Factorization and Autoencoder for Link Prediction in Sparse Graphs
Dec 14, 2015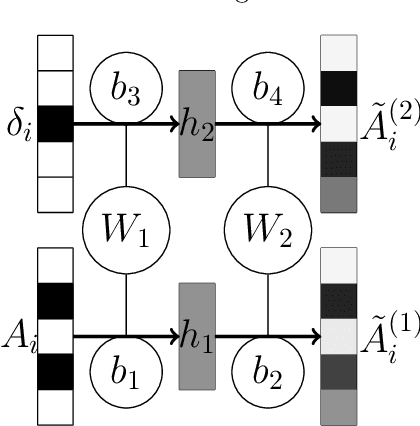
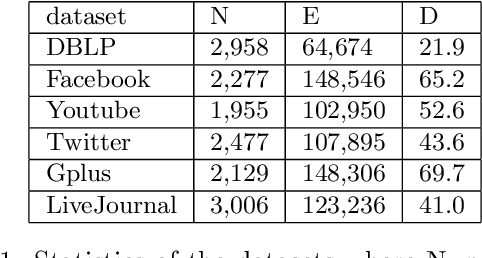
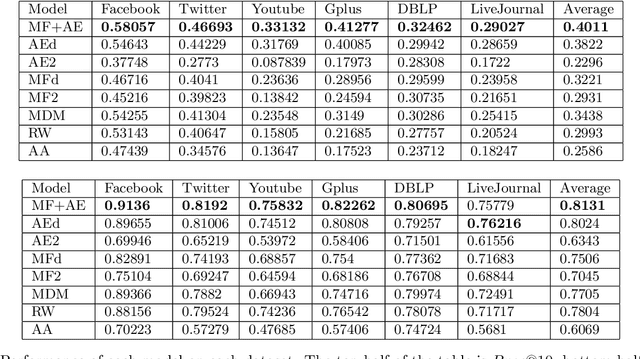
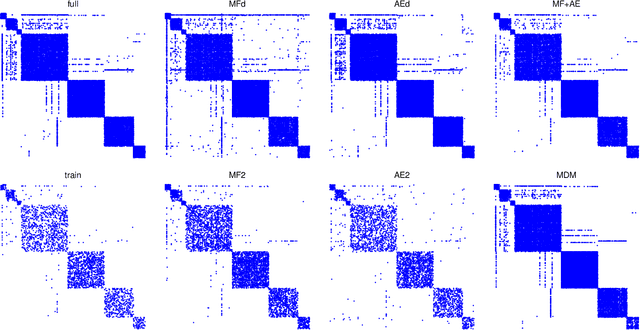
Matrix factorization (MF) and Autoencoder (AE) are among the most successful approaches of unsupervised learning. While MF based models have been extensively exploited in the graph modeling and link prediction literature, the AE family has not gained much attention. In this paper we investigate both MF and AE's application to the link prediction problem in sparse graphs. We show the connection between AE and MF from the perspective of multiview learning, and further propose MF+AE: a model training MF and AE jointly with shared parameters. We apply dropout to training both the MF and AE parts, and show that it can significantly prevent overfitting by acting as an adaptive regularization. We conduct experiments on six real world sparse graph datasets, and show that MF+AE consistently outperforms the competing methods, especially on datasets that demonstrate strong non-cohesive structures.
Semisupervised Autoencoder for Sentiment Analysis
Dec 14, 2015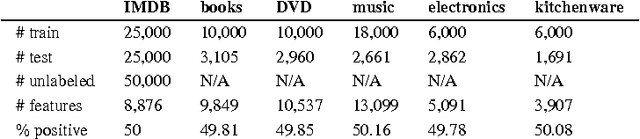
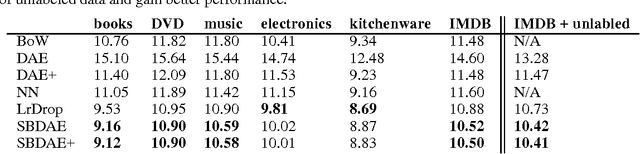
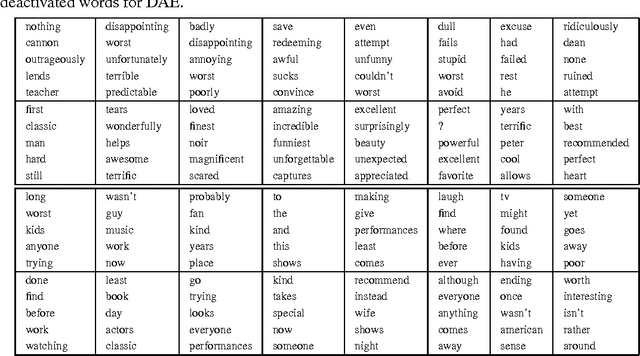
In this paper, we investigate the usage of autoencoders in modeling textual data. Traditional autoencoders suffer from at least two aspects: scalability with the high dimensionality of vocabulary size and dealing with task-irrelevant words. We address this problem by introducing supervision via the loss function of autoencoders. In particular, we first train a linear classifier on the labeled data, then define a loss for the autoencoder with the weights learned from the linear classifier. To reduce the bias brought by one single classifier, we define a posterior probability distribution on the weights of the classifier, and derive the marginalized loss of the autoencoder with Laplace approximation. We show that our choice of loss function can be rationalized from the perspective of Bregman Divergence, which justifies the soundness of our model. We evaluate the effectiveness of our model on six sentiment analysis datasets, and show that our model significantly outperforms all the competing methods with respect to classification accuracy. We also show that our model is able to take advantage of unlabeled dataset and get improved performance. We further show that our model successfully learns highly discriminative feature maps, which explains its superior performance.