 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning Driven Visual Path Prediction from a Single Image
Paper and Code
Jan 27, 2016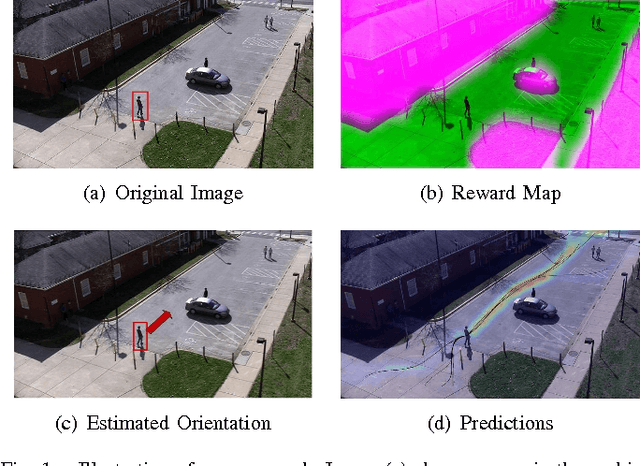
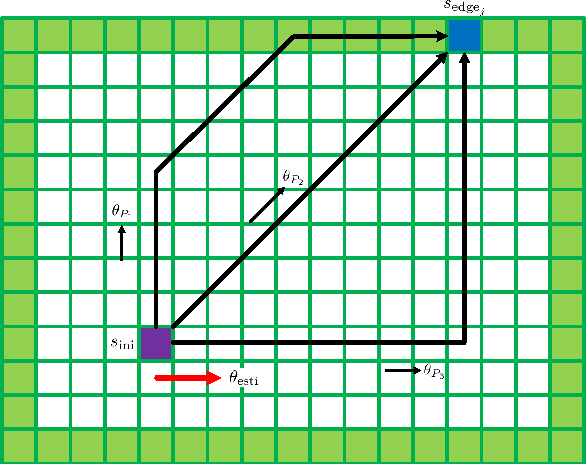
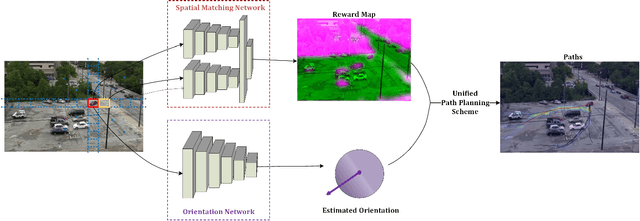
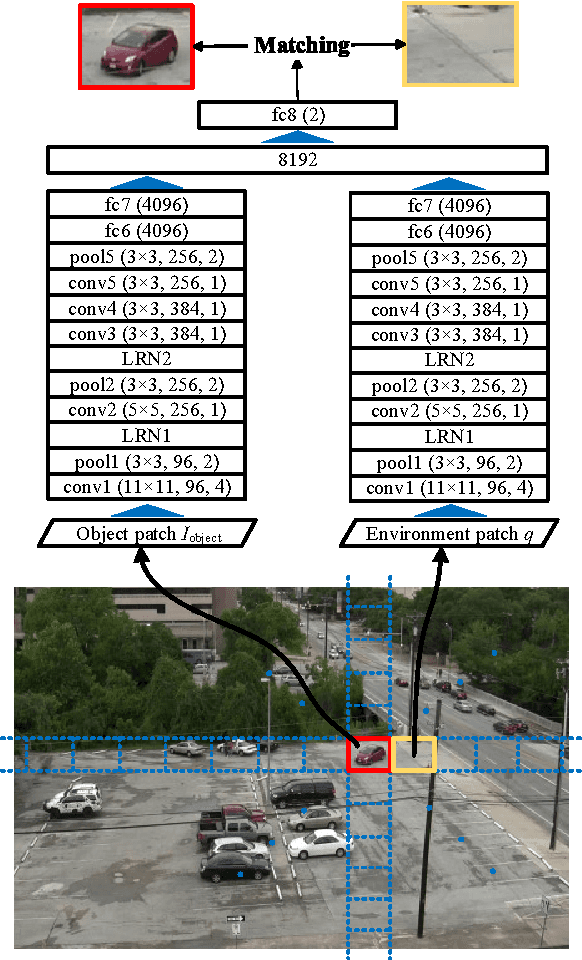
Capabilities of inference and prediction are significant components of visual systems. In this paper, we address an important and challenging task of them: visual path prediction. Its goal is to infer the future path for a visual object in a static scene. This task is complicated as it needs high-level semantic understandings of both the scenes and motion patterns underlying video sequences. In practice, cluttered situations have also raised higher demands on the effectiveness and robustness of the considered models. Motivated by these observations, we propose a deep learning framework which simultaneously performs deep feature learning for visual representation in conjunction with spatio-temporal context modeling. After that, we propose a unified path planning scheme to make accurate future path prediction based on the analytic results of the context models. The highly effective visual representation and deep context models ensure that our framework makes a deep semantic understanding of the scene and motion pattern, consequently improving the performance of the visual path prediction task. In order to comprehensively evaluate the model's performance on the visual path prediction task, we construct two large benchmark datasets from the adaptation of video tracking datasets. The qualitative and quantitative experimental results show that our approach outperforms the existing approaches and owns a better generalization capability.