 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVFA: Relieving Vector Operations in Flash Attention with Global Maximum Pre-computation
Apr 14, 2026FlashAttention-style online softmax enables exact attention computation with linear memory by streaming score tiles through on-chip memory and maintaining a running maximum and normalizer. However, as attention kernels approach peak tensor-core/cube-core throughput on modern accelerators, non-matmul components of online softmax -- especially per-tile rowmax and rowsum reductions and rescale chains -- can become vector or SIMD limited and dominate latency. This paper revisits FlashAttention and proposes Vector Relieved Flash Attention (VFA), a hardware-friendly method that reduces rowmax-driven updates of the running maximum while retaining the online-softmax structure. VFA initializes the running maximum via a cheap approximation from key-block representations, reorders key-block traversal to prioritize high-impact sink and local blocks, and freezes the maximum for remaining blocks to avoid repeated reductions and rescaling. We further integrate VFA with block-sparse skipping methods such as BLASST to form Vector Relieved Sparse Attention (VSA), which reduces both block count and per-block overhead. Notably, VFA and VSA completely avoid the conditional rescale operation in the update stage used in FA4.0. Extensive evaluations on benchmarks including MMLU and MATH500, together with attention statistics, verify our design: (i) sink and local reordering stabilizes the running maximum early; (ii) simple Q and K block summaries fail due to intra-block heterogeneity; (iii) m-initialization is required when maxima appear in middle blocks. Overall, VFA and VSA efficiently alleviate online-softmax reduction bottlenecks without performance loss. Compared to the C16V32 baseline, C8V32, C4V32 and C4V16 achieve nearly two times speedup on modern hardware while hitting the vector bottleneck. With upcoming architecture improvements, C4V16 will deliver six times speedup by enhancing exponent capacity.
OSC: Hardware Efficient W4A4 Quantization via Outlier Separation in Channel Dimension
Apr 14, 2026While 4-bit quantization is essential for high-throughput deployment of Large Language Models, activation outliers often lead to significant accuracy degradation due to the restricted dynamic range of low-bit formats. In this paper, we systematically investigate the spatial distribution of outliers and demonstrate a token-persistent structural clustering effect, where high-magnitude outliers consistently occupy fixed channels across tokens. Building on this insight, we propose OSC, a hardware-efficient framework for outlier suppression. During inference, OSC executes a dual-path computation consisting of a low-precision 4-bit General Matrix Multiplication (GEMM) path and a high-precision 16-bit branch GEMM path. Specifically, OSC uses an offline group-wise strategy to identify the channels where outliers are located and then performs structured sub-tensor extraction to coalesce these scattered activation channels into a compact dense tensor online. This mechanism implements outlier protection through regularized and high-throughput GEMM operations, achieving a seamless fit with modern 4-bit micro-scaling hardware. Furthermore, for the inputs of W2 where outlier clustering is less pronounced, we integrate a fallback strategy to FP8. Evaluation on Qwen3-8B and Qwen3-30B restricts the average accuracy drop to 2.19 and 1.12 points, respectively. Notably, OSC is highly hardware-friendly, achieving a peak speedup of 1.78x over the W8A8 GEMM baseline on a modern AI accelerator.
A Versatile Framework for Analyzing Galaxy Image Data by Implanting Human-in-the-loop on a Large Vision Model
May 17, 2024The exponential growth of astronomical datasets provides an unprecedented opportunity for humans to gain insight into the Universe. However, effectively analyzing this vast amount of data poses a significant challenge. Astronomers are turning to deep learning techniques to address this, but the methods are limited by their specific training sets, leading to considerable duplicate workloads too. Hence, as an example to present how to overcome the issue, we built a framework for general analysis of galaxy images, based on a large vision model (LVM) plus downstream tasks (DST), including galaxy morphological classification, image restoration, object detection, parameter extraction, and more. Considering the low signal-to-noise ratio of galaxy images and the imbalanced distribution of galaxy categories, we have incorporated a Human-in-the-loop (HITL) module into our large vision model, which leverages human knowledge to enhance the reliability and interpretability of processing galaxy images interactively. The proposed framework exhibits notable few-shot learning capabilities and versatile adaptability to all the abovementioned tasks on galaxy images in the DESI legacy imaging surveys. Expressly, for object detection, trained by 1000 data points, our DST upon the LVM achieves an accuracy of 96.7%, while ResNet50 plus Mask R-CNN gives an accuracy of 93.1%; for morphology classification, to obtain AUC ~0.9, LVM plus DST and HITL only requests 1/50 training sets compared to ResNet18. Expectedly, multimodal data can be integrated similarly, which opens up possibilities for conducting joint analyses with datasets spanning diverse domains in the era of multi-message astronomy.
A Multimodal Ecological Civilization Pattern Recommendation Method Based on Large Language Models and Knowledge Graph
Oct 29, 2023



The Ecological Civilization Pattern Recommendation System (ECPRS) aims to recommend suitable ecological civilization patterns for target regions, promoting sustainable development and reducing regional disparities. However, the current representative recommendation methods are not suitable for recommending ecological civilization patterns in a geographical context. There are two reasons for this. Firstly, regions have spatial heterogeneity, and the (ECPRS)needs to consider factors like climate, topography, vegetation, etc., to recommend civilization patterns adapted to specific ecological environments, ensuring the feasibility and practicality of the recommendations. Secondly, the abstract features of the ecological civilization patterns in the real world have not been fully utilized., resulting in poor richness in their embedding representations and consequently, lower performance of the recommendation system. Considering these limitations, we propose the ECPR-MML method. Initially, based on the novel method UGPIG, we construct a knowledge graph to extract regional representations incorporating spatial heterogeneity features. Following that, inspired by the significant progress made by Large Language Models (LLMs) in the field of Natural Language Processing (NLP), we employ Large LLMs to generate multimodal features for ecological civilization patterns in the form of text and images. We extract and integrate these multimodal features to obtain semantically rich representations of ecological civilization. Through extensive experiments, we validate the performance of our ECPR-MML model. Our results show that F1@5 is 2.11% higher compared to state-of-the-art models, 2.02% higher than NGCF, and 1.16% higher than UGPIG. Furthermore, multimodal data can indeed enhance recommendation performance. However, the data generated by LLM is not as effective as real data to a certain extent.
Unveiling Optimal SDG Pathways: An Innovative Approach Leveraging Graph Pruning and Intent Graph for Effective Recommendations
Sep 21, 2023



The recommendation of appropriate development pathways, also known as ecological civilization patterns for achieving Sustainable Development Goals (namely, sustainable development patterns), are of utmost importance for promoting ecological, economic, social, and resource sustainability in a specific region. To achieve this, the recommendation process must carefully consider the region's natural, environmental, resource, and economic characteristics. However, current recommendation algorithms in the field of computer science fall short in adequately addressing the spatial heterogeneity related to environment and sparsity of regional historical interaction data, which limits their effectiveness in recommending sustainable development patterns. To overcome these challenges, this paper proposes a method called User Graph after Pruning and Intent Graph (UGPIG). Firstly, we utilize the high-density linking capability of the pruned User Graph to address the issue of spatial heterogeneity neglect in recommendation algorithms. Secondly, we construct an Intent Graph by incorporating the intent network, which captures the preferences for attributes including environmental elements of target regions. This approach effectively alleviates the problem of sparse historical interaction data in the region. Through extensive experiments, we demonstrate that UGPIG outperforms state-of-the-art recommendation algorithms like KGCN, KGAT, and KGIN in sustainable development pattern recommendations, with a maximum improvement of 9.61% in Top-3 recommendation performance.
Identifying outliers in astronomical images with unsupervised machine learning
May 19, 2022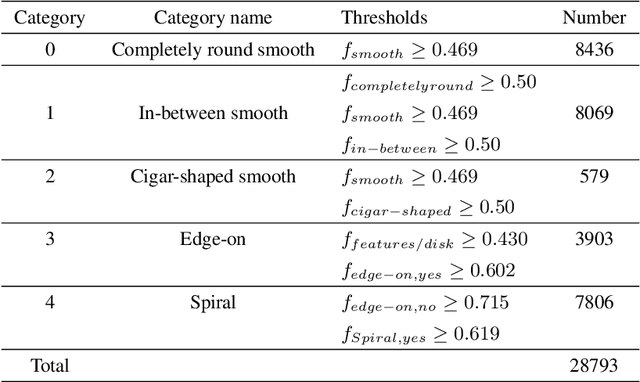
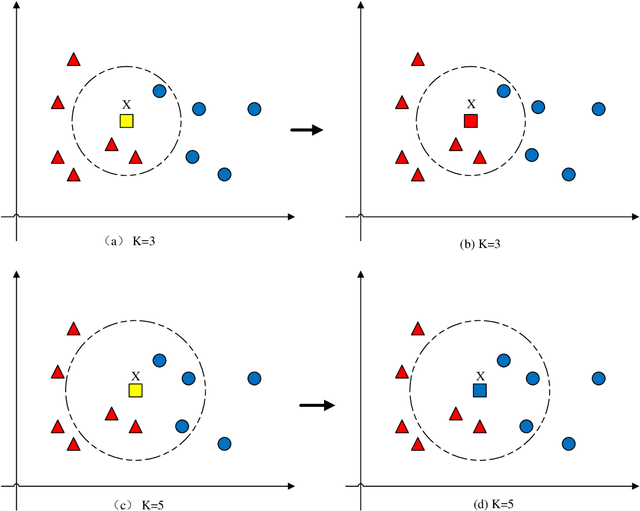
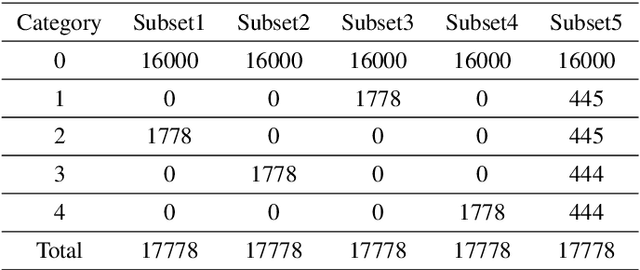
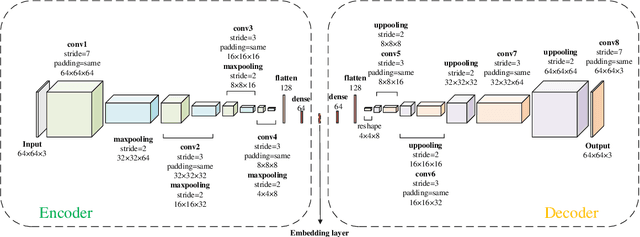
Astronomical outliers, such as unusual, rare or unknown types of astronomical objects or phenomena, constantly lead to the discovery of genuinely unforeseen knowledge in astronomy. More unpredictable outliers will be uncovered in principle with the increment of the coverage and quality of upcoming survey data. However, it is a severe challenge to mine rare and unexpected targets from enormous data with human inspection due to a significant workload. Supervised learning is also unsuitable for this purpose since designing proper training sets for unanticipated signals is unworkable. Motivated by these challenges, we adopt unsupervised machine learning approaches to identify outliers in the data of galaxy images to explore the paths for detecting astronomical outliers. For comparison, we construct three methods, which are built upon the k-nearest neighbors (KNN), Convolutional Auto-Encoder (CAE)+ KNN, and CAE + KNN + Attention Mechanism (attCAE KNN) separately. Testing sets are created based on the Galaxy Zoo image data published online to evaluate the performance of the above methods. Results show that attCAE KNN achieves the best recall (78%), which is 53% higher than the classical KNN method and 22% higher than CAE+KNN. The efficiency of attCAE KNN (10 minutes) is also superior to KNN (4 hours) and equal to CAE+KNN(10 minutes) for accomplishing the same task. Thus, we believe it is feasible to detect astronomical outliers in the data of galaxy images in an unsupervised manner. Next, we will apply attCAE KNN to available survey datasets to assess its applicability and reliability.