 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOONSHOT : A Framework for Multi-Objective Pruning of Vision and Large Language Models
Apr 14, 2026Weight pruning is a common technique for compressing large neural networks. We focus on the challenging post-training one-shot setting, where a pre-trained model is compressed without any retraining. Existing one-shot pruning methods typically optimize a single objective, such as a layer-wise reconstruction loss or a second-order Taylor approximation of the training loss. We highlight that neither objective alone is consistently the most effective across architectures and sparsity levels. Motivated by this insight, we propose MOONSHOT, a general and flexible framework that extends any single-objective pruning method into a multi-objective formulation by jointly optimizing both the layer-wise reconstruction error and second-order Taylor approximation of the training loss. MOONSHOT acts as a wrapper around existing pruning algorithms. To enable this integration while maintaining scalability to billion-parameter models, we propose modeling decisions and introduce an efficient procedure for computing the inverse Hessian, preserving the efficiency of state-of-the-art one-shot pruners. When combined with state-of-the-art pruning methods on Llama-3.2 and Llama-2 models, MOONSHOT reduces C4 perplexity by up to 32.6% at 2:4 sparsity and improves zero-shot mean accuracy across seven classification benchmarks by up to 4.9 points. On Vision Transformers, it improves accuracy on ImageNet-1k by over 5 points at 70% sparsity, and on ResNet-50, it yields a 4-point gain at 90% sparsity.
An Optimization Framework for Differentially Private Sparse Fine-Tuning
Mar 17, 2025
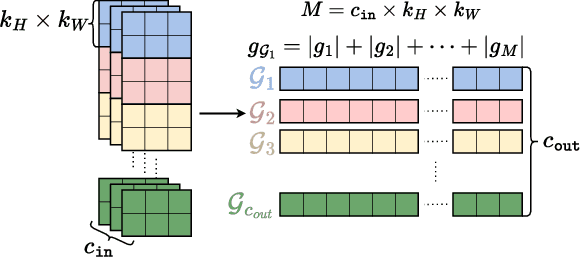
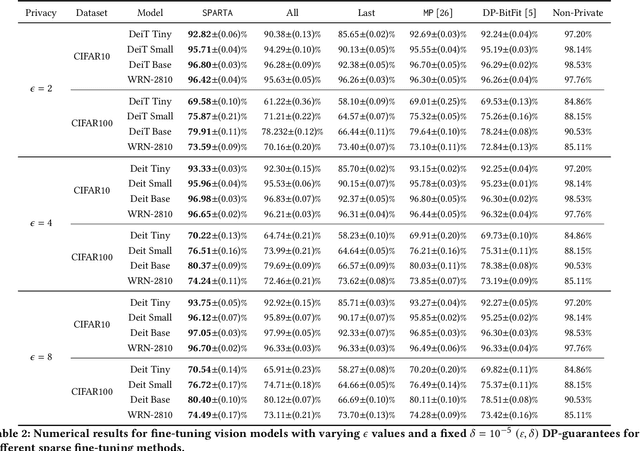
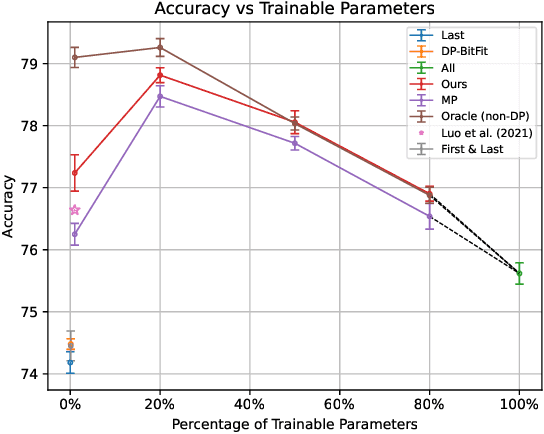
Differentially private stochastic gradient descent (DP-SGD) is broadly considered to be the gold standard for training and fine-tuning neural networks under differential privacy (DP). With the increasing availability of high-quality pre-trained model checkpoints (e.g., vision and language models), fine-tuning has become a popular strategy. However, despite recent progress in understanding and applying DP-SGD for private transfer learning tasks, significant challenges remain -- most notably, the performance gap between models fine-tuned with DP-SGD and their non-private counterparts. Sparse fine-tuning on private data has emerged as an alternative to full-model fine-tuning; recent work has shown that privately fine-tuning only a small subset of model weights and keeping the rest of the weights fixed can lead to better performance. In this work, we propose a new approach for sparse fine-tuning of neural networks under DP. Existing work on private sparse finetuning often used fixed choice of trainable weights (e.g., updating only the last layer), or relied on public model's weights to choose the subset of weights to modify. Such choice of weights remains suboptimal. In contrast, we explore an optimization-based approach, where our selection method makes use of the private gradient information, while using off the shelf privacy accounting techniques. Our numerical experiments on several computer vision models and datasets show that our selection method leads to better prediction accuracy, compared to full-model private fine-tuning or existing private sparse fine-tuning approaches.