 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIF: Asynchronous Inference Framework for Cost-Effective Pre-Ranking
Nov 17, 2025In industrial recommendation systems, pre-ranking models based on deep neural networks (DNNs) commonly adopt a sequential execution framework: feature fetching and model forward computation are triggered only after receiving candidates from the upstream retrieval stage. This design introduces inherent bottlenecks, including redundant computations of identical users/items and increased latency due to strictly sequential operations, which jointly constrain the model's capacity and system efficiency. To address these limitations, we propose the Asynchronous Inference Framework (AIF), a cost-effective computational architecture that decouples interaction-independent components, those operating within a single user or item, from real-time prediction. AIF reorganizes the model inference process by performing user-side computations in parallel with the retrieval stage and conducting item-side computations in a nearline manner. This means that interaction-independent components are calculated just once and completed before the real-time prediction phase of the pre-ranking stage. As a result, AIF enhances computational efficiency and reduces latency, freeing up resources to significantly improve the feature set and model architecture of interaction-independent components. Moreover, we delve into model design within the AIF framework, employing approximated methods for interaction-dependent components in online real-time predictions. By co-designing both the framework and the model, our solution achieves notable performance gains without significantly increasing computational and latency costs. This has enabled the successful deployment of AIF in the Taobao display advertising system.
Bidding-Aware Retrieval for Multi-Stage Consistency in Online Advertising
Aug 07, 2025Online advertising systems typically use a cascaded architecture to manage massive requests and candidate volumes, where the ranking stages allocate traffic based on eCPM (predicted CTR $\times$ Bid). With the increasing popularity of auto-bidding strategies, the inconsistency between the computationally sensitive retrieval stage and the ranking stages becomes more pronounced, as the former cannot access precise, real-time bids for the vast ad corpus. This discrepancy leads to sub-optimal platform revenue and advertiser outcomes. To tackle this problem, we propose Bidding-Aware Retrieval (BAR), a model-based retrieval framework that addresses multi-stage inconsistency by incorporating ad bid value into the retrieval scoring function. The core innovation is Bidding-Aware Modeling, incorporating bid signals through monotonicity-constrained learning and multi-task distillation to ensure economically coherent representations, while Asynchronous Near-Line Inference enables real-time updates to the embedding for market responsiveness. Furthermore, the Task-Attentive Refinement module selectively enhances feature interactions to disentangle user interest and commercial value signals. Extensive offline experiments and full-scale deployment across Alibaba's display advertising platform validated BAR's efficacy: 4.32% platform revenue increase with 22.2% impression lift for positively-operated advertisements.
Zoo-Tuning: Adaptive Transfer from a Zoo of Models
Jun 29, 2021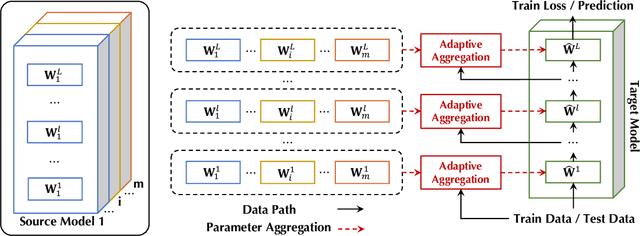
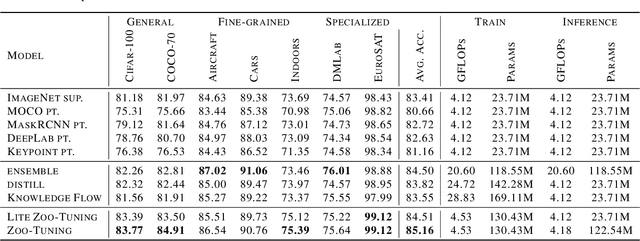
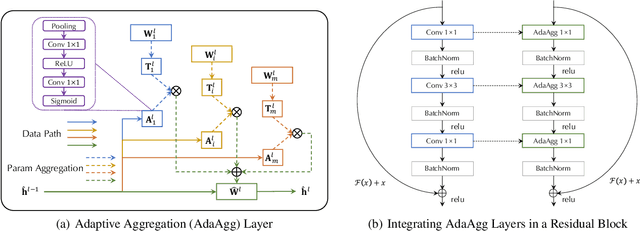
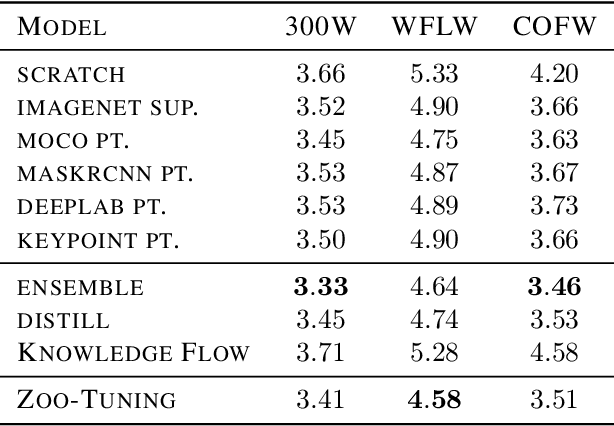
With the development of deep networks on various large-scale datasets, a large zoo of pretrained models are available. When transferring from a model zoo, applying classic single-model based transfer learning methods to each source model suffers from high computational burden and cannot fully utilize the rich knowledge in the zoo. We propose \emph{Zoo-Tuning} to address these challenges, which learns to adaptively transfer the parameters of pretrained models to the target task. With the learnable channel alignment layer and adaptive aggregation layer, Zoo-Tuning \emph{adaptively aggregates channel aligned pretrained parameters} to derive the target model, which promotes knowledge transfer by simultaneously adapting multiple source models to downstream tasks. The adaptive aggregation substantially reduces the computation cost at both training and inference. We further propose lite Zoo-Tuning with the temporal ensemble of batch average gating values to reduce the storage cost at the inference time. We evaluate our approach on a variety of tasks, including reinforcement learning, image classification, and facial landmark detection. Experiment results demonstrate that the proposed adaptive transfer learning approach can transfer knowledge from a zoo of models more effectively and efficiently.
Bi-tuning of Pre-trained Representations
Nov 12, 2020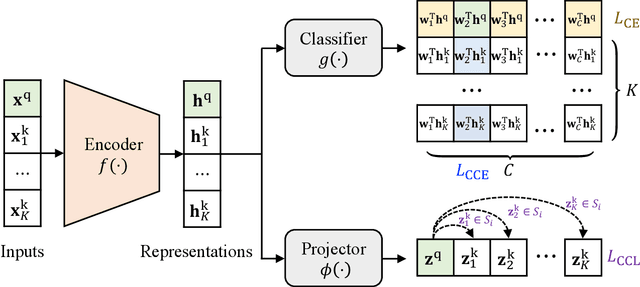
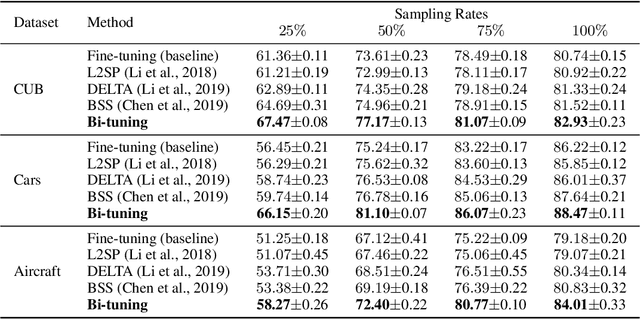
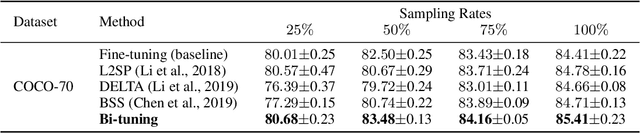
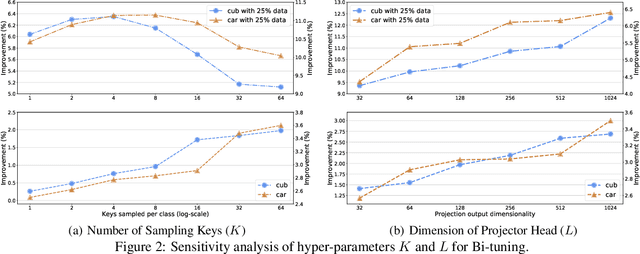
It is common within the deep learning community to first pre-train a deep neural network from a large-scale dataset and then fine-tune the pre-trained model to a specific downstream task. Recently, both supervised and unsupervised pre-training approaches to learning representations have achieved remarkable advances, which exploit the discriminative knowledge of labels and the intrinsic structure of data, respectively. It follows natural intuition that both discriminative knowledge and intrinsic structure of the downstream task can be useful for fine-tuning, however, existing fine-tuning methods mainly leverage the former and discard the latter. A question arises: How to fully explore the intrinsic structure of data for boosting fine-tuning? In this paper, we propose Bi-tuning, a general learning framework to fine-tuning both supervised and unsupervised pre-trained representations to downstream tasks. Bi-tuning generalizes the vanilla fine-tuning by integrating two heads upon the backbone of pre-trained representations: a classifier head with an improved contrastive cross-entropy loss to better leverage the label information in an instance-contrast way, and a projector head with a newly-designed categorical contrastive learning loss to fully exploit the intrinsic structure of data in a category-consistent way. Comprehensive experiments confirm that Bi-tuning achieves state-of-the-art results for fine-tuning tasks of both supervised and unsupervised pre-trained models by large margins (e.g. 10.7\% absolute rise in accuracy on CUB in low-data regime).