 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-agnostic Decision Transformer for Multi-type Agent Control with Federated Split Training
May 22, 2024



With the rapid advancements in artificial intelligence, the development of knowledgeable and personalized agents has become increasingly prevalent. However, the inherent variability in state variables and action spaces among personalized agents poses significant aggregation challenges for traditional federated learning algorithms. To tackle these challenges, we introduce the Federated Split Decision Transformer (FSDT), an innovative framework designed explicitly for AI agent decision tasks. The FSDT framework excels at navigating the intricacies of personalized agents by harnessing distributed data for training while preserving data privacy. It employs a two-stage training process, with local embedding and prediction models on client agents and a global transformer decoder model on the server. Our comprehensive evaluation using the benchmark D4RL dataset highlights the superior performance of our algorithm in federated split learning for personalized agents, coupled with significant reductions in communication and computational overhead compared to traditional centralized training approaches. The FSDT framework demonstrates strong potential for enabling efficient and privacy-preserving collaborative learning in applications such as autonomous driving decision systems. Our findings underscore the efficacy of the FSDT framework in effectively leveraging distributed offline reinforcement learning data to enable powerful multi-type agent decision systems.
Leveraging Causal Inference for Explainable Automatic Program Repair
Jun 06, 2022
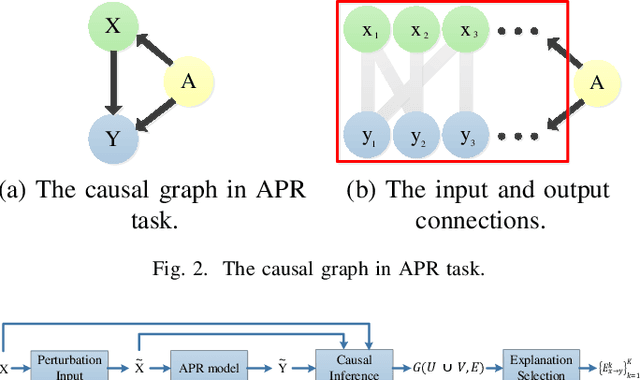
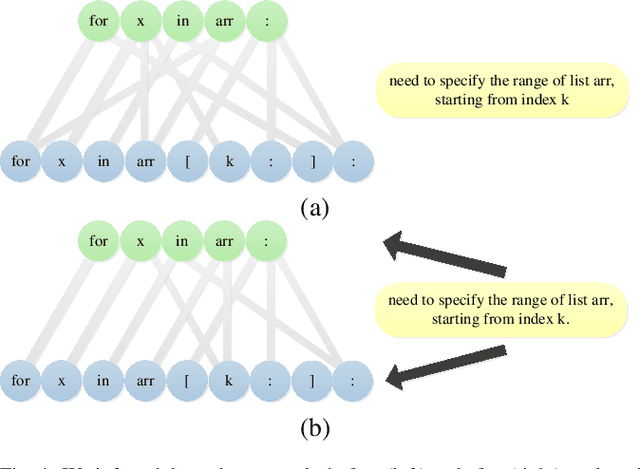
Deep learning models have made significant progress in automatic program repair. However, the black-box nature of these methods has restricted their practical applications. To address this challenge, this paper presents an interpretable approach for program repair based on sequence-to-sequence models with causal inference and our method is called CPR, short for causal program repair. Our CPR can generate explanations in the process of decision making, which consists of groups of causally related input-output tokens. Firstly, our method infers these relations by querying the model with inputs disturbed by data augmentation. Secondly, it generates a graph over tokens from the responses and solves a partitioning problem to select the most relevant components. The experiments on four programming languages (Java, C, Python, and JavaScript) show that CPR can generate causal graphs for reasonable interpretations and boost the performance of bug fixing in automatic program repair.
DT-SV: A Transformer-based Time-domain Approach for Speaker Verification
May 26, 2022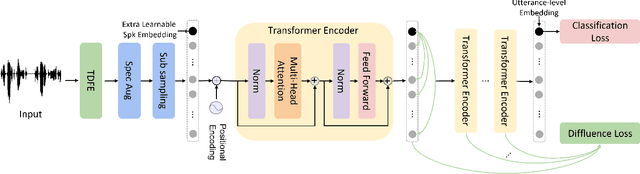
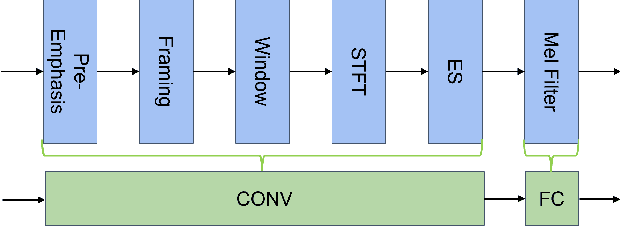
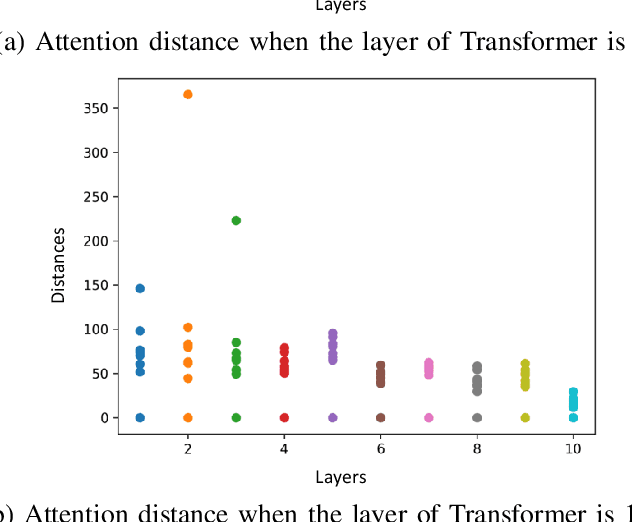
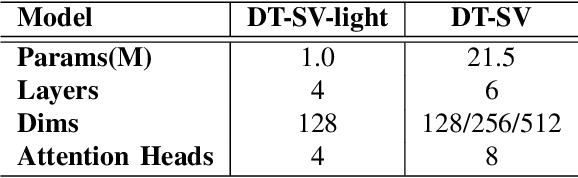
Speaker verification (SV) aims to determine whether the speaker's identity of a test utterance is the same as the reference speech. In the past few years, extracting speaker embeddings using deep neural networks for SV systems has gone mainstream. Recently, different attention mechanisms and Transformer networks have been explored widely in SV fields. However, utilizing the original Transformer in SV directly may have frame-level information waste on output features, which could lead to restrictions on capacity and discrimination of speaker embeddings. Therefore, we propose an approach to derive utterance-level speaker embeddings via a Transformer architecture that uses a novel loss function named diffluence loss to integrate the feature information of different Transformer layers. Therein, the diffluence loss aims to aggregate frame-level features into an utterance-level representation, and it could be integrated into the Transformer expediently. Besides, we also introduce a learnable mel-fbank energy feature extractor named time-domain feature extractor that computes the mel-fbank features more precisely and efficiently than the standard mel-fbank extractor. Combining Diffluence loss and Time-domain feature extractor, we propose a novel Transformer-based time-domain SV model (DT-SV) with faster training speed and higher accuracy. Experiments indicate that our proposed model can achieve better performance in comparison with other models.
QSpeech: Low-Qubit Quantum Speech Application Toolkit
May 26, 2022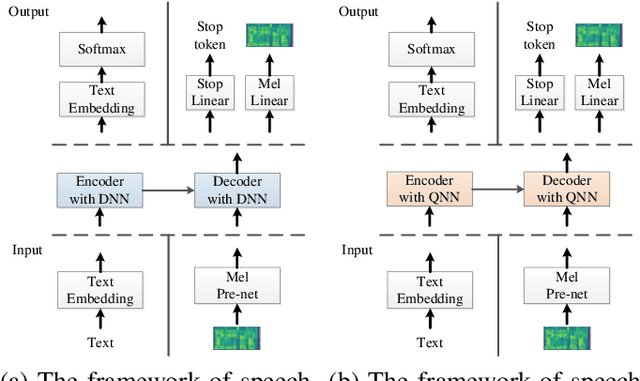
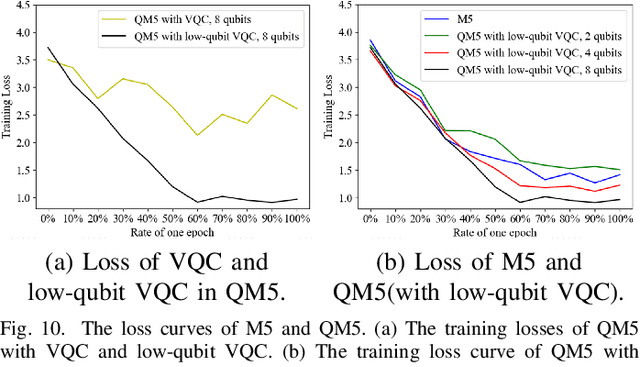
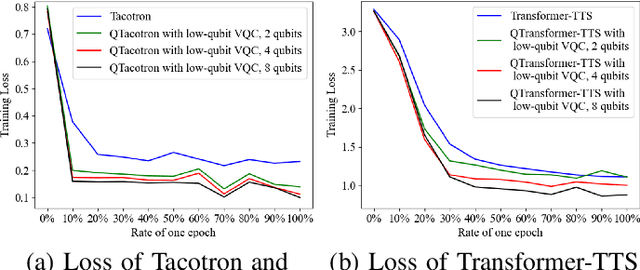
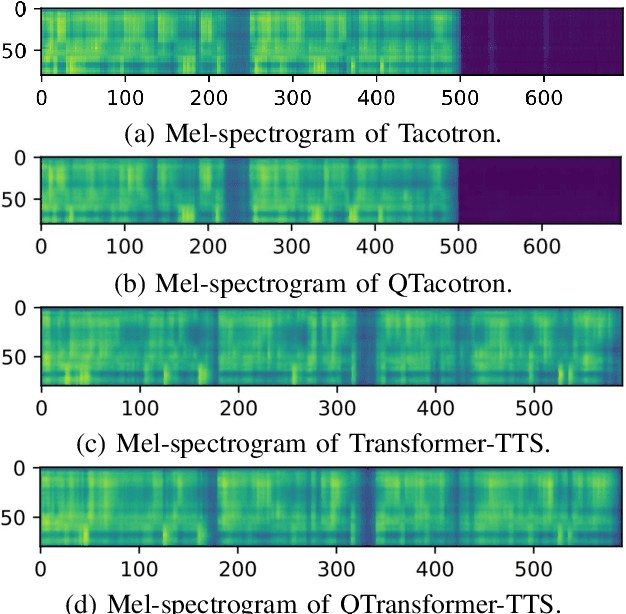
Quantum devices with low qubits are common in the Noisy Intermediate-Scale Quantum (NISQ) era. However, Quantum Neural Network (QNN) running on low-qubit quantum devices would be difficult since it is based on Variational Quantum Circuit (VQC), which requires many qubits. Therefore, it is critical to make QNN with VQC run on low-qubit quantum devices. In this study, we propose a novel VQC called the low-qubit VQC. VQC requires numerous qubits based on the input dimension; however, the low-qubit VQC with linear transformation can liberate this condition. Thus, it allows the QNN to run on low-qubit quantum devices for speech applications. Furthermore, as compared to the VQC, our proposed low-qubit VQC can stabilize the training process more. Based on the low-qubit VQC, we implement QSpeech, a library for quick prototyping of hybrid quantum-classical neural networks in the speech field. It has numerous quantum neural layers and QNN models for speech applications. Experiments on Speech Command Recognition and Text-to-Speech show that our proposed low-qubit VQC outperforms VQC and is more stable.
Federated Learning with Dynamic Transformer for Text to Speech
Jul 09, 2021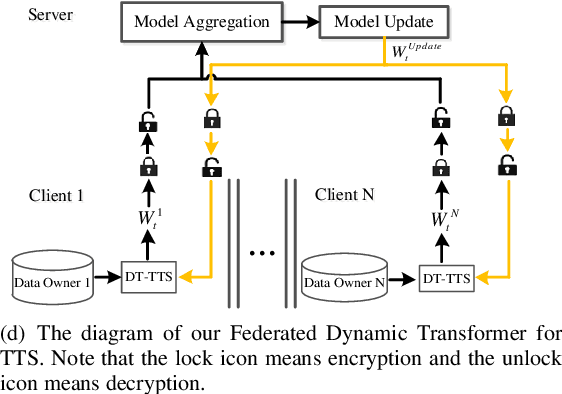

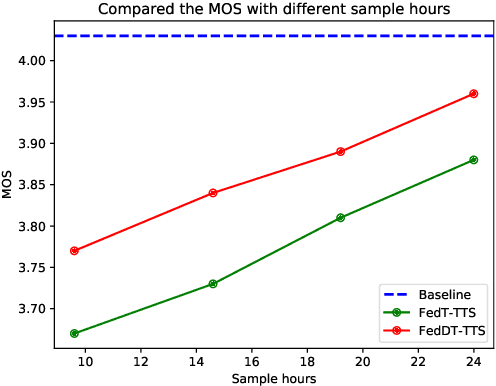
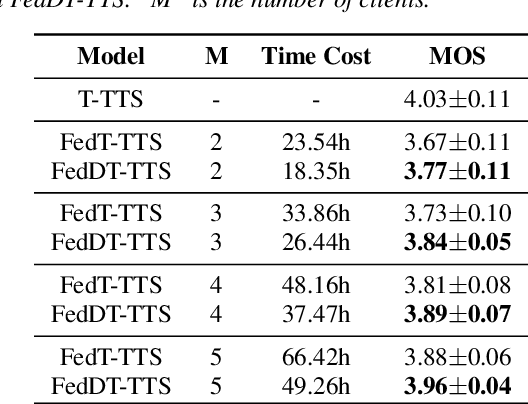
Text to speech (TTS) is a crucial task for user interaction, but TTS model training relies on a sizable set of high-quality original datasets. Due to privacy and security issues, the original datasets are usually unavailable directly. Recently, federated learning proposes a popular distributed machine learning paradigm with an enhanced privacy protection mechanism. It offers a practical and secure framework for data owners to collaborate with others, thus obtaining a better global model trained on the larger dataset. However, due to the high complexity of transformer models, the convergence process becomes slow and unstable in the federated learning setting. Besides, the transformer model trained in federated learning is costly communication and limited computational speed on clients, impeding its popularity. To deal with these challenges, we propose the federated dynamic transformer. On the one hand, the performance is greatly improved comparing with the federated transformer, approaching centralize-trained Transformer-TTS when increasing clients number. On the other hand, it achieves faster and more stable convergence in the training phase and significantly reduces communication time. Experiments on the LJSpeech dataset also strongly prove our method's advantage.