 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBi-Adversarial Auto-Encoder for Zero-Shot Learning
Nov 20, 2018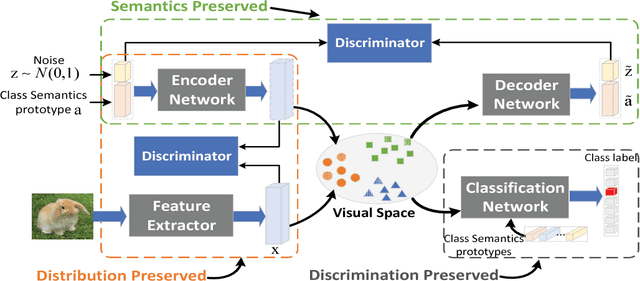
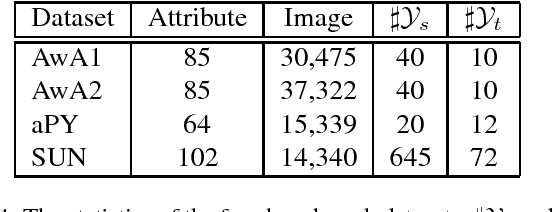
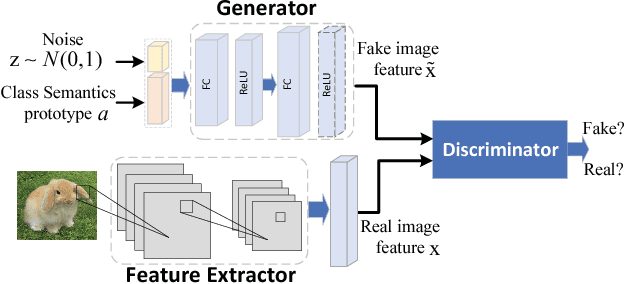
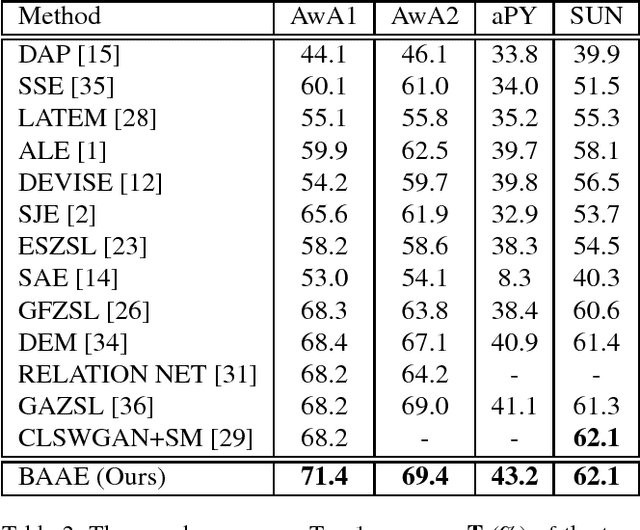
Existing generative Zero-Shot Learning (ZSL) methods only consider the unidirectional alignment from the class semantics to the visual features while ignoring the alignment from the visual features to the class semantics, which fails to construct the visual-semantic interactions well. In this paper, we propose to synthesize visual features based on an auto-encoder framework paired with bi-adversarial networks respectively for visual and semantic modalities to reinforce the visual-semantic interactions with a bi-directional alignment, which ensures the synthesized visual features to fit the real visual distribution and to be highly related to the semantics. The encoder aims at synthesizing real-like visual features while the decoder forces both the real and the synthesized visual features to be more related to the class semantics. To further capture the discriminative information of the synthesized visual features, both the real and synthesized visual features are forced to be classified into the correct classes via a classification network. Experimental results on four benchmark datasets show that the proposed approach is particularly competitive on both the traditional ZSL and the generalized ZSL tasks.
A Survey of Multi-View Representation Learning
Oct 24, 2018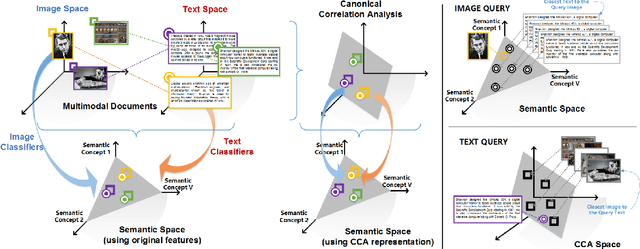
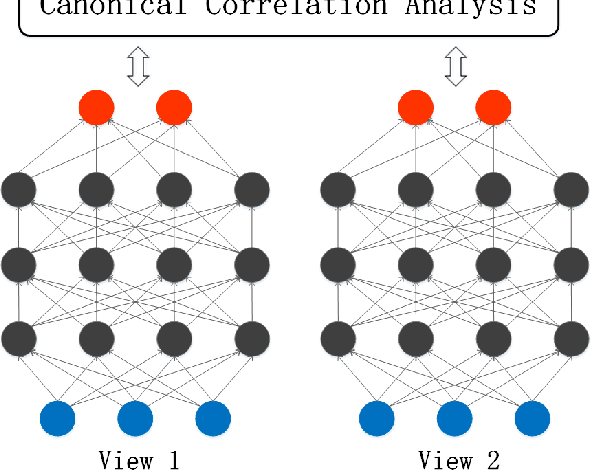
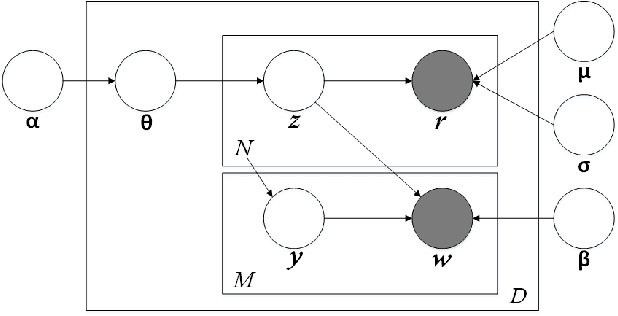
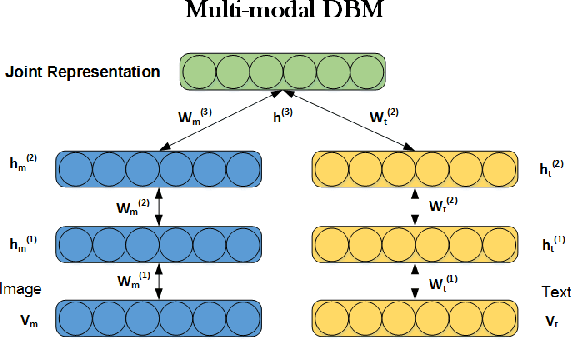
Recently, multi-view representation learning has become a rapidly growing direction in machine learning and data mining areas. This paper introduces two categories for multi-view representation learning: multi-view representation alignment and multi-view representation fusion. Consequently, we first review the representative methods and theories of multi-view representation learning based on the perspective of alignment, such as correlation-based alignment. Representative examples are canonical correlation analysis (CCA) and its several extensions. Then from the perspective of representation fusion we investigate the advancement of multi-view representation learning that ranges from generative methods including multi-modal topic learning, multi-view sparse coding, and multi-view latent space Markov networks, to neural network-based methods including multi-modal autoencoders, multi-view convolutional neural networks, and multi-modal recurrent neural networks. Further, we also investigate several important applications of multi-view representation learning. Overall, this survey aims to provide an insightful overview of theoretical foundation and state-of-the-art developments in the field of multi-view representation learning and to help researchers find the most appropriate tools for particular applications.
Stacked Pooling: Improving Crowd Counting by Boosting Scale Invariance
Aug 22, 2018

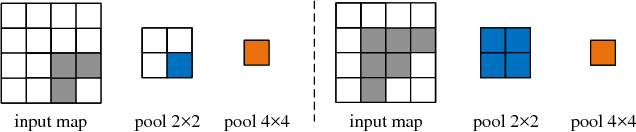
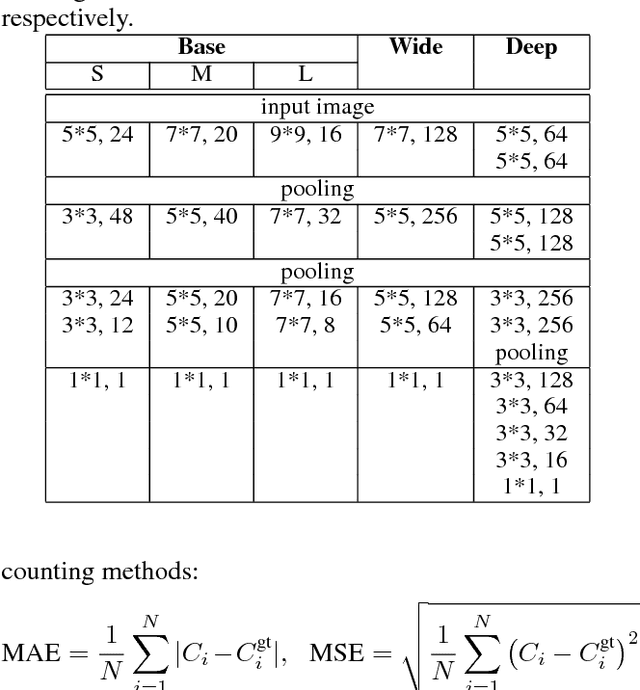
In this work, we explore the cross-scale similarity in crowd counting scenario, in which the regions of different scales often exhibit high visual similarity. This feature is universal both within an image and across different images, indicating the importance of scale invariance of a crowd counting model. Motivated by this, in this paper we propose simple but effective variants of pooling module, i.e., multi-kernel pooling and stacked pooling, to boost the scale invariance of convolutional neural networks (CNNs), benefiting much the crowd density estimation and counting. Specifically, the multi-kernel pooling comprises of pooling kernels with multiple receptive fields to capture the responses at multi-scale local ranges. The stacked pooling is an equivalent form of multi-kernel pooling, while, it reduces considerable computing cost. Our proposed pooling modules do not introduce extra parameters into model and can easily take place of the vanilla pooling layer in implementation. In empirical study on two benchmark crowd counting datasets, the stacked pooling beats the vanilla pooling layer in most cases.
GNAS: A Greedy Neural Architecture Search Method for Multi-Attribute Learning
Aug 01, 2018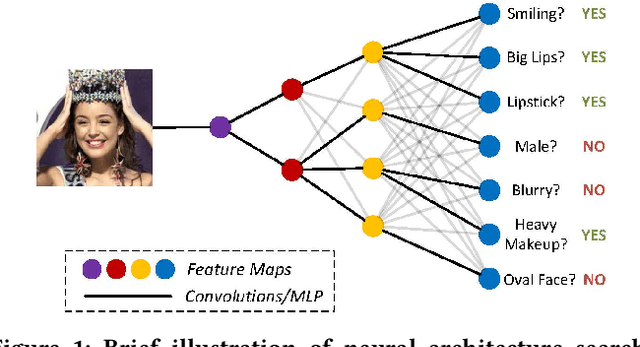
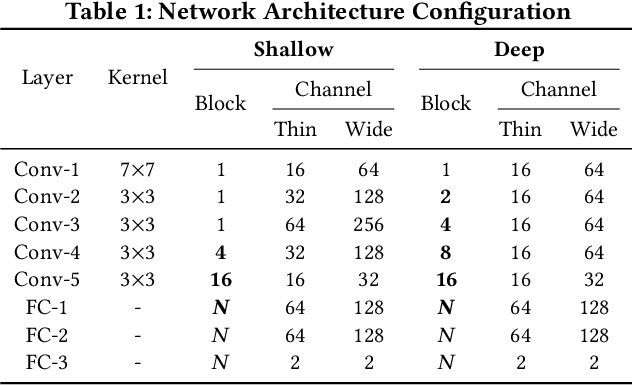
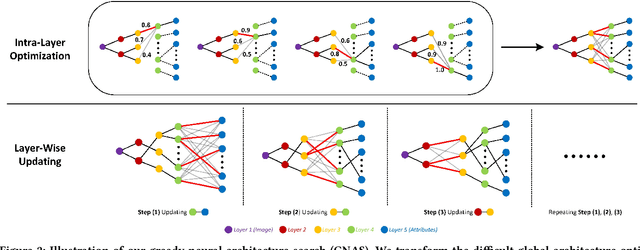
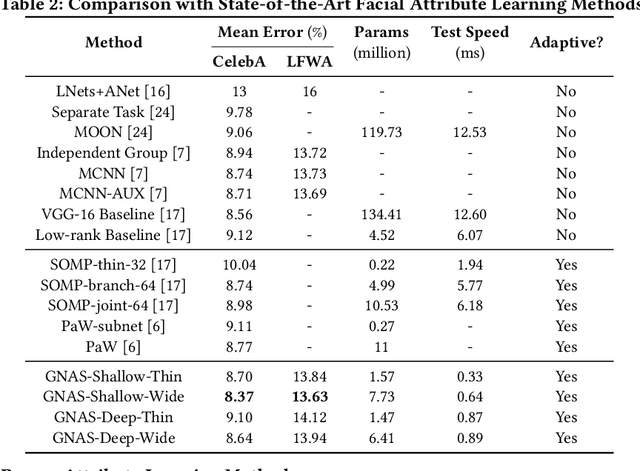
A key problem in deep multi-attribute learning is to effectively discover the inter-attribute correlation structures. Typically, the conventional deep multi-attribute learning approaches follow the pipeline of manually designing the network architectures based on task-specific expertise prior knowledge and careful network tunings, leading to the inflexibility for various complicated scenarios in practice. Motivated by addressing this problem, we propose an efficient greedy neural architecture search approach (GNAS) to automatically discover the optimal tree-like deep architecture for multi-attribute learning. In a greedy manner, GNAS divides the optimization of global architecture into the optimizations of individual connections step by step. By iteratively updating the local architectures, the global tree-like architecture gets converged where the bottom layers are shared across relevant attributes and the branches in top layers more encode attribute-specific features. Experiments on three benchmark multi-attribute datasets show the effectiveness and compactness of neural architectures derived by GNAS, and also demonstrate the efficiency of GNAS in searching neural architectures.
Stacked Semantic-Guided Attention Model for Fine-Grained Zero-Shot Learning
May 21, 2018
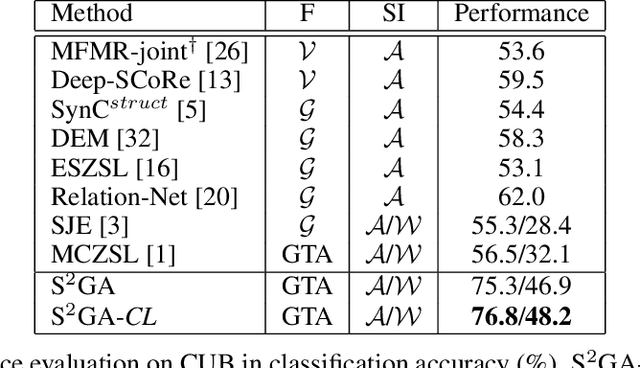
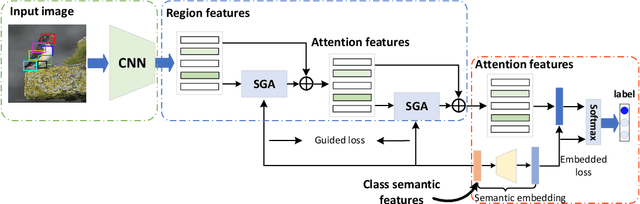
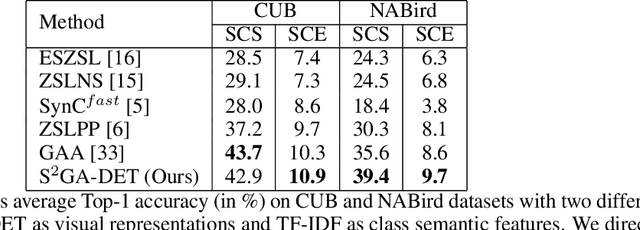
Zero-Shot Learning (ZSL) is achieved via aligning the semantic relationships between the global image feature vector and the corresponding class semantic descriptions. However, using the global features to represent fine-grained images may lead to sub-optimal results since they neglect the discriminative differences of local regions. Besides, different regions contain distinct discriminative information. The important regions should contribute more to the prediction. To this end, we propose a novel stacked semantics-guided attention (S2GA) model to obtain semantic relevant features by using individual class semantic features to progressively guide the visual features to generate an attention map for weighting the importance of different local regions. Feeding both the integrated visual features and the class semantic features into a multi-class classification architecture, the proposed framework can be trained end-to-end. Extensive experimental results on CUB and NABird datasets show that the proposed approach has a consistent improvement on both fine-grained zero-shot classification and retrieval tasks.
Multi-Channel Pyramid Person Matching Network for Person Re-Identification
Mar 07, 2018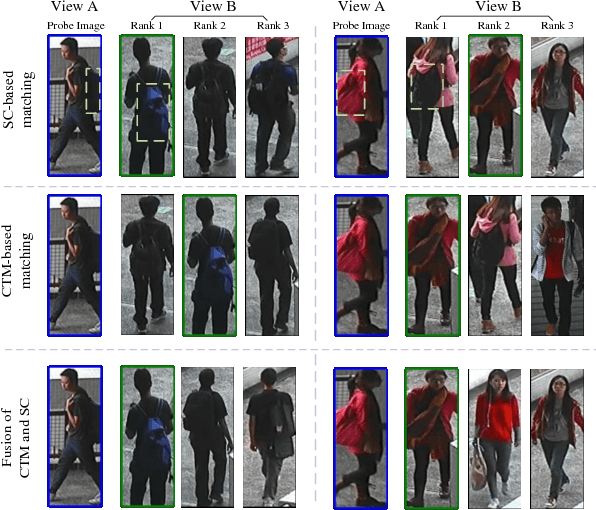
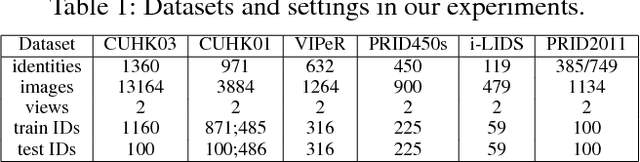
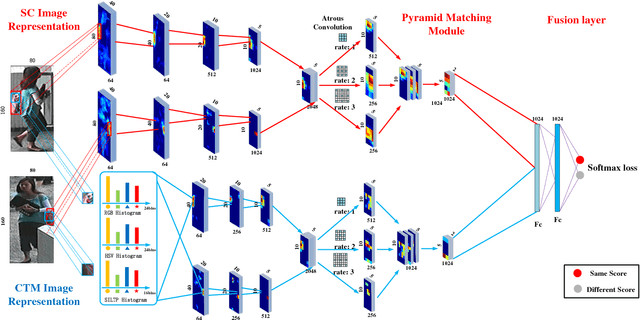
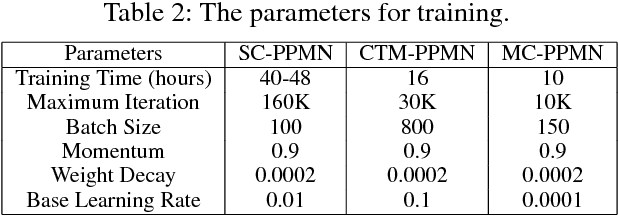
In this work, we present a Multi-Channel deep convolutional Pyramid Person Matching Network (MC-PPMN) based on the combination of the semantic-components and the color-texture distributions to address the problem of person re-identification. In particular, we learn separate deep representations for semantic-components and color-texture distributions from two person images and then employ pyramid person matching network (PPMN) to obtain correspondence representations. These correspondence representations are fused to perform the re-identification task. Further, the proposed framework is optimized via a unified end-to-end deep learning scheme. Extensive experiments on several benchmark datasets demonstrate the effectiveness of our approach against the state-of-the-art literature, especially on the rank-1 recognition rate.
Pyramid Person Matching Network for Person Re-identification
Mar 07, 2018
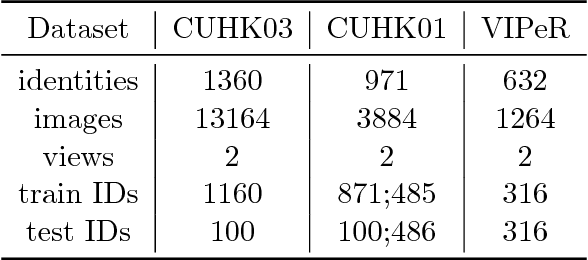
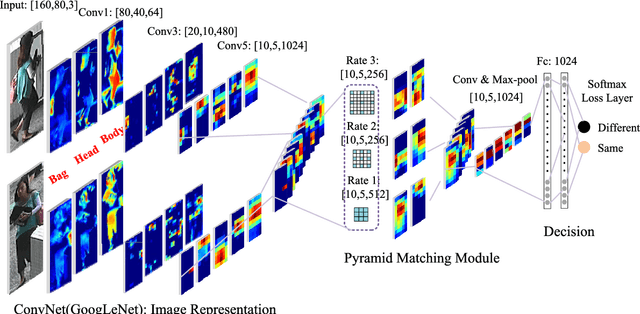
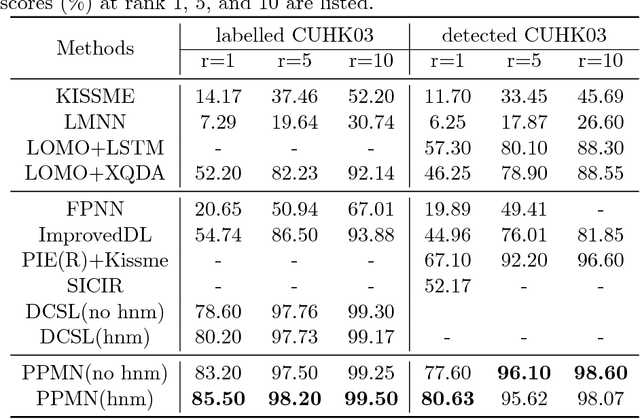
In this work, we present a deep convolutional pyramid person matching network (PPMN) with specially designed Pyramid Matching Module to address the problem of person re-identification. The architecture takes a pair of RGB images as input, and outputs a similiarity value indicating whether the two input images represent the same person or not. Based on deep convolutional neural networks, our approach first learns the discriminative semantic representation with the semantic-component-aware features for persons and then employs the Pyramid Matching Module to match the common semantic-components of persons, which is robust to the variation of spatial scales and misalignment of locations posed by viewpoint changes. The above two processes are jointly optimized via a unified end-to-end deep learning scheme. Extensive experiments on several benchmark datasets demonstrate the effectiveness of our approach against the state-of-the-art approaches, especially on the rank-1 recognition rate.
A Deep Learning Approach for Expert Identification in Question Answering Communities
Nov 14, 2017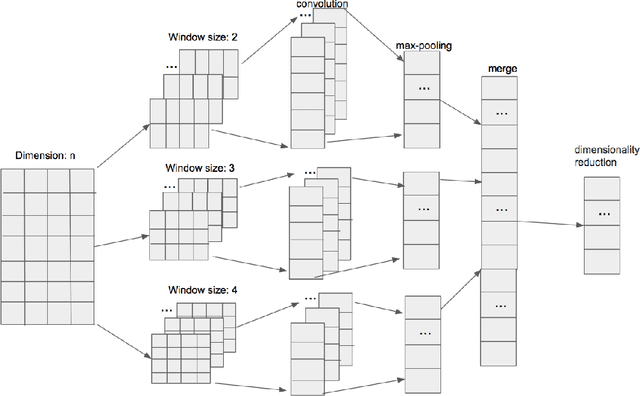
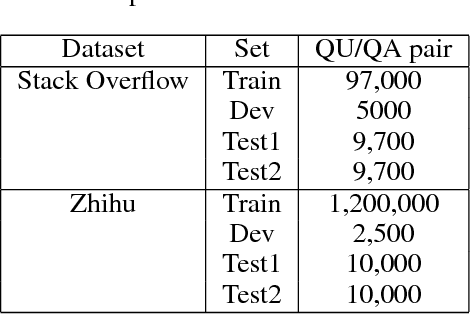
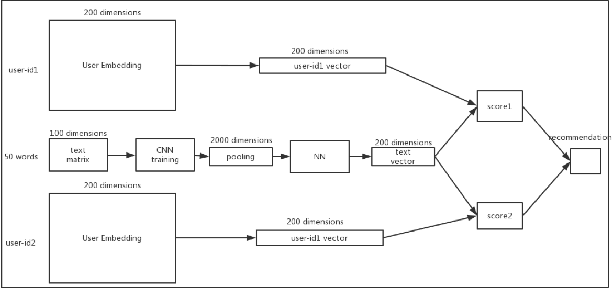

In this paper, we describe an effective convolutional neural network framework for identifying the expert in question answering community. This approach uses the convolutional neural network and combines user feature representations with question feature representations to compute scores that the user who gets the highest score is the expert on this question. Unlike prior work, this method does not measure expert based on measure answer content quality to identify the expert but only require question sentence and user embedding feature to identify the expert. Remarkably, Our model can be applied to different languages and different domains. The proposed framework is trained on two datasets, The first dataset is Stack Overflow and the second one is Zhihu. The Top-1 accuracy results of our experiments show that our framework outperforms the best baseline framework for expert identification.
Text Coherence Analysis Based on Deep Neural Network
Oct 21, 2017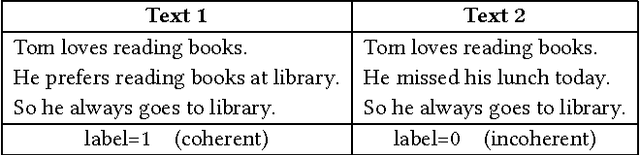
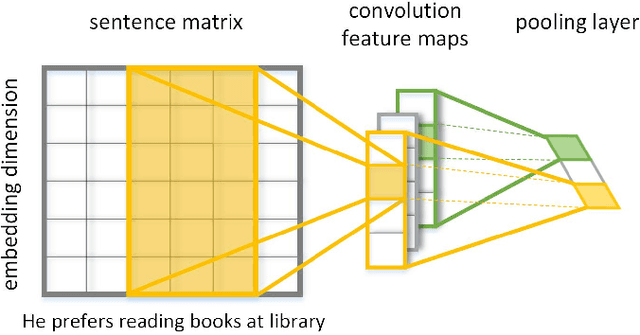
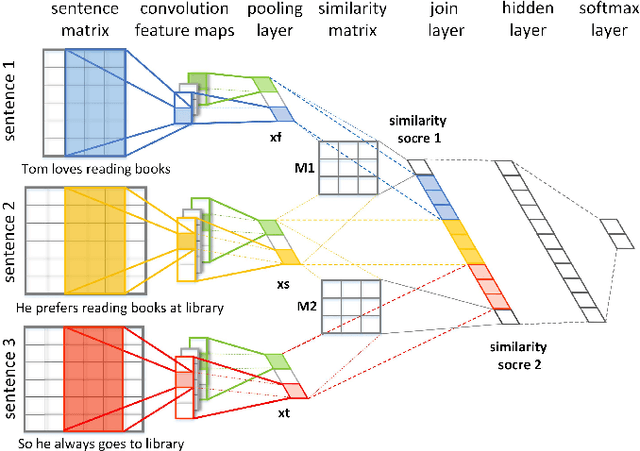
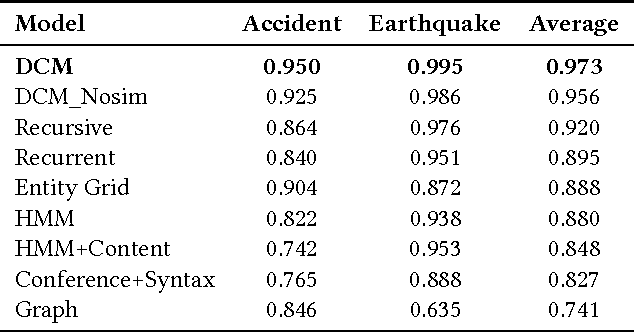
In this paper, we propose a novel deep coherence model (DCM) using a convolutional neural network architecture to capture the text coherence. The text coherence problem is investigated with a new perspective of learning sentence distributional representation and text coherence modeling simultaneously. In particular, the model captures the interactions between sentences by computing the similarities of their distributional representations. Further, it can be easily trained in an end-to-end fashion. The proposed model is evaluated on a standard Sentence Ordering task. The experimental results demonstrate its effectiveness and promise in coherence assessment showing a significant improvement over the state-of-the-art by a wide margin.
Transductive Zero-Shot Learning with a Self-training dictionary approach
Mar 27, 2017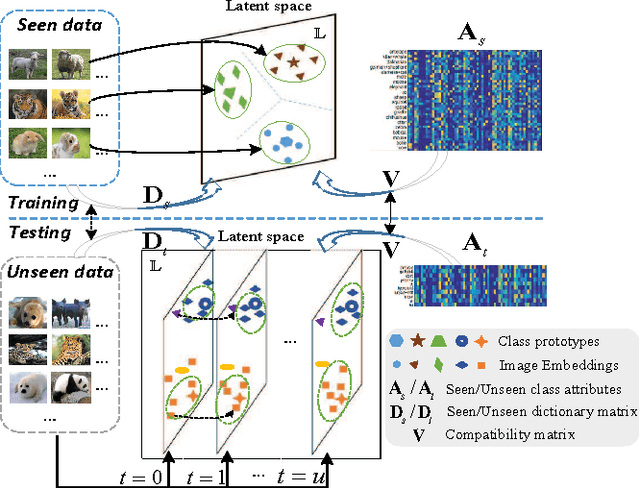
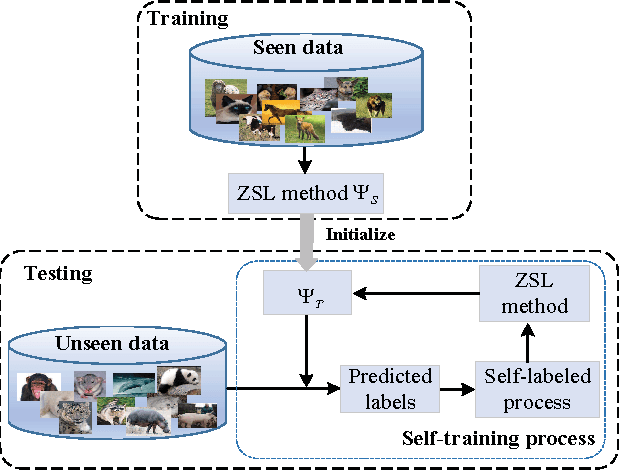
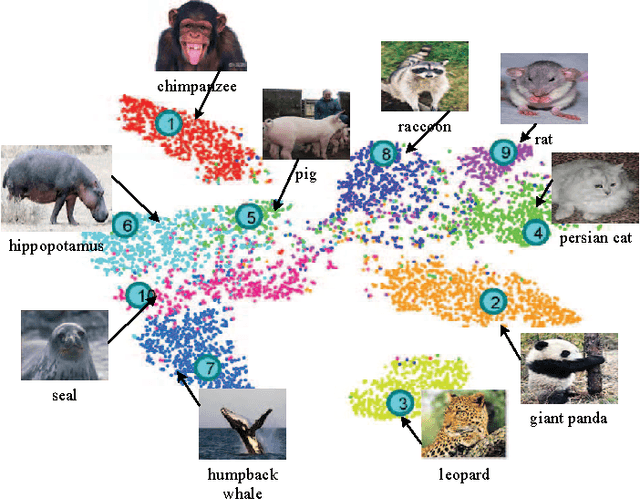
As an important and challenging problem in computer vision, zero-shot learning (ZSL) aims at automatically recognizing the instances from unseen object classes without training data. To address this problem, ZSL is usually carried out in the following two aspects: 1) capturing the domain distribution connections between seen classes data and unseen classes data; and 2) modeling the semantic interactions between the image feature space and the label embedding space. Motivated by these observations, we propose a bidirectional mapping based semantic relationship modeling scheme that seeks for crossmodal knowledge transfer by simultaneously projecting the image features and label embeddings into a common latent space. Namely, we have a bidirectional connection relationship that takes place from the image feature space to the latent space as well as from the label embedding space to the latent space. To deal with the domain shift problem, we further present a transductive learning approach that formulates the class prediction problem in an iterative refining process, where the object classification capacity is progressively reinforced through bootstrapping-based model updating over highly reliable instances. Experimental results on three benchmark datasets (AwA, CUB and SUN) demonstrate the effectiveness of the proposed approach against the state-of-the-art approaches.