 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhi Tang
ConvMath: A Convolutional Sequence Network for Mathematical Expression Recognition
Dec 23, 2020
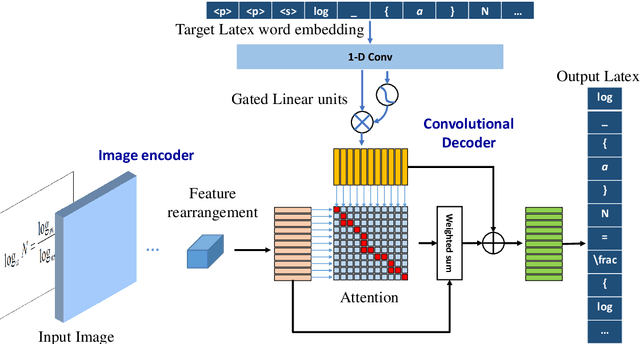
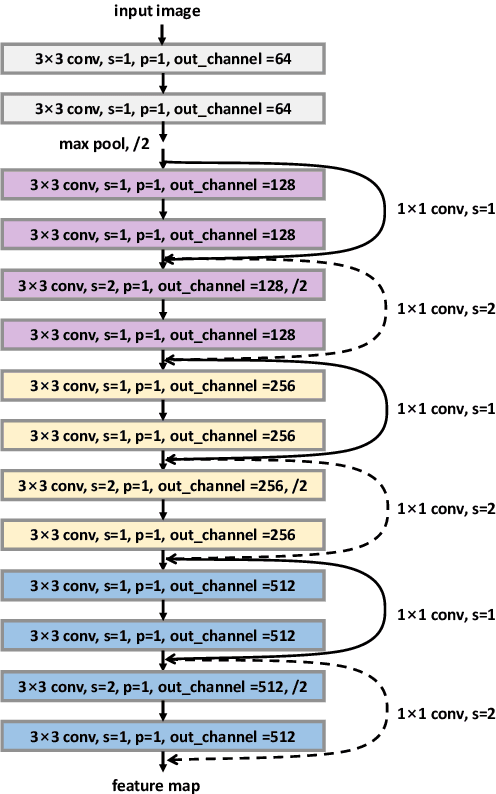
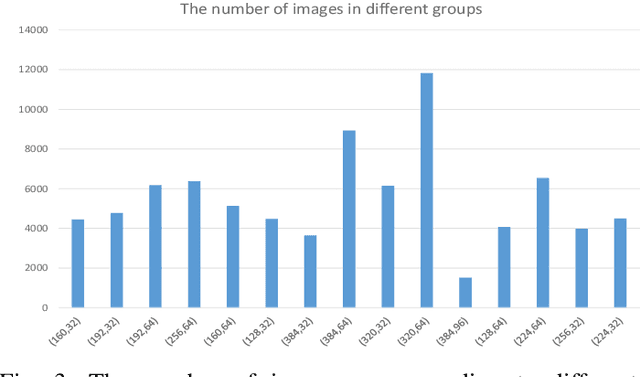

Despite the recent advances in optical character recognition (OCR), mathematical expressions still face a great challenge to recognize due to their two-dimensional graphical layout. In this paper, we propose a convolutional sequence modeling network, ConvMath, which converts the mathematical expression description in an image into a LaTeX sequence in an end-to-end way. The network combines an image encoder for feature extraction and a convolutional decoder for sequence generation. Compared with other Long Short Term Memory(LSTM) based encoder-decoder models, ConvMath is entirely based on convolution, thus it is easy to perform parallel computation. Besides, the network adopts multi-layer attention mechanism in the decoder, which allows the model to align output symbols with source feature vectors automatically, and alleviates the problem of lacking coverage while training the model. The performance of ConvMath is evaluated on an open dataset named IM2LATEX-100K, including 103556 samples. The experimental results demonstrate that the proposed network achieves state-of-the-art accuracy and much better efficiency than previous methods.
GSTO: Gated Scale-Transfer Operation for Multi-Scale Feature Learning in Pixel Labeling
Jun 28, 2020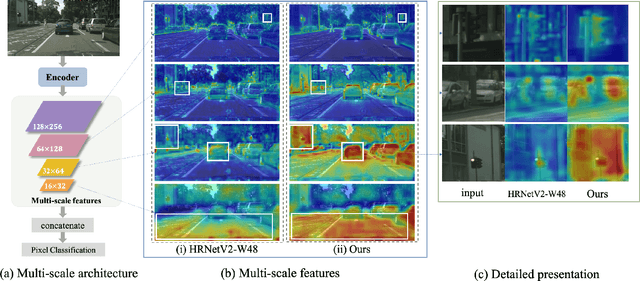
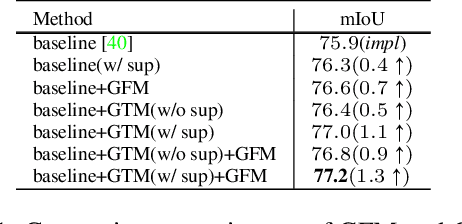
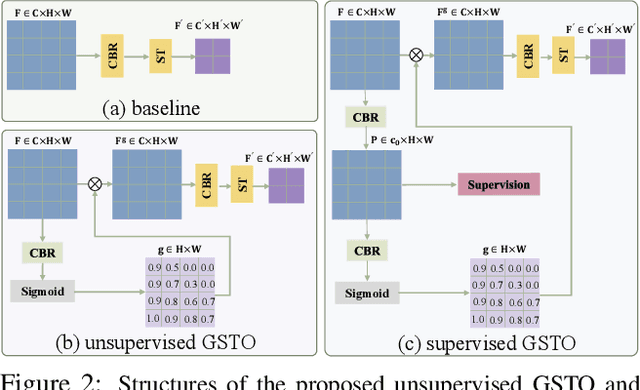
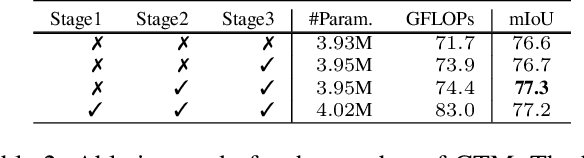
Existing CNN-based methods for pixel labeling heavily depend on multi-scale features to meet the requirements of both semantic comprehension and detail preservation. State-of-the-art pixel labeling neural networks widely exploit conventional scale-transfer operations, i.e., up-sampling and down-sampling to learn multi-scale features. In this work, we find that these operations lead to scale-confused features and suboptimal performance because they are spatial-invariant and directly transit all feature information cross scales without spatial selection. To address this issue, we propose the Gated Scale-Transfer Operation (GSTO) to properly transit spatial-filtered features to another scale. Specifically, GSTO can work either with or without extra supervision. Unsupervised GSTO is learned from the feature itself while the supervised one is guided by the supervised probability matrix. Both forms of GSTO are lightweight and plug-and-play, which can be flexibly integrated into networks or modules for learning better multi-scale features. In particular, by plugging GSTO into HRNet, we get a more powerful backbone (namely GSTO-HRNet) for pixel labeling, and it achieves new state-of-the-art results on the COCO benchmark for human pose estimation and other benchmarks for semantic segmentation including Cityscapes, LIP and Pascal Context, with negligible extra computational cost. Moreover, experiment results demonstrate that GSTO can also significantly boost the performance of multi-scale feature aggregation modules like PPM and ASPP. Code will be made available at https://github.com/VDIGPKU/GSTO.
MixTConv: Mixed Temporal Convolutional Kernels for Efficient Action Recogntion
Jan 25, 2020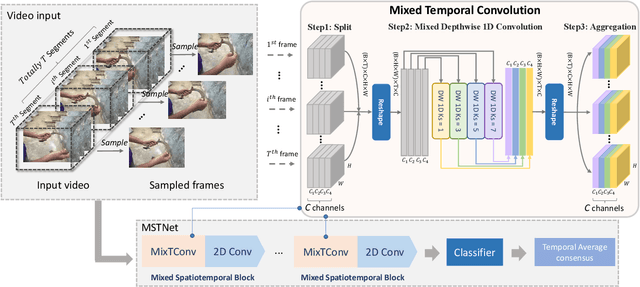
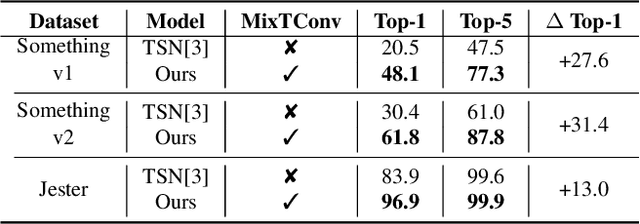
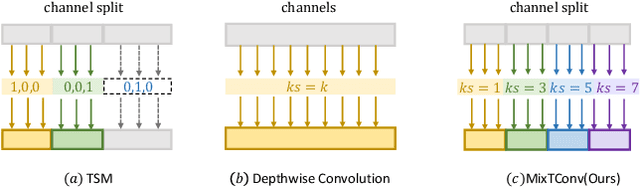
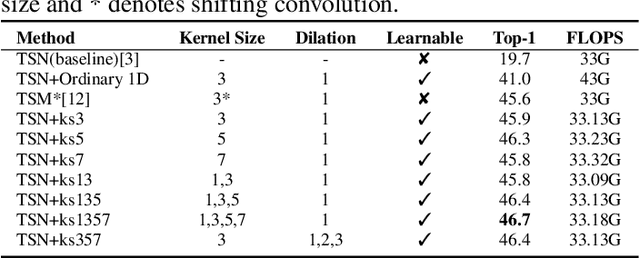
To efficiently extract spatiotemporal features of video for action recognition, most state-of-the-art methods integrate 1D temporal convolution into a conventional 2D CNN backbone. However, they all exploit 1D temporal convolution of fixed kernel size (i.e., 3) in the network building block, thus have suboptimal temporal modeling capability to handle both long-term and short-term actions. To address this problem, we first investigate the impacts of different kernel sizes for the 1D temporal convolutional filters. Then, we propose a simple yet efficient operation called Mixed Temporal Convolution (MixTConv), which consists of multiple depthwise 1D convolutional filters with different kernel sizes. By plugging MixTConv into the conventional 2D CNN backbone ResNet-50, we further propose an efficient and effective network architecture named MSTNet for action recognition, and achieve state-of-the-art results on multiple benchmarks.
MFPN: A Novel Mixture Feature Pyramid Network of Multiple Architectures for Object Detection
Dec 20, 2019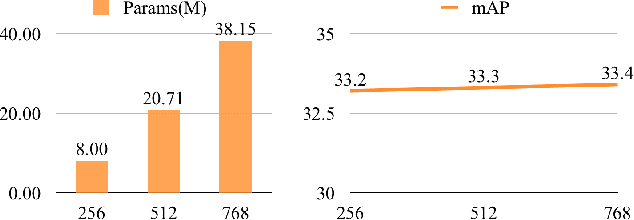
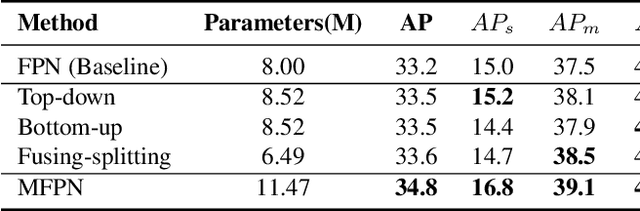
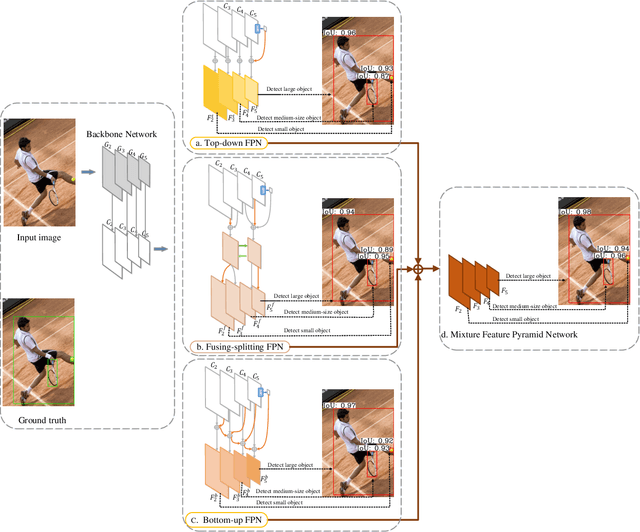
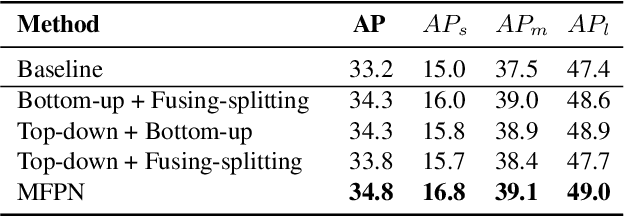
Feature pyramids are widely exploited in many detectors to solve the scale variation problem for object detection. In this paper, we first investigate the Feature Pyramid Network (FPN) architectures and briefly categorize them into three typical fashions: top-down, bottom-up and fusing-splitting, which have their own merits for detecting small objects, large objects, and medium-sized objects, respectively. Further, we design three FPNs of different architectures and propose a novel Mixture Feature Pyramid Network (MFPN) which inherits the merits of all these three kinds of FPNs, by assembling the three kinds of FPNs in a parallel multi-branch architecture and mixing the features. MFPN can significantly enhance both one-stage and two-stage FPN-based detectors with about 2 percent Average Precision(AP) increment on the MS-COCO benchmark, at little sacrifice in running time latency. By simply assembling MFPN with the one-stage and two-stage baseline detectors, we achieve competitive single-model detection results on the COCO detection benchmark without bells and whistles.
Automatic Generation of Headlines for Online Math Questions
Nov 27, 2019

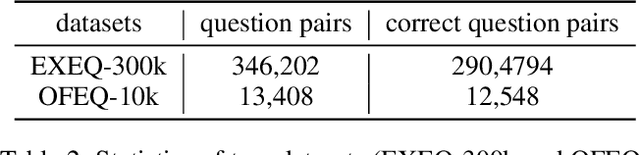
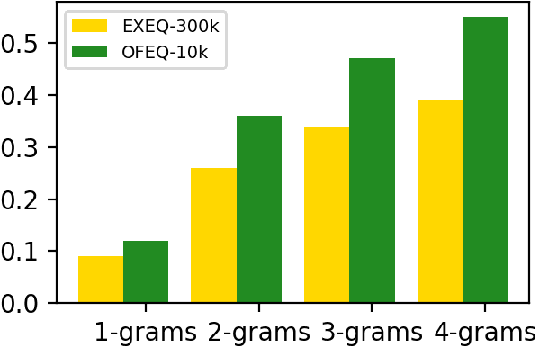
Mathematical equations are an important part of dissemination and communication of scientific information. Students, however, often feel challenged in reading and understanding math content and equations. With the development of the Web, students are posting their math questions online. Nevertheless, constructing a concise math headline that gives a good description of the posted detailed math question is nontrivial. In this study, we explore a novel summarization task denoted as geNerating A concise Math hEadline from a detailed math question (NAME). Compared to conventional summarization tasks, this task has two extra and essential constraints: 1) Detailed math questions consist of text and math equations which require a unified framework to jointly model textual and mathematical information; 2) Unlike text, math equations contain semantic and structural features, and both of them should be captured together. To address these issues, we propose MathSum, a novel summarization model which utilizes a pointer mechanism combined with a multi-head attention mechanism for mathematical representation augmentation. The pointer mechanism can either copy textual tokens or math tokens from source questions in order to generate math headlines. The multi-head attention mechanism is designed to enrich the representation of math equations by modeling and integrating both its semantic and structural features. For evaluation, we collect and make available two sets of real-world detailed math questions along with human-written math headlines, namely EXEQ-300k and OFEQ-10k. Experimental results demonstrate that our model (MathSum) significantly outperforms state-of-the-art models for both the EXEQ-300k and OFEQ-10k datasets.
CBNet: A Novel Composite Backbone Network Architecture for Object Detection
Sep 09, 2019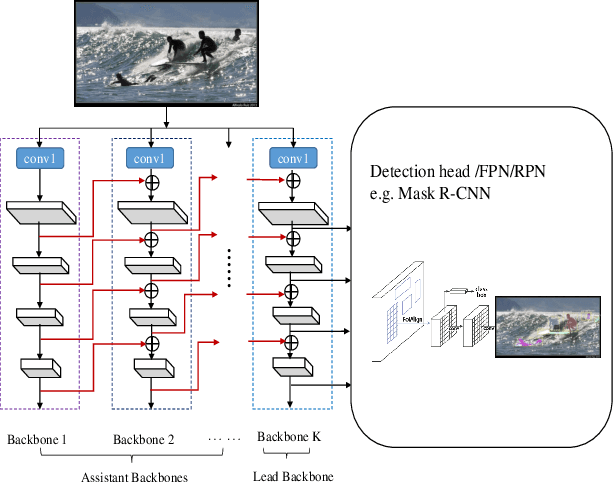
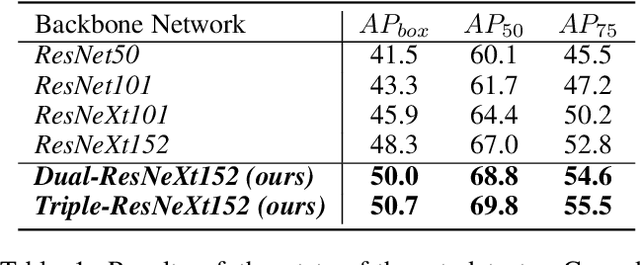
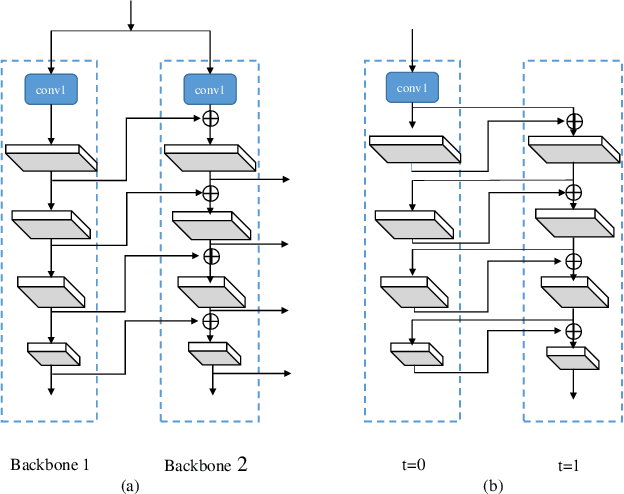
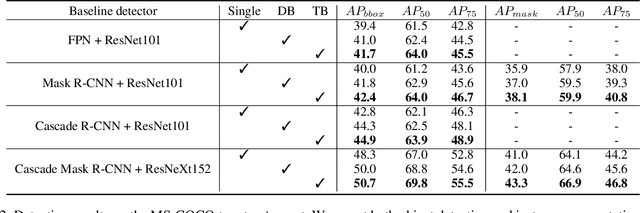
In existing CNN based detectors, the backbone network is a very important component for basic feature extraction, and the performance of the detectors highly depends on it. In this paper, we aim to achieve better detection performance by building a more powerful backbone from existing backbones like ResNet and ResNeXt. Specifically, we propose a novel strategy for assembling multiple identical backbones by composite connections between the adjacent backbones, to form a more powerful backbone named Composite Backbone Network (CBNet). In this way, CBNet iteratively feeds the output features of the previous backbone, namely high-level features, as part of input features to the succeeding backbone, in a stage-by-stage fashion, and finally the feature maps of the last backbone (named Lead Backbone) are used for object detection. We show that CBNet can be very easily integrated into most state-of-the-art detectors and significantly improve their performances. For example, it boosts the mAP of FPN, Mask R-CNN and Cascade R-CNN on the COCO dataset by about 1.5 to 3.0 percent. Meanwhile, experimental results show that the instance segmentation results can also be improved. Specially, by simply integrating the proposed CBNet into the baseline detector Cascade Mask R-CNN, we achieve a new state-of-the-art result on COCO dataset (mAP of 53.3) with single model, which demonstrates great effectiveness of the proposed CBNet architecture. Code will be made available on https://github.com/PKUbahuangliuhe/CBNet.
TGG: Transferable Graph Generation for Zero-shot and Few-shot Learning
Aug 30, 2019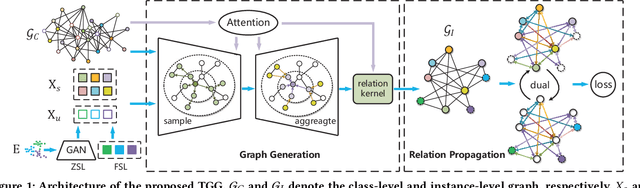
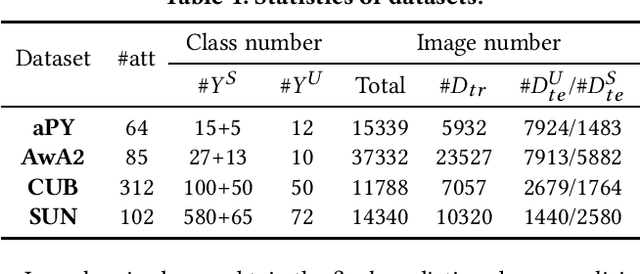
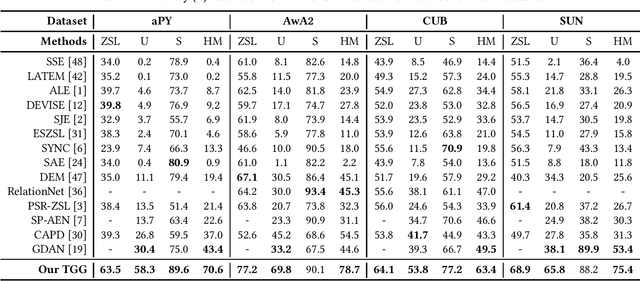
Zero-shot and few-shot learning aim to improve generalization to unseen concepts, which are promising in many realistic scenarios. Due to the lack of data in unseen domain, relation modeling between seen and unseen domains is vital for knowledge transfer in these tasks. Most existing methods capture seen-unseen relation implicitly via semantic embedding or feature generation, resulting in inadequate use of relation and some issues remain (e.g. domain shift). To tackle these challenges, we propose a Transferable Graph Generation (TGG) approach, in which the relation is modeled and utilized explicitly via graph generation. Specifically, our proposed TGG contains two main components: (1) Graph generation for relation modeling. An attention-based aggregate network and a relation kernel are proposed, which generate instance-level graph based on a class-level prototype graph and visual features. Proximity information aggregating is guided by a multi-head graph attention mechanism, where seen and unseen features synthesized by GAN are revised as node embeddings. The relation kernel further generates edges with GCN and graph kernel method, to capture instance-level topological structure while tackling data imbalance and noise. (2) Relation propagation for relation utilization. A dual relation propagation approach is proposed, where relations captured by the generated graph are separately propagated from the seen and unseen subgraphs. The two propagations learn from each other in a dual learning fashion, which performs as an adaptation way for mitigating domain shift. All components are jointly optimized with a meta-learning strategy, and our TGG acts as an end-to-end framework unifying conventional zero-shot, generalized zero-shot and few-shot learning. Extensive experiments demonstrate that it consistently surpasses existing methods of the above three fields by a significant margin.