 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Affinity based Pseudo Labeling for Semi-supervised Person Re-identification
May 16, 2018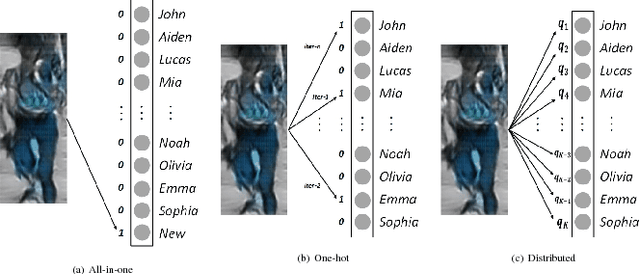
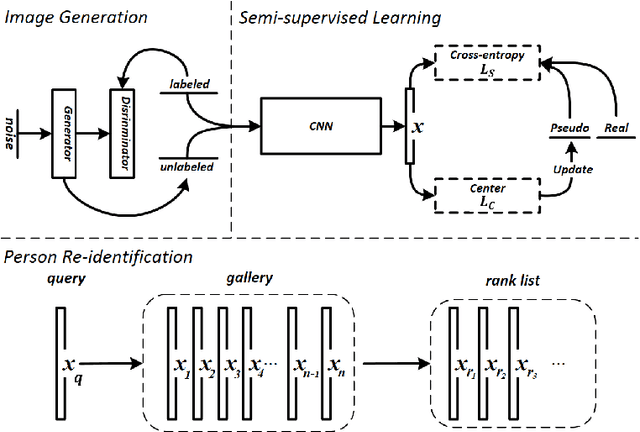
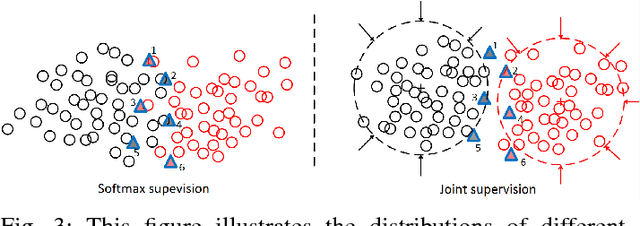

Person re-identification aims to match a person's identity across multiple camera streams. Deep neural networks have been successfully applied to the challenging person re-identification task. One remarkable bottleneck is that the existing deep models are data hungry and require large amounts of labeled training data. Acquiring manual annotations for pedestrian identity matchings in large-scale surveillance camera installations is a highly cumbersome task. Here, we propose the first semi-supervised approach that performs pseudo-labeling by considering complex relationships between unlabeled and labeled training samples in the feature space. Our approach first approximates the actual data manifold by learning a generative model via adversarial training. Given the trained model, data augmentation can be performed by generating new synthetic data samples which are unlabeled. An open research problem is how to effectively use this additional data for improved feature learning. To this end, this work proposes a novel Feature Affinity based Pseudo-Labeling (FAPL) approach with two possible label encodings under a unified setting. Our approach measures the affinity of unlabeled samples with the underlying clusters of labeled data samples using the intermediate feature representations from deep networks. FAPL trains with the joint supervision of cross-entropy loss together with a center regularization term, which not only ensures discriminative feature representation learning but also simultaneously predicts pseudo-labels for unlabeled data. Our extensive experiments on two standard large-scale datasets, Market-1501 and DukeMTMC-reID, demonstrate significant performance boosts over closely related competitors and outperforms state-of-the-art person re-identification techniques in most cases.
Let Features Decide for Themselves: Feature Mask Network for Person Re-identification
Nov 20, 2017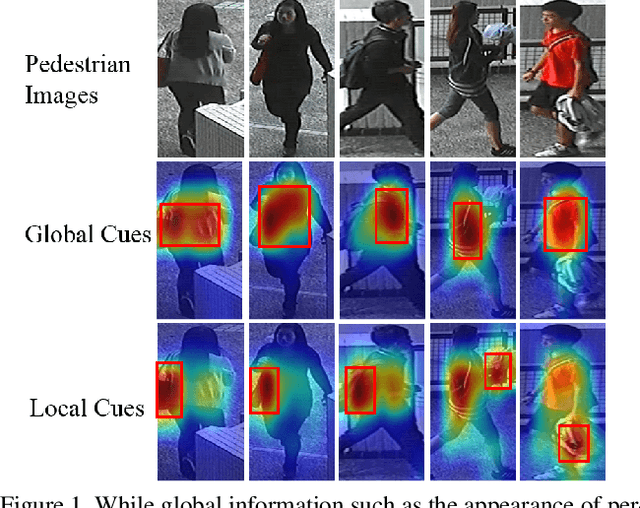

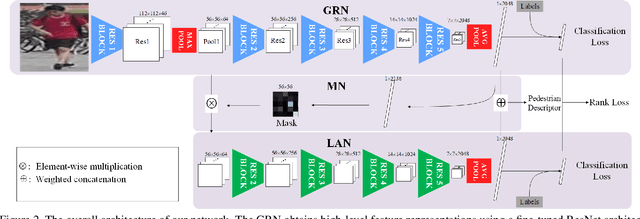
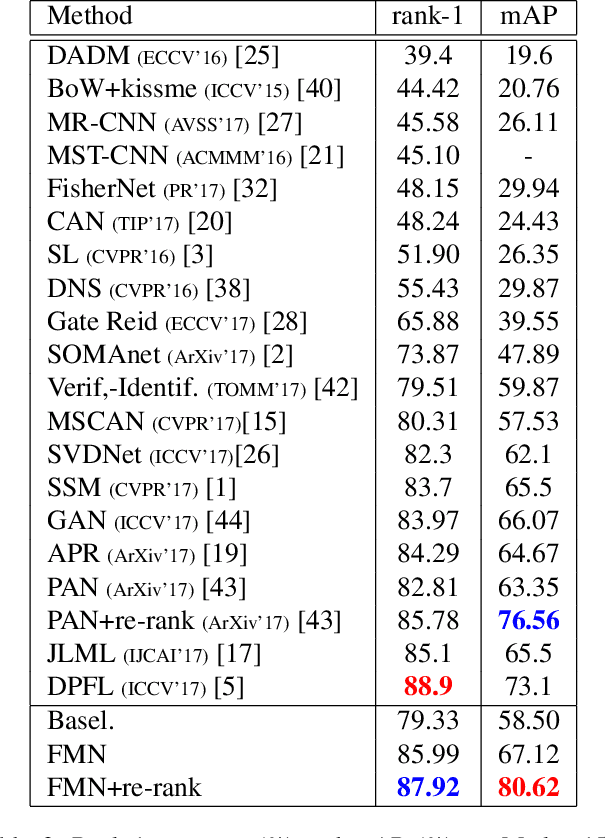
Person re-identification aims at establishing the identity of a pedestrian from a gallery that contains images of multiple people obtained from a multi-camera system. Many challenges such as occlusions, drastic lighting and pose variations across the camera views, indiscriminate visual appearances, cluttered backgrounds, imperfect detections, motion blur, and noise make this task highly challenging. While most approaches focus on learning features and metrics to derive better representations, we hypothesize that both local and global contextual cues are crucial for an accurate identity matching. To this end, we propose a Feature Mask Network (FMN) that takes advantage of ResNet high-level features to predict a feature map mask and then imposes it on the low-level features to dynamically reweight different object parts for a locally aware feature representation. This serves as an effective attention mechanism by allowing the network to focus on local details selectively. Given the resemblance of person re-identification with classification and retrieval tasks, we frame the network training as a multi-task objective optimization, which further improves the learned feature descriptions. We conduct experiments on Market-1501, DukeMTMC-reID and CUHK03 datasets, where the proposed approach respectively achieves significant improvements of $5.3\%$, $9.1\%$ and $10.7\%$ in mAP measure relative to the state-of-the-art.
Towards Automatic Construction of Diverse, High-quality Image Dataset
Aug 22, 2017
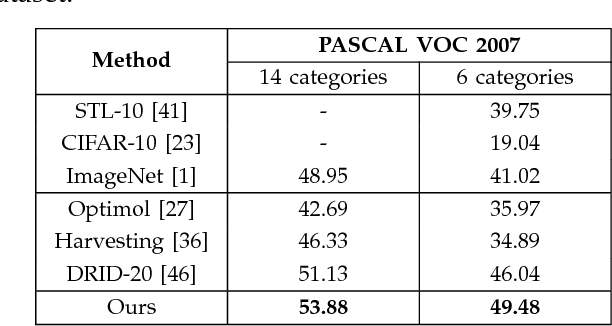
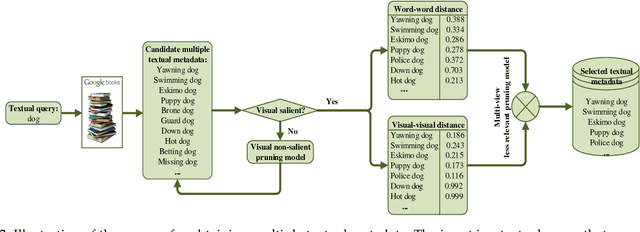
The availability of labeled image datasets has been shown critical for high-level image understanding, which continuously drives the progress of feature designing and models developing. However, constructing labeled image datasets is laborious and monotonous. To eliminate manual annotation, in this work, we propose a novel image dataset construction framework by employing multiple textual metadata. We aim at collecting diverse and accurate images for given queries from the Web. Specifically, we formulate noisy textual metadata removing and noisy images filtering as a multi-view and multi-instance learning problem separately. Our proposed approach not only improves the accuracy but also enhances the diversity of the selected images. To verify the effectiveness of our proposed approach, we construct an image dataset with 100 categories. The experiments show significant performance gains by using the generated data of our approach on several tasks, such as image classification, cross-dataset generalization, and object detection. The proposed method also consistently outperforms existing weakly supervised and web-supervised approaches.
Exploiting Web Images for Dataset Construction: A Domain Robust Approach
Mar 28, 2017
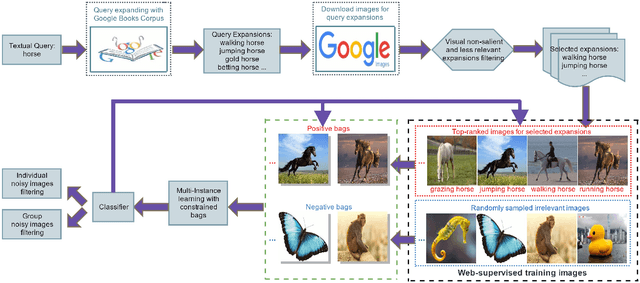
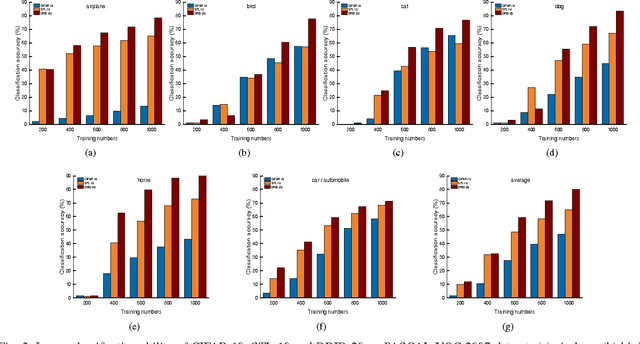
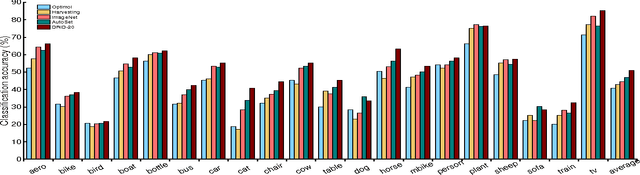
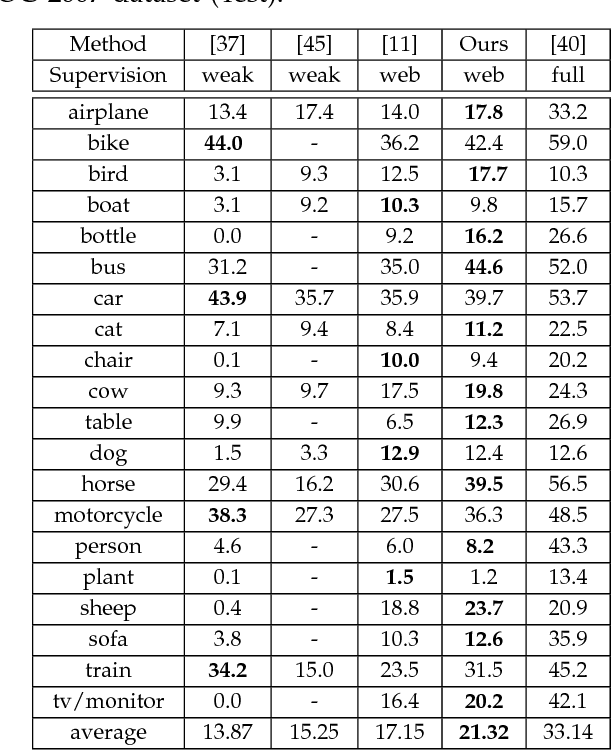
Labelled image datasets have played a critical role in high-level image understanding. However, the process of manual labelling is both time-consuming and labor intensive. To reduce the cost of manual labelling, there has been increased research interest in automatically constructing image datasets by exploiting web images. Datasets constructed by existing methods tend to have a weak domain adaptation ability, which is known as the "dataset bias problem". To address this issue, we present a novel image dataset construction framework that can be generalized well to unseen target domains. Specifically, the given queries are first expanded by searching the Google Books Ngrams Corpus to obtain a rich semantic description, from which the visually non-salient and less relevant expansions are filtered out. By treating each selected expansion as a "bag" and the retrieved images as "instances", image selection can be formulated as a multi-instance learning problem with constrained positive bags. We propose to solve the employed problems by the cutting-plane and concave-convex procedure (CCCP) algorithm. By using this approach, images from different distributions can be kept while noisy images are filtered out. To verify the effectiveness of our proposed approach, we build an image dataset with 20 categories. Extensive experiments on image classification, cross-dataset generalization, diversity comparison and object detection demonstrate the domain robustness of our dataset.
Refining Image Categorization by Exploiting Web Images and General Corpus
Mar 16, 2017
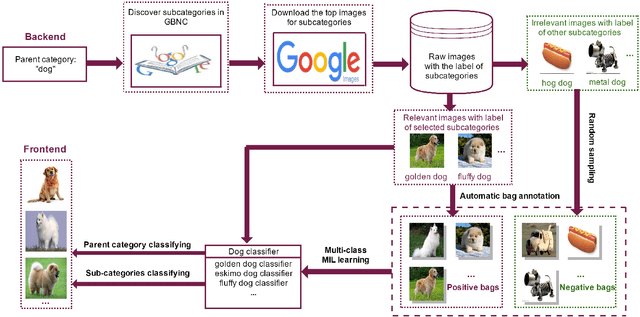
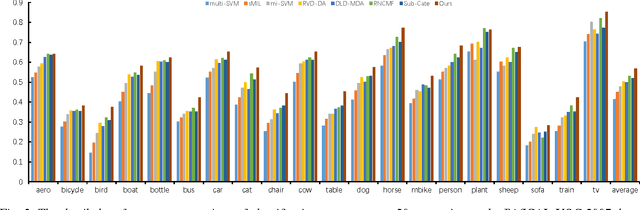
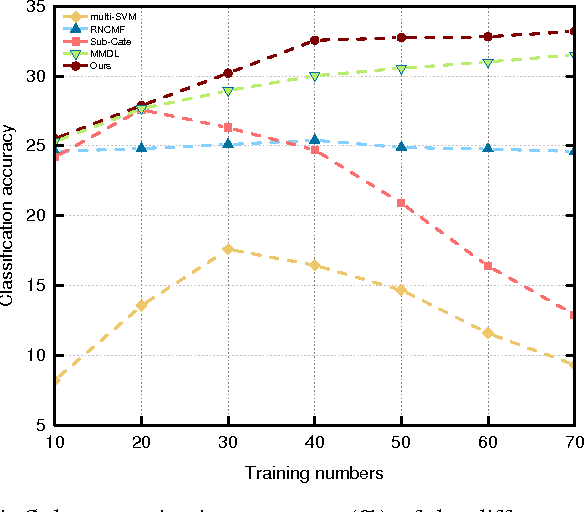
Studies show that refining real-world categories into semantic subcategories contributes to better image modeling and classification. Previous image sub-categorization work relying on labeled images and WordNet's hierarchy is not only labor-intensive, but also restricted to classify images into NOUN subcategories. To tackle these problems, in this work, we exploit general corpus information to automatically select and subsequently classify web images into semantic rich (sub-)categories. The following two major challenges are well studied: 1) noise in the labels of subcategories derived from the general corpus; 2) noise in the labels of images retrieved from the web. Specifically, we first obtain the semantic refinement subcategories from the text perspective and remove the noise by the relevance-based approach. To suppress the search error induced noisy images, we then formulate image selection and classifier learning as a multi-class multi-instance learning problem and propose to solve the employed problem by the cutting-plane algorithm. The experiments show significant performance gains by using the generated data of our way on both image categorization and sub-categorization tasks. The proposed approach also consistently outperforms existing weakly supervised and web-supervised approaches.
Hashing on Nonlinear Manifolds
Dec 02, 2014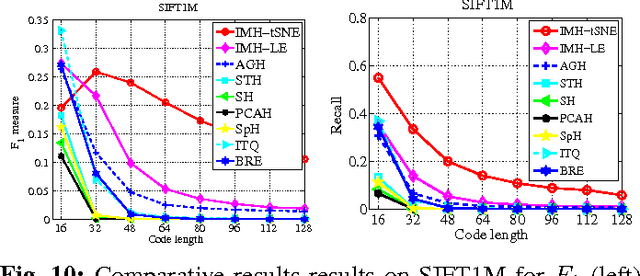

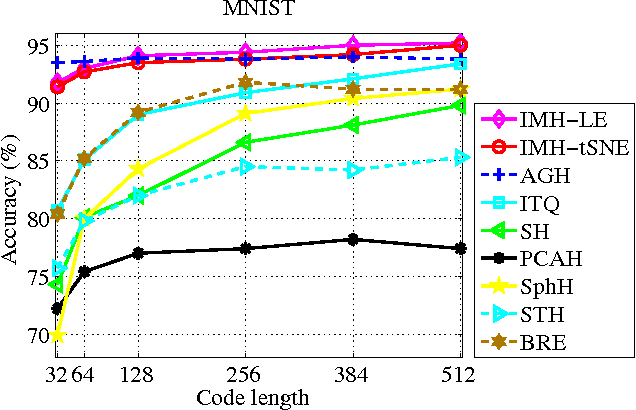
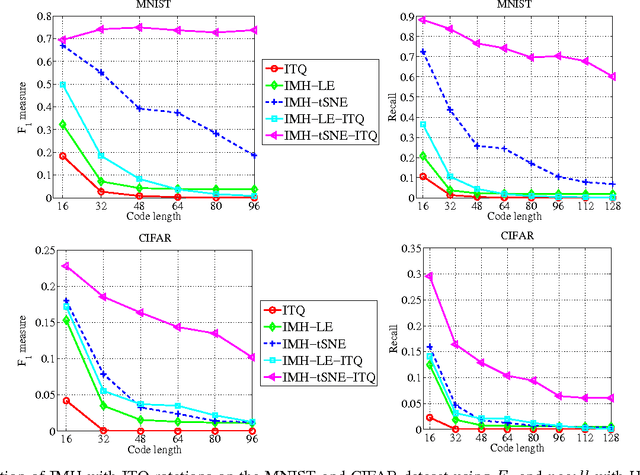
Learning based hashing methods have attracted considerable attention due to their ability to greatly increase the scale at which existing algorithms may operate. Most of these methods are designed to generate binary codes preserving the Euclidean similarity in the original space. Manifold learning techniques, in contrast, are better able to model the intrinsic structure embedded in the original high-dimensional data. The complexities of these models, and the problems with out-of-sample data, have previously rendered them unsuitable for application to large-scale embedding, however. In this work, how to learn compact binary embeddings on their intrinsic manifolds is considered. In order to address the above-mentioned difficulties, an efficient, inductive solution to the out-of-sample data problem, and a process by which non-parametric manifold learning may be used as the basis of a hashing method is proposed. The proposed approach thus allows the development of a range of new hashing techniques exploiting the flexibility of the wide variety of manifold learning approaches available. It is particularly shown that hashing on the basis of t-SNE outperforms state-of-the-art hashing methods on large-scale benchmark datasets, and is very effective for image classification with very short code lengths. The proposed hashing framework is shown to be easily improved, for example, by minimizing the quantization error with learned orthogonal rotations. In addition, a supervised inductive manifold hashing framework is developed by incorporating the label information, which is shown to greatly advance the semantic retrieval performance.
Fast Approximate L_infty Minimization: Speeding Up Robust Regression
Apr 04, 2013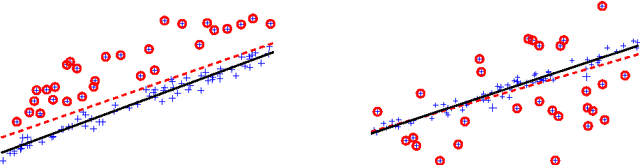


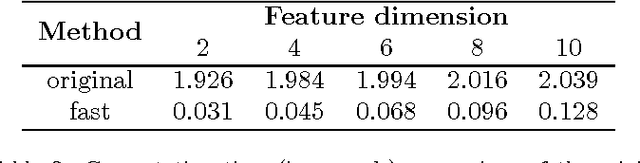
Minimization of the $L_\infty$ norm, which can be viewed as approximately solving the non-convex least median estimation problem, is a powerful method for outlier removal and hence robust regression. However, current techniques for solving the problem at the heart of $L_\infty$ norm minimization are slow, and therefore cannot scale to large problems. A new method for the minimization of the $L_\infty$ norm is presented here, which provides a speedup of multiple orders of magnitude for data with high dimension. This method, termed Fast $L_\infty$ Minimization, allows robust regression to be applied to a class of problems which were previously inaccessible. It is shown how the $L_\infty$ norm minimization problem can be broken up into smaller sub-problems, which can then be solved extremely efficiently. Experimental results demonstrate the radical reduction in computation time, along with robustness against large numbers of outliers in a few model-fitting problems.
Inductive Hashing on Manifolds
Mar 28, 2013
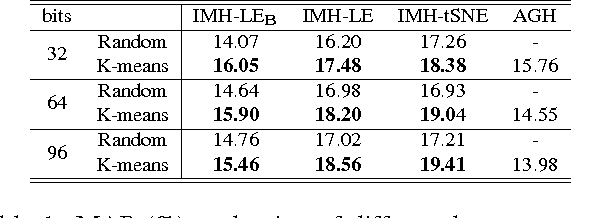
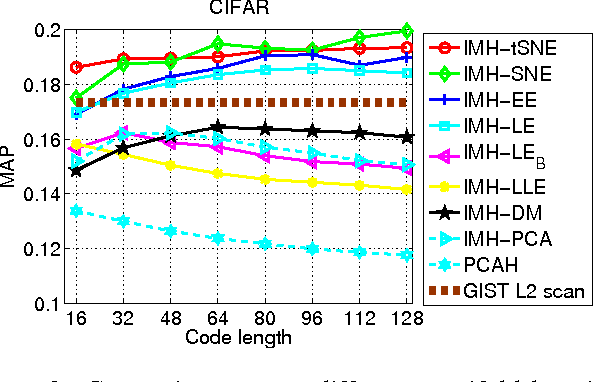
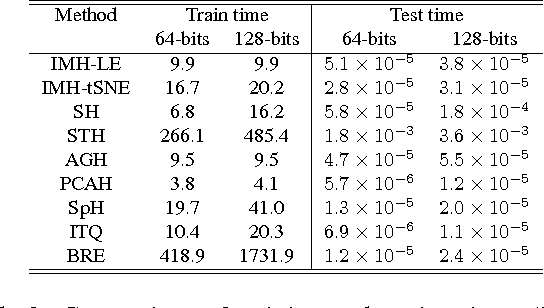
Learning based hashing methods have attracted considerable attention due to their ability to greatly increase the scale at which existing algorithms may operate. Most of these methods are designed to generate binary codes that preserve the Euclidean distance in the original space. Manifold learning techniques, in contrast, are better able to model the intrinsic structure embedded in the original high-dimensional data. The complexity of these models, and the problems with out-of-sample data, have previously rendered them unsuitable for application to large-scale embedding, however. In this work, we consider how to learn compact binary embeddings on their intrinsic manifolds. In order to address the above-mentioned difficulties, we describe an efficient, inductive solution to the out-of-sample data problem, and a process by which non-parametric manifold learning may be used as the basis of a hashing method. Our proposed approach thus allows the development of a range of new hashing techniques exploiting the flexibility of the wide variety of manifold learning approaches available. We particularly show that hashing on the basis of t-SNE .