 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero and Few Shot Learning with Semantic Feature Synthesis and Competitive Learning
Oct 19, 2018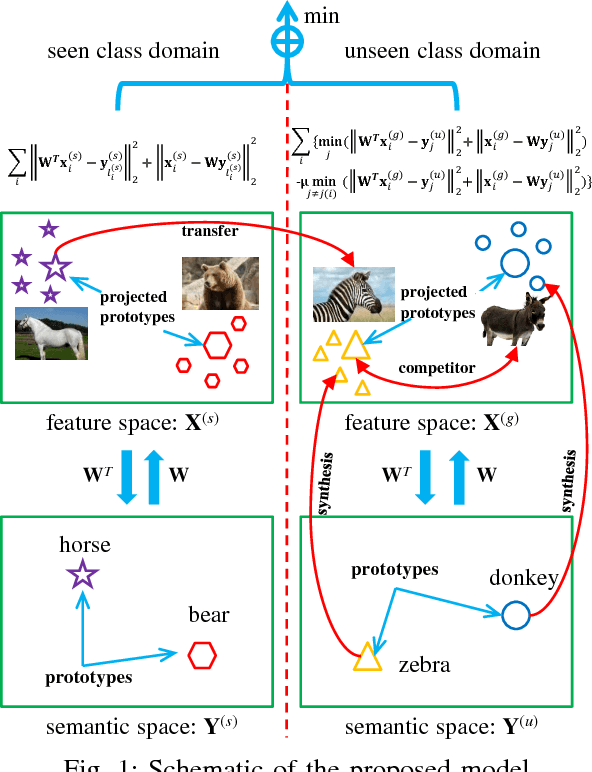
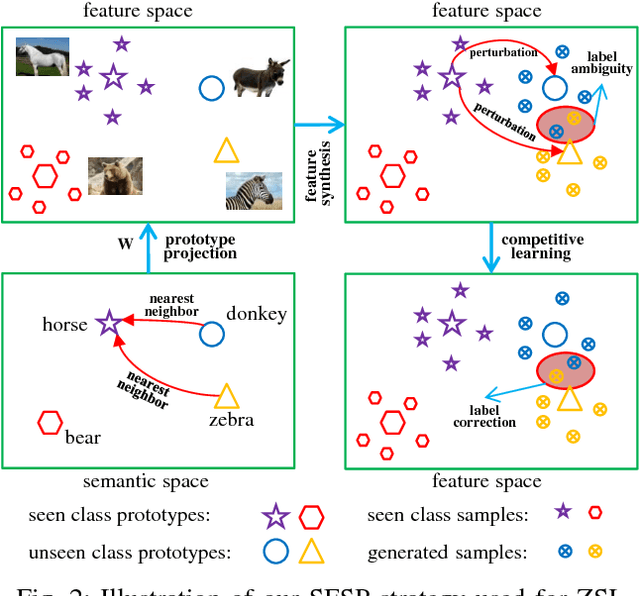
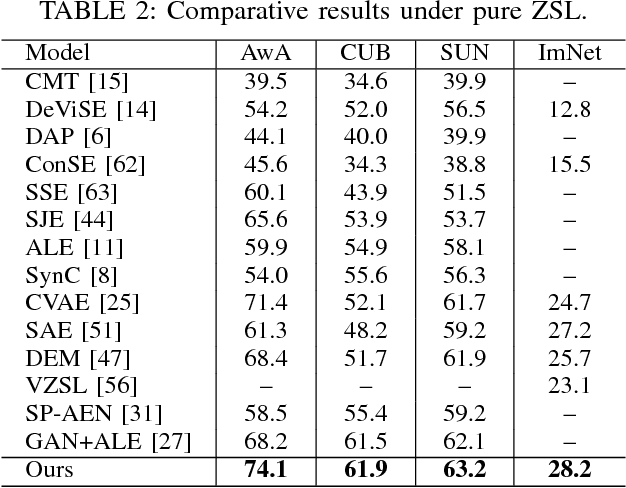
Zero-shot learning (ZSL) is made possible by learning a projection function between a feature space and a semantic space (e.g.,~an attribute space). Key to ZSL is thus to learn a projection that is robust against the often large domain gap between the seen and unseen class domains. In this work, this is achieved by unseen class data synthesis and robust projection function learning. Specifically, a novel semantic data synthesis strategy is proposed, by which semantic class prototypes (e.g., attribute vectors) are used to simply perturb seen class data for generating unseen class ones. As in any data synthesis/hallucination approach, there are ambiguities and uncertainties on how well the synthesised data can capture the targeted unseen class data distribution. To cope with this, the second contribution of this work is a novel projection learning model termed competitive bidirectional projection learning (BPL) designed to best utilise the ambiguous synthesised data. Specifically, we assume that each synthesised data point can belong to any unseen class; and the most likely two class candidates are exploited to learn a robust projection function in a competitive fashion. As a third contribution, we show that the proposed ZSL model can be easily extended to few-shot learning (FSL) by again exploiting semantic (class prototype guided) feature synthesis and competitive BPL. Extensive experiments show that our model achieves the state-of-the-art results on both problems.
Multi-Modal Multi-Scale Deep Learning for Large-Scale Image Annotation
Oct 19, 2018
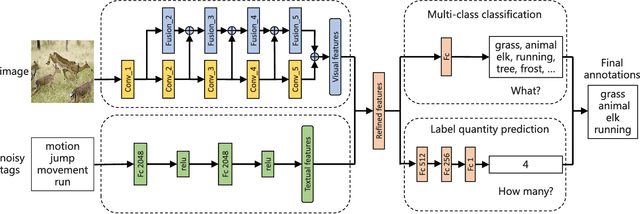
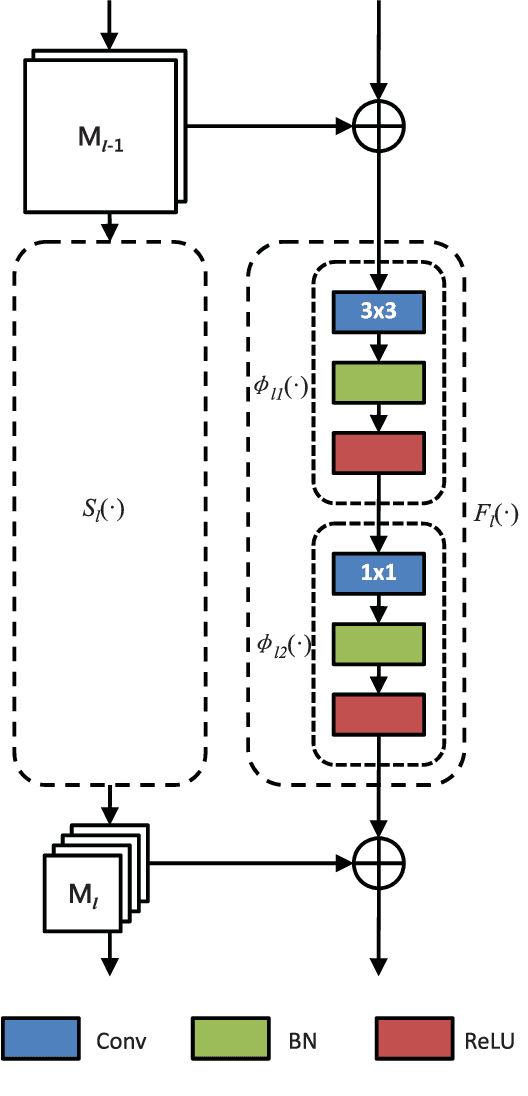
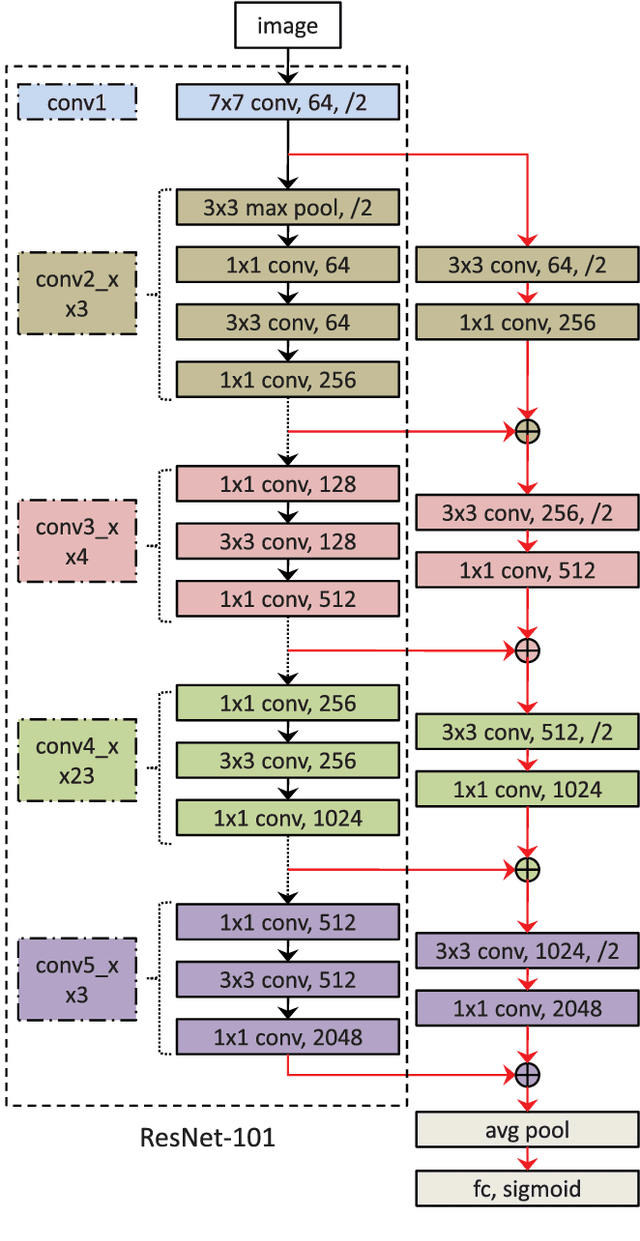
Image annotation aims to annotate a given image with a variable number of class labels corresponding to diverse visual concepts. In this paper, we address two main issues in large-scale image annotation: 1) how to learn a rich feature representation suitable for predicting a diverse set of visual concepts ranging from object, scene to abstract concept; 2) how to annotate an image with the optimal number of class labels. To address the first issue, we propose a novel multi-scale deep model for extracting rich and discriminative features capable of representing a wide range of visual concepts. Specifically, a novel two-branch deep neural network architecture is proposed which comprises a very deep main network branch and a companion feature fusion network branch designed for fusing the multi-scale features computed from the main branch. The deep model is also made multi-modal by taking noisy user-provided tags as model input to complement the image input. For tackling the second issue, we introduce a label quantity prediction auxiliary task to the main label prediction task to explicitly estimate the optimal label number for a given image. Extensive experiments are carried out on two large-scale image annotation benchmark datasets and the results show that our method significantly outperforms the state-of-the-art.
Transferrable Feature and Projection Learning with Class Hierarchy for Zero-Shot Learning
Oct 19, 2018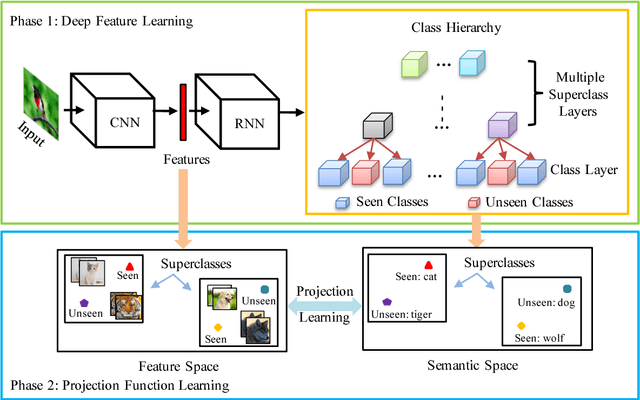
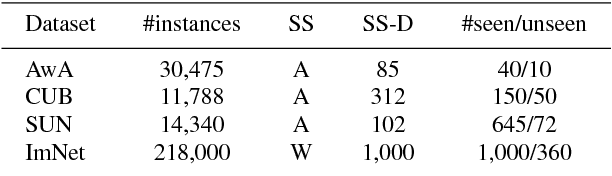
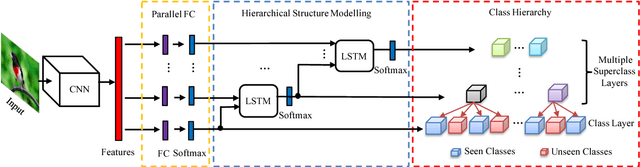
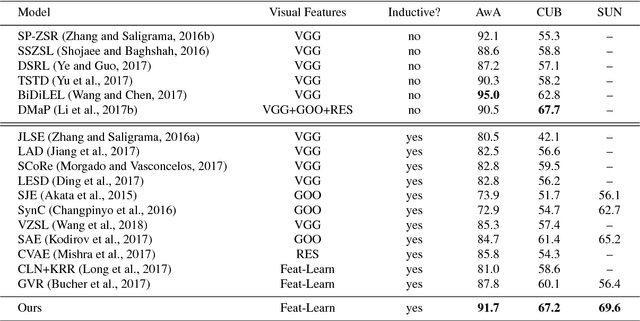
Zero-shot learning (ZSL) aims to transfer knowledge from seen classes to unseen ones so that the latter can be recognised without any training samples. This is made possible by learning a projection function between a feature space and a semantic space (e.g. attribute space). Considering the seen and unseen classes as two domains, a big domain gap often exists which challenges ZSL. Inspired by the fact that an unseen class is not exactly `unseen' if it belongs to the same superclass as a seen class, we propose a novel inductive ZSL model that leverages superclasses as the bridge between seen and unseen classes to narrow the domain gap. Specifically, we first build a class hierarchy of multiple superclass layers and a single class layer, where the superclasses are automatically generated by data-driven clustering over the semantic representations of all seen and unseen class names. We then exploit the superclasses from the class hierarchy to tackle the domain gap challenge in two aspects: deep feature learning and projection function learning. First, to narrow the domain gap in the feature space, we integrate a recurrent neural network (RNN) defined with the superclasses into a convolutional neural network (CNN), in order to enforce the superclass hierarchy. Second, to further learn a transferrable projection function for ZSL, a novel projection function learning method is proposed by exploiting the superclasses to align the two domains. Importantly, our transferrable feature and projection learning methods can be easily extended to a closely related task -- few-shot learning (FSL). Extensive experiments show that the proposed model significantly outperforms the state-of-the-art alternatives in both ZSL and FSL tasks.
Domain-Invariant Projection Learning for Zero-Shot Recognition
Oct 19, 2018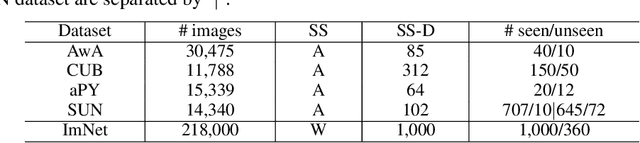
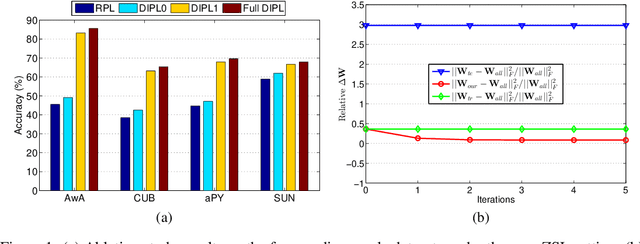
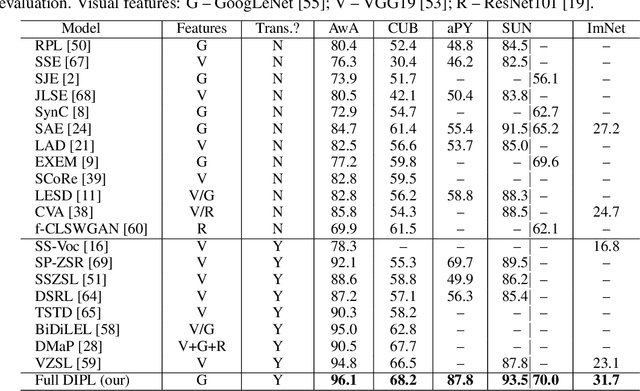
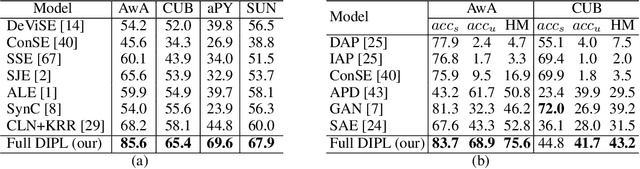
Zero-shot learning (ZSL) aims to recognize unseen object classes without any training samples, which can be regarded as a form of transfer learning from seen classes to unseen ones. This is made possible by learning a projection between a feature space and a semantic space (e.g. attribute space). Key to ZSL is thus to learn a projection function that is robust against the often large domain gap between the seen and unseen classes. In this paper, we propose a novel ZSL model termed domain-invariant projection learning (DIPL). Our model has two novel components: (1) A domain-invariant feature self-reconstruction task is introduced to the seen/unseen class data, resulting in a simple linear formulation that casts ZSL into a min-min optimization problem. Solving the problem is non-trivial, and a novel iterative algorithm is formulated as the solver, with rigorous theoretic algorithm analysis provided. (2) To further align the two domains via the learned projection, shared semantic structure among seen and unseen classes is explored via forming superclasses in the semantic space. Extensive experiments show that our model outperforms the state-of-the-art alternatives by significant margins.
RUM: network Representation learning throUgh Multi-level structural information preservation
Oct 08, 2017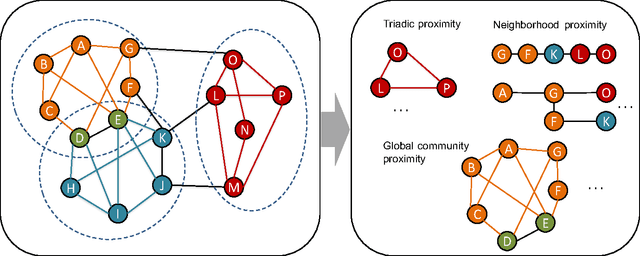
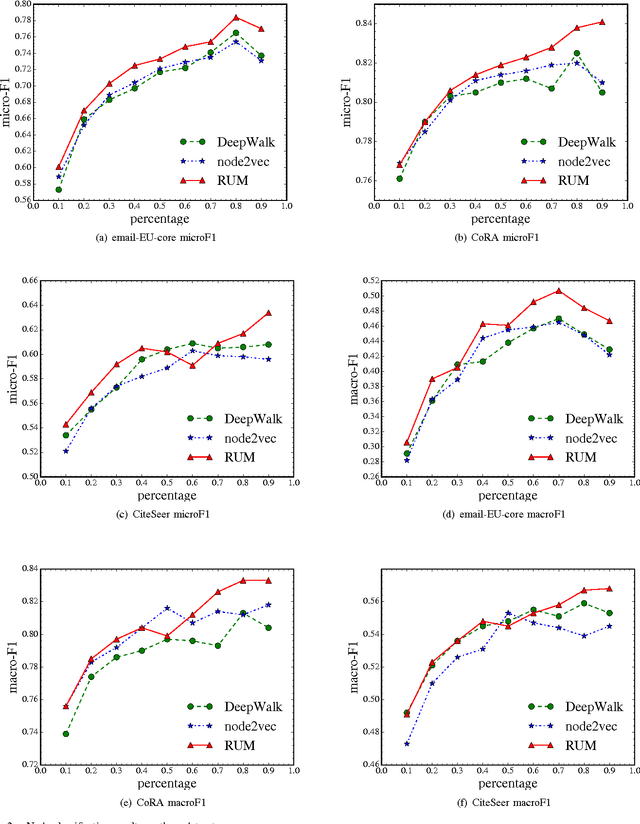
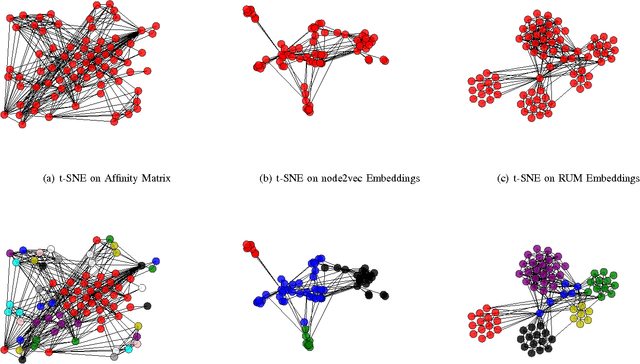
We have witnessed the discovery of many techniques for network representation learning in recent years, ranging from encoding the context in random walks to embedding the lower order connections, to finding latent space representations with auto-encoders. However, existing techniques are looking mostly into the local structures in a network, while higher-level properties such as global community structures are often neglected. We propose a novel network representations learning model framework called RUM (network Representation learning throUgh Multi-level structural information preservation). In RUM, we incorporate three essential aspects of a node that capture a network's characteristics in multiple levels: a node's affiliated local triads, its neighborhood relationships, and its global community affiliations. Therefore the framework explicitly and comprehensively preserves the structural information of a network, extending the encoding process both to the local end of the structural information spectrum and to the global end. The framework is also flexible enough to take various community discovery algorithms as its preprocessor. Empirical results show that the representations learned by RUM have demonstrated substantial performance advantages in real-life tasks.
Zero-Shot Fine-Grained Classification by Deep Feature Learning with Semantics
Jul 04, 2017
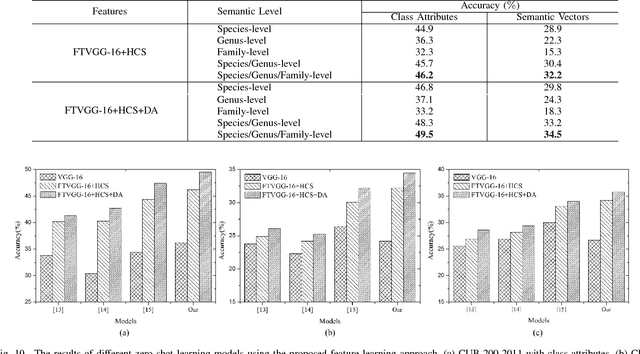
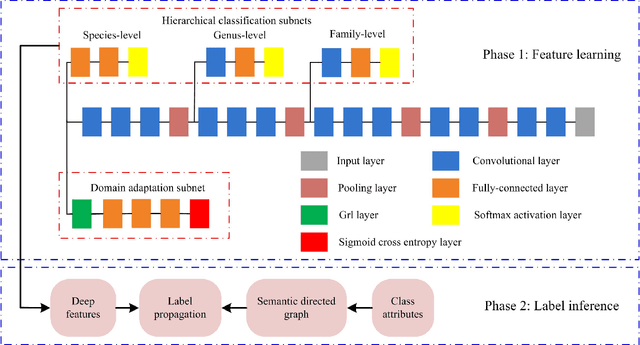
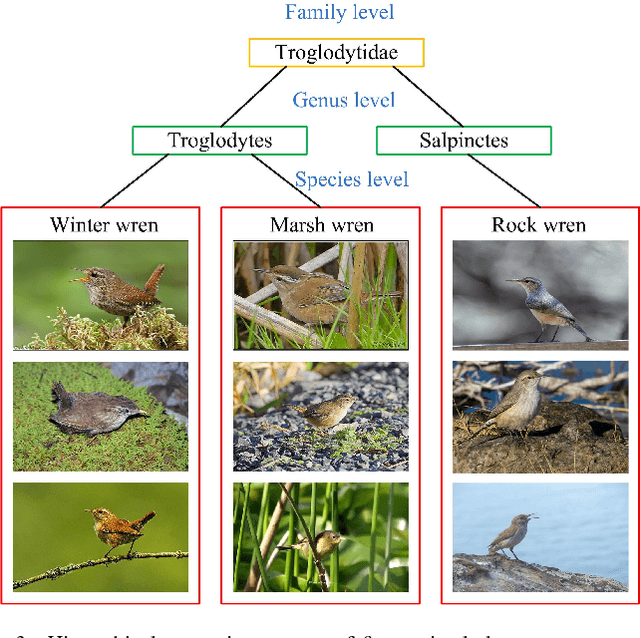
Fine-grained image classification, which aims to distinguish images with subtle distinctions, is a challenging task due to two main issues: lack of sufficient training data for every class and difficulty in learning discriminative features for representation. In this paper, to address the two issues, we propose a two-phase framework for recognizing images from unseen fine-grained classes, i.e. zero-shot fine-grained classification. In the first feature learning phase, we finetune deep convolutional neural networks using hierarchical semantic structure among fine-grained classes to extract discriminative deep visual features. Meanwhile, a domain adaptation structure is induced into deep convolutional neural networks to avoid domain shift from training data to test data. In the second label inference phase, a semantic directed graph is constructed over attributes of fine-grained classes. Based on this graph, we develop a label propagation algorithm to infer the labels of images in the unseen classes. Experimental results on two benchmark datasets demonstrate that our model outperforms the state-of-the-art zero-shot learning models. In addition, the features obtained by our feature learning model also yield significant gains when they are used by other zero-shot learning models, which shows the flexility of our model in zero-shot fine-grained classification.
Pairwise Constraint Propagation: A Survey
Feb 19, 2015As one of the most important types of (weaker) supervised information in machine learning and pattern recognition, pairwise constraint, which specifies whether a pair of data points occur together, has recently received significant attention, especially the problem of pairwise constraint propagation. At least two reasons account for this trend: the first is that compared to the data label, pairwise constraints are more general and easily to collect, and the second is that since the available pairwise constraints are usually limited, the constraint propagation problem is thus important. This paper provides an up-to-date critical survey of pairwise constraint propagation research. There are two underlying motivations for us to write this survey paper: the first is to provide an up-to-date review of the existing literature, and the second is to offer some insights into the studies of pairwise constraint propagation. To provide a comprehensive survey, we not only categorize existing propagation techniques but also present detailed descriptions of representative methods within each category.
Image classification by visual bag-of-words refinement and reduction
Jan 18, 2015

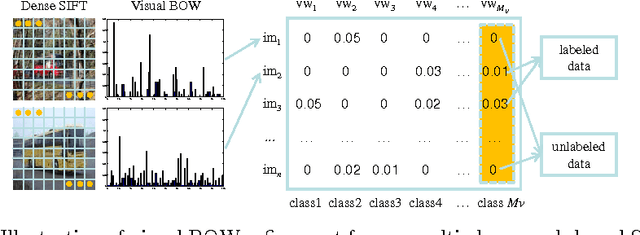

This paper presents a new framework for visual bag-of-words (BOW) refinement and reduction to overcome the drawbacks associated with the visual BOW model which has been widely used for image classification. Although very influential in the literature, the traditional visual BOW model has two distinct drawbacks. Firstly, for efficiency purposes, the visual vocabulary is commonly constructed by directly clustering the low-level visual feature vectors extracted from local keypoints, without considering the high-level semantics of images. That is, the visual BOW model still suffers from the semantic gap, and thus may lead to significant performance degradation in more challenging tasks (e.g. social image classification). Secondly, typically thousands of visual words are generated to obtain better performance on a relatively large image dataset. Due to such large vocabulary size, the subsequent image classification may take sheer amount of time. To overcome the first drawback, we develop a graph-based method for visual BOW refinement by exploiting the tags (easy to access although noisy) of social images. More notably, for efficient image classification, we further reduce the refined visual BOW model to a much smaller size through semantic spectral clustering. Extensive experimental results show the promising performance of the proposed framework for visual BOW refinement and reduction.
Pairwise Constraint Propagation on Multi-View Data
Jan 18, 2015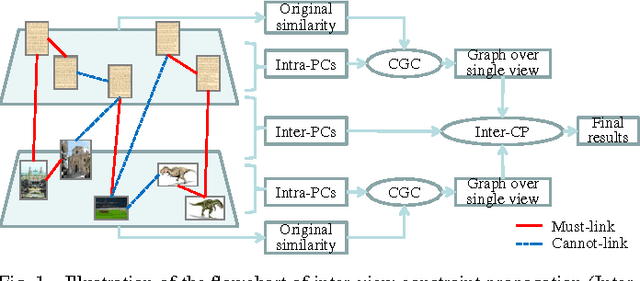
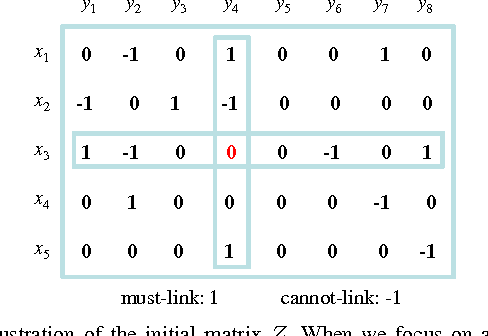

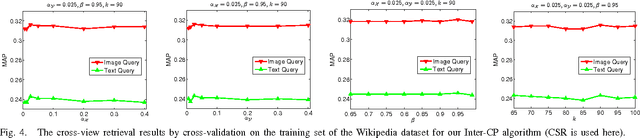
This paper presents a graph-based learning approach to pairwise constraint propagation on multi-view data. Although pairwise constraint propagation has been studied extensively, pairwise constraints are usually defined over pairs of data points from a single view, i.e., only intra-view constraint propagation is considered for multi-view tasks. In fact, very little attention has been paid to inter-view constraint propagation, which is more challenging since pairwise constraints are now defined over pairs of data points from different views. In this paper, we propose to decompose the challenging inter-view constraint propagation problem into semi-supervised learning subproblems so that they can be efficiently solved based on graph-based label propagation. To the best of our knowledge, this is the first attempt to give an efficient solution to inter-view constraint propagation from a semi-supervised learning viewpoint. Moreover, since graph-based label propagation has been adopted for basic optimization, we develop two constrained graph construction methods for interview constraint propagation, which only differ in how the intra-view pairwise constraints are exploited. The experimental results in cross-view retrieval have shown the promising performance of our inter-view constraint propagation.
Can Image-Level Labels Replace Pixel-Level Labels for Image Parsing
Nov 13, 2014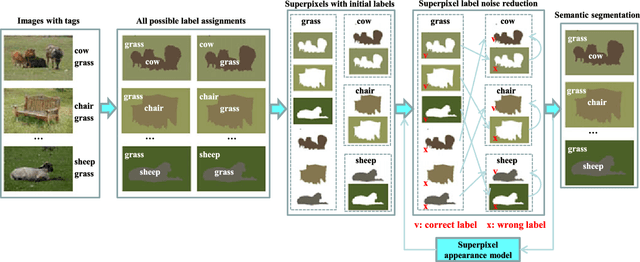

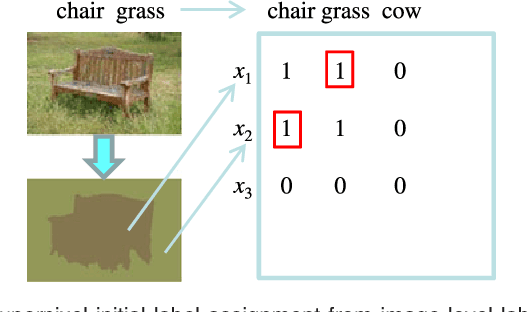
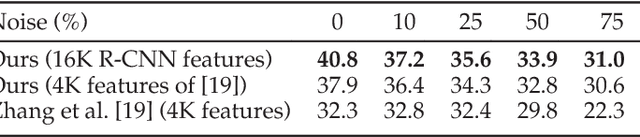
This paper presents a weakly supervised sparse learning approach to the problem of noisily tagged image parsing, or segmenting all the objects within a noisily tagged image and identifying their categories (i.e. tags). Different from the traditional image parsing that takes pixel-level labels as strong supervisory information, our noisily tagged image parsing is provided with noisy tags of all the images (i.e. image-level labels), which is a natural setting for social image collections (e.g. Flickr). By oversegmenting all the images into regions, we formulate noisily tagged image parsing as a weakly supervised sparse learning problem over all the regions, where the initial labels of each region are inferred from image-level labels. Furthermore, we develop an efficient algorithm to solve such weakly supervised sparse learning problem. The experimental results on two benchmark datasets show the effectiveness of our approach. More notably, the reported surprising results shed some light on answering the question: can image-level labels replace pixel-level labels (hard to access) as supervisory information for image parsing.