 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Curves for Analysis of Deep Networks
Oct 21, 2020
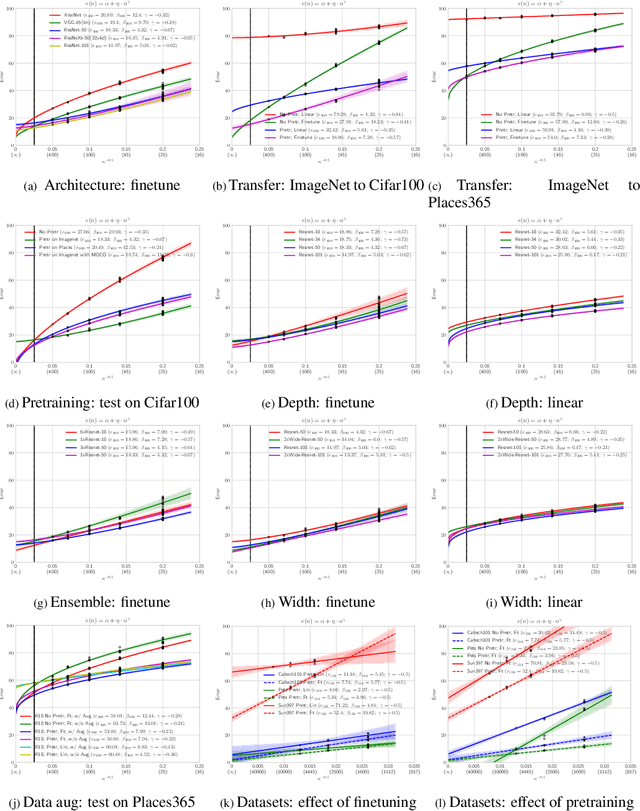

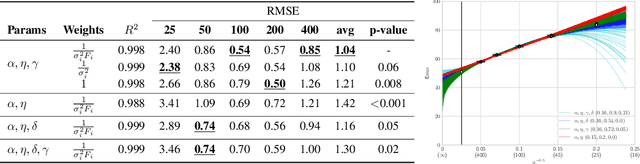
A learning curve models a classifier's test error as a function of the number of training samples. Prior works show that learning curves can be used to select model parameters and extrapolate performance. We investigate how to use learning curves to analyze the impact of design choices, such as pre-training, architecture, and data augmentation. We propose a method to robustly estimate learning curves, abstract their parameters into error and data-reliance, and evaluate the effectiveness of different parameterizations. We also provide several interesting observations based on learning curves for a variety of image classification models.
Regularizing Reasons for Outfit Evaluation with Gradient Penalty
Feb 02, 2020
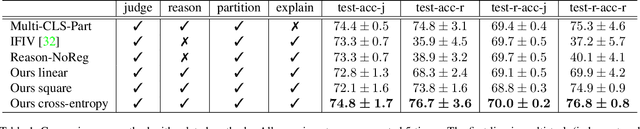
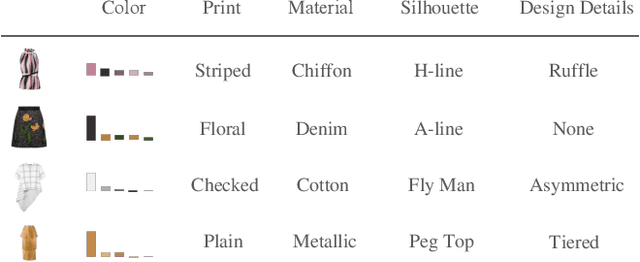
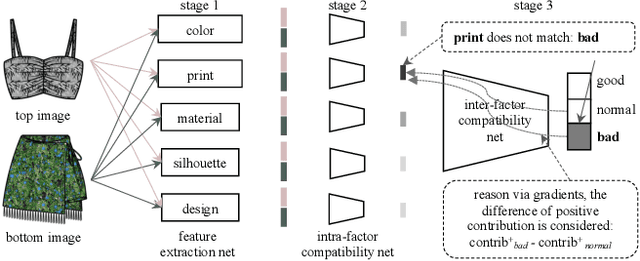
In this paper, we build an outfit evaluation system which provides feedbacks consisting of a judgment with a convincing explanation. The system is trained in a supervised manner which faithfully follows the domain knowledge in fashion. We create the EVALUATION3 dataset which is annotated with judgment, the decisive reason for the judgment, and all corresponding attributes (e.g. print, silhouette, and material \etc.). In the training process, features of all attributes in an outfit are first extracted and then concatenated as the input for the intra-factor compatibility net. Then, the inter-factor compatibility net is used to compute the loss for judgment. We penalize the gradient of judgment loss of so that our Grad-CAM-like reason is regularized to be consistent with the labeled reason. In inference, according to the obtained information of judgment, reason, and attributes, a user-friendly explanation sentence is generated by the pre-defined templates. The experimental results show that the obtained network combines the advantages of high precision and good interpretation.
Dreaming to Distill: Data-free Knowledge Transfer via DeepInversion
Dec 18, 2019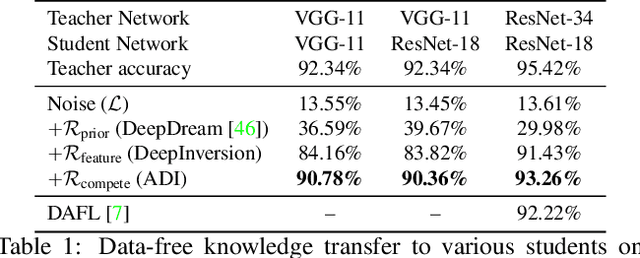
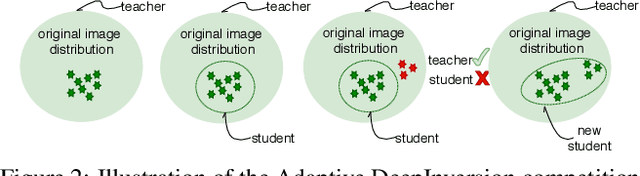
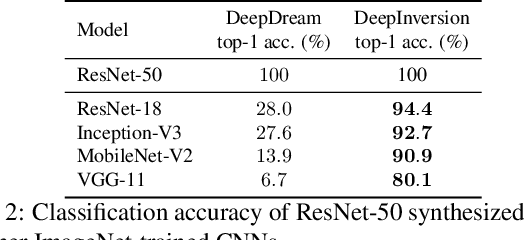

We introduce DeepInversion, a new method for synthesizing images from the image distribution used to train a deep neural network. We 'invert' a trained network (teacher) to synthesize class-conditional input images starting from random noise, without using any additional information about the training dataset. Keeping the teacher fixed, our method optimizes the input while regularizing the distribution of intermediate feature maps using information stored in the batch normalization layers of the teacher. Further, we improve the diversity of synthesized images using Adaptive DeepInversion, which maximizes the Jensen-Shannon divergence between the teacher and student network logits. The resulting synthesized images from networks trained on the CIFAR-10 and ImageNet datasets demonstrate high fidelity and degree of realism, and help enable a new breed of data-free applications - ones that do not require any real images or labeled data. We demonstrate the applicability of our proposed method to three tasks of immense practical importance -- (i) data-free network pruning, (ii) data-free knowledge transfer, and (iii) data-free continual learning.
Policy Continuation with Hindsight Inverse Dynamics
Nov 01, 2019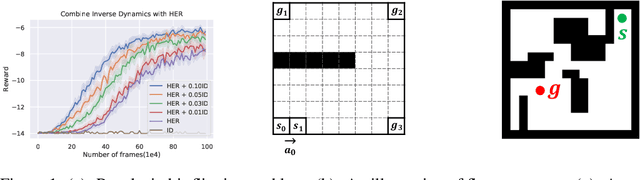



Solving goal-oriented tasks is an important but challenging problem in reinforcement learning (RL). For such tasks, the rewards are often sparse, making it difficult to learn a policy effectively. To tackle this difficulty, we propose a new approach called Policy Continuation with Hindsight Inverse Dynamics (PCHID). This approach learns from Hindsight Inverse Dynamics based on Hindsight Experience Replay, enabling the learning process in a self-imitated manner and thus can be trained with supervised learning. This work also extends it to multi-step settings with Policy Continuation. The proposed method is general, which can work in isolation or be combined with other on-policy and off-policy algorithms. On two multi-goal tasks GridWorld and FetchReach, PCHID significantly improves the sample efficiency as well as the final performance.
Biased Estimates of Advantages over Path Ensembles
Sep 15, 2019
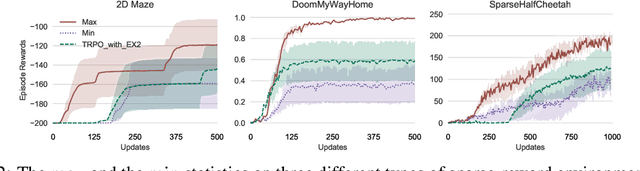
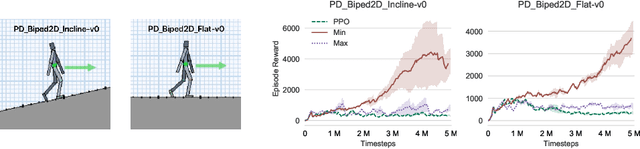
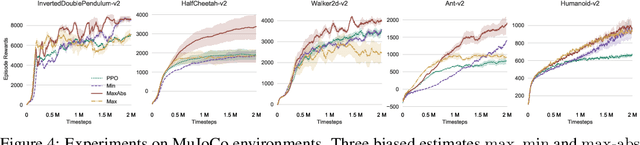
The estimation of advantage is crucial for a number of reinforcement learning algorithms, as it directly influences the choices of future paths. In this work, we propose a family of estimates based on the order statistics over the path ensemble, which allows one to flexibly drive the learning process, towards or against risks. On top of this formulation, we systematically study the impacts of different methods for estimating advantages. Our findings reveal that biased estimates, when chosen appropriately, can result in significant benefits. In particular, for the environments with sparse rewards, optimistic estimates would lead to more efficient exploration of the policy space; while for those where individual actions can have critical impacts, conservative estimates are preferable. On various benchmarks, including MuJoCo continuous control, Terrain locomotion, Atari games, and sparse-reward environments, the proposed biased estimation schemes consistently demonstrate improvement over mainstream methods, not only accelerating the learning process but also obtaining substantial performance gains.
Anchor Tasks: Inexpensive, Shared, and Aligned Tasks for Domain Adaptation
Aug 16, 2019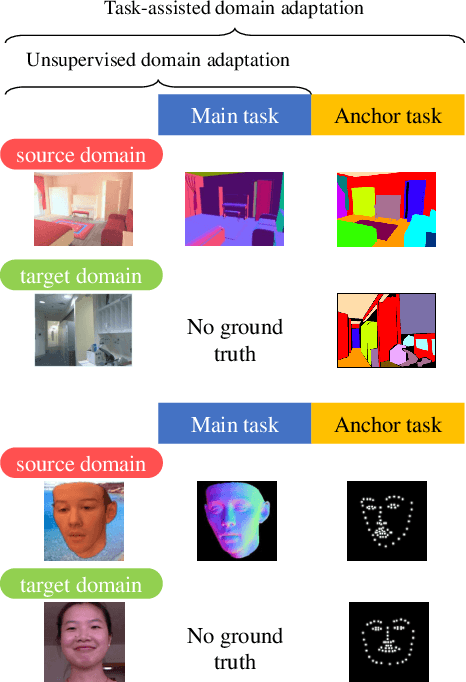
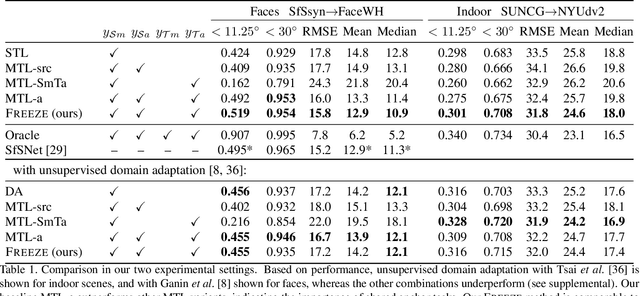
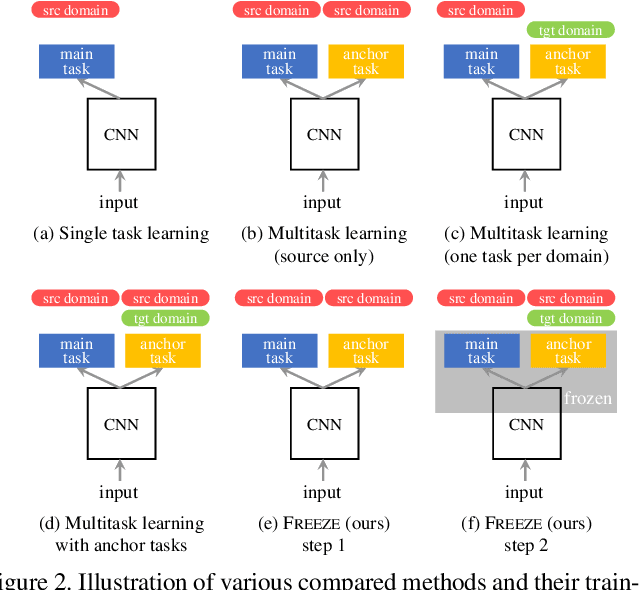
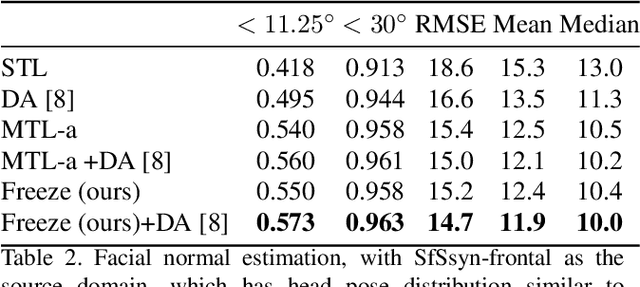
We introduce a novel domain adaptation formulation from synthetic dataset (source domain) to real dataset (target domain) for the category of tasks with per-pixel predictions. The annotations of these tasks are relatively hard to acquire in the real world, such as single-view depth estimation or surface normal estimation. Our key idea is to introduce anchor tasks, whose annotations are (1) less expensive to acquire than the main task, such as facial landmarks and semantic segmentations; and (2) shared in availability for both synthetic and real datasets so that it serves as "anchor" between tasks; and finally (3) aligned spatially with main task annotations on a per-pixel basis so that it also serves as spatial anchor between tasks' outputs. To further utilize spatial alignment between the anchor and main tasks, we introduce a novel freeze approach that freezes the final layers of our network after training on the source domain so that spatial and contextual relationship between tasks are maintained when adapting on the target domain. We evaluate our methods on two pairs of datasets, performing surface normal estimation in indoor scenes and faces, using semantic segmentation and facial landmarks as anchor tasks separately. We show the importance of using anchor tasks in both synthetic and real domains, and that the freeze approach outperforms competing approaches, reaching results in facial images on par with the state-of-the-art system that leverages detailed facial appearance model.
$\mathcal{G}$-Distillation: Reducing Overconfident Errors on Novel Samples
Apr 09, 2018

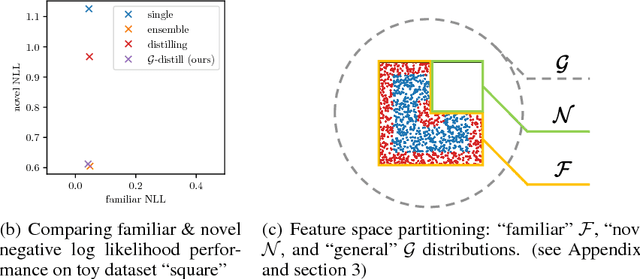

Counter to the intuition that unfamiliarity should lead to lack of confidence, current algorithms often make highly confident yet wrong predictions when faced with unexpected test samples from an unknown distribution different from training. Unlike all domain adaptation methods, we cannot gather an "unexpected dataset" prior to test. We propose a simple solution that reduces overconfident errors of samples from an unknown novel distribution without increasing evaluation time: train an ensemble of classifiers and then distill into a single model using both labeled and unlabeled examples. Experimentally, we investigate the overconfidence problem and evaluate our solution by creating "familiar" and "novel" test splits, where "familiar" are identically distributed with training and "novel" are not. We show that our solution yields more appropriate prediction confidences, on familiar and novel data, compared to single models and ensembles distilled on training data only. For example, we reduce confident errors in gender recognition by 94% on demographic groups different from the training data.
Deep Nearest Class Mean Model for Incremental Odor Classification
Jan 08, 2018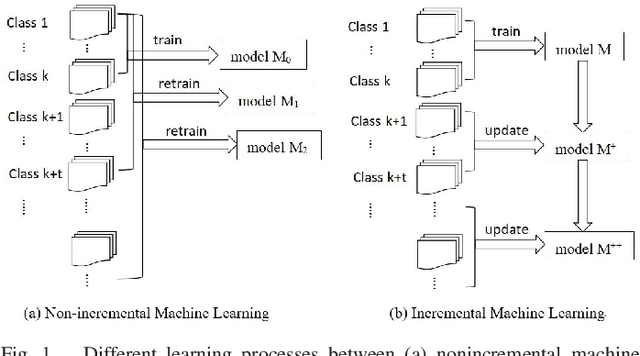
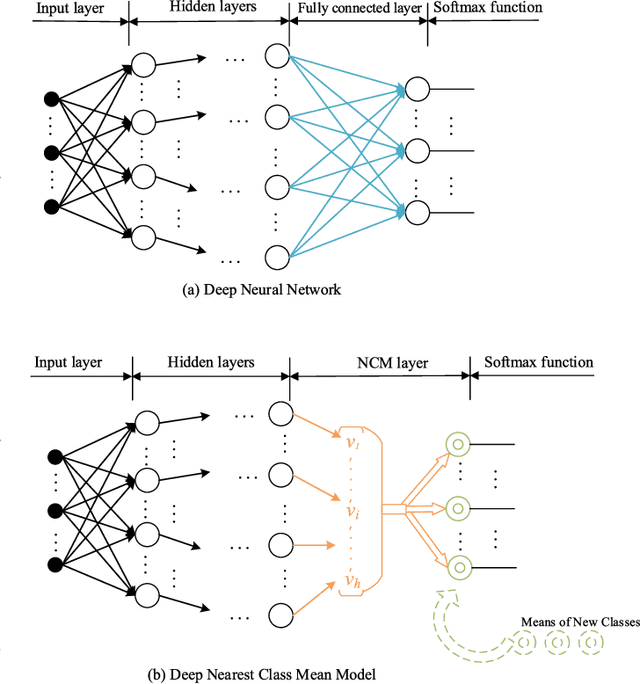
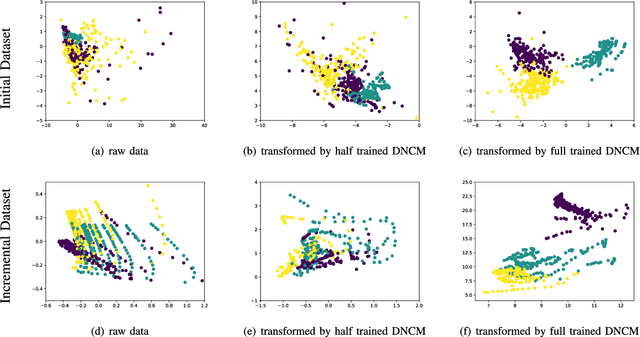
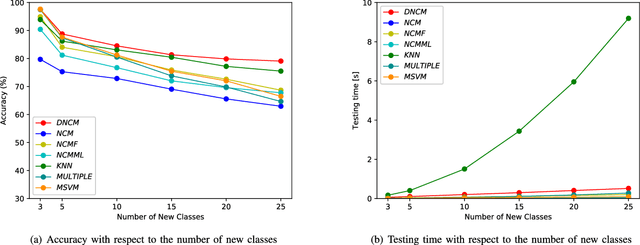
In recent years, more and more machine learning algorithms have been applied to odor recognition. These odor recognition algorithms usually assume that the training dataset is static. However, for some odor recognition tasks, the odor dataset is dynamically growing where not only the training samples but also the number of classes increase over time. Motivated by this concern, we proposed a deep nearest class mean (DNCM) model which combines the deep learning framework and nearest class mean (NCM) method. DNCM not only can leverage deep neural network to extract deep features, but also well suited for integrating new classes. Experiments demonstrate that the proposed DNCM model is effective and efficient for incremental odor classification, especially for new classes with only a small number of training examples.
Complete 3D Scene Parsing from Single RGBD Image
Oct 25, 2017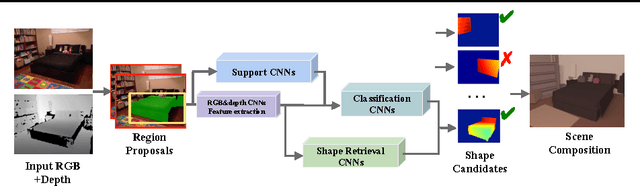

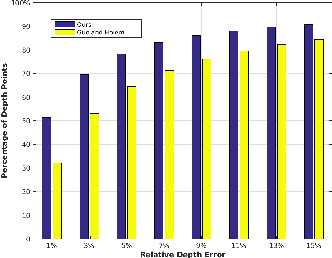

Inferring the location, shape, and class of each object in a single image is an important task in computer vision. In this paper, we aim to predict the full 3D parse of both visible and occluded portions of the scene from one RGBD image. We parse the scene by modeling objects as detailed CAD models with class labels and layouts as 3D planes. Such an interpretation is useful for visual reasoning and robotics, but difficult to produce due to the high degree of occlusion and the diversity of object classes. We follow the recent approaches that retrieve shape candidates for each RGBD region proposal, transfer and align associated 3D models to compose a scene that is consistent with observations. We propose to use support inference to aid interpretation and propose a retrieval scheme that uses convolutional neural networks (CNNs) to classify regions and retrieve objects with similar shapes. We demonstrate the performance of our method compared with the state-of-the-art on our new NYUd v2 dataset annotations which are semi-automatically labelled with detailed 3D shapes for all the objects.
Integrating Specialized Classifiers Based on Continuous Time Markov Chain
Sep 07, 2017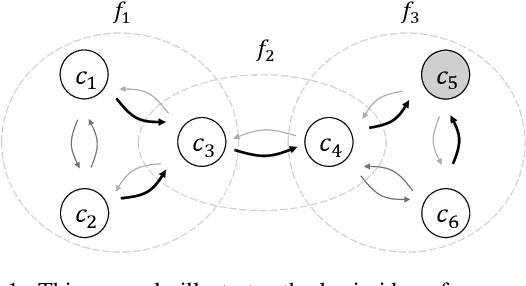
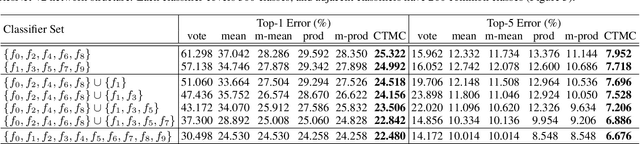
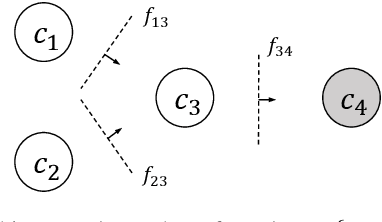
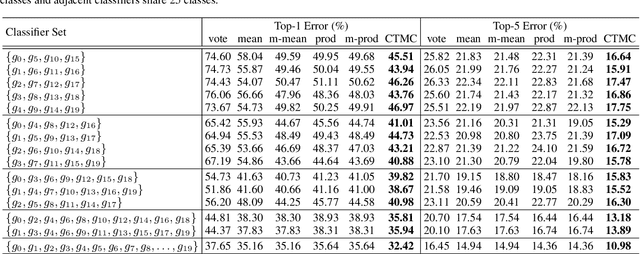
Specialized classifiers, namely those dedicated to a subset of classes, are often adopted in real-world recognition systems. However, integrating such classifiers is nontrivial. Existing methods, e.g. weighted average, usually implicitly assume that all constituents of an ensemble cover the same set of classes. Such methods can produce misleading predictions when used to combine specialized classifiers. This work explores a novel approach. Instead of combining predictions from individual classifiers directly, it first decomposes the predictions into sets of pairwise preferences, treating them as transition channels between classes, and thereon constructs a continuous-time Markov chain, and use the equilibrium distribution of this chain as the final prediction. This way allows us to form a coherent picture over all specialized predictions. On large public datasets, the proposed method obtains considerable improvement compared to mainstream ensemble methods, especially when the classifier coverage is highly unbalanced.