 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRating Multi-Modal Time-Series Forecasting Models (MM-TSFM) for Robustness Through a Causal Lens
Jun 12, 2024



AI systems are notorious for their fragility; minor input changes can potentially cause major output swings. When such systems are deployed in critical areas like finance, the consequences of their uncertain behavior could be severe. In this paper, we focus on multi-modal time-series forecasting, where imprecision due to noisy or incorrect data can lead to erroneous predictions, impacting stakeholders such as analysts, investors, and traders. Recently, it has been shown that beyond numeric data, graphical transformations can be used with advanced visual models to achieve better performance. In this context, we introduce a rating methodology to assess the robustness of Multi-Modal Time-Series Forecasting Models (MM-TSFM) through causal analysis, which helps us understand and quantify the isolated impact of various attributes on the forecasting accuracy of MM-TSFM. We apply our novel rating method on a variety of numeric and multi-modal forecasting models in a large experimental setup (six input settings of control and perturbations, ten data distributions, time series from six leading stocks in three industries over a year of data, and five time-series forecasters) to draw insights on robust forecasting models and the context of their strengths. Within the scope of our study, our main result is that multi-modal (numeric + visual) forecasting, which was found to be more accurate than numeric forecasting in previous studies, can also be more robust in diverse settings. Our work will help different stakeholders of time-series forecasting understand the models` behaviors along trust (robustness) and accuracy dimensions to select an appropriate model for forecasting using our rating method, leading to improved decision-making.
Evaluating Large Language Models on Time Series Feature Understanding: A Comprehensive Taxonomy and Benchmark
Apr 25, 2024Large Language Models (LLMs) offer the potential for automatic time series analysis and reporting, which is a critical task across many domains, spanning healthcare, finance, climate, energy, and many more. In this paper, we propose a framework for rigorously evaluating the capabilities of LLMs on time series understanding, encompassing both univariate and multivariate forms. We introduce a comprehensive taxonomy of time series features, a critical framework that delineates various characteristics inherent in time series data. Leveraging this taxonomy, we have systematically designed and synthesized a diverse dataset of time series, embodying the different outlined features. This dataset acts as a solid foundation for assessing the proficiency of LLMs in comprehending time series. Our experiments shed light on the strengths and limitations of state-of-the-art LLMs in time series understanding, revealing which features these models readily comprehend effectively and where they falter. In addition, we uncover the sensitivity of LLMs to factors including the formatting of the data, the position of points queried within a series and the overall time series length.
OVAL-Prompt: Open-Vocabulary Affordance Localization for Robot Manipulation through LLM Affordance-Grounding
Apr 17, 2024



In order for robots to interact with objects effectively, they must understand the form and function of each object they encounter. Essentially, robots need to understand which actions each object affords, and where those affordances can be acted on. Robots are ultimately expected to operate in unstructured human environments, where the set of objects and affordances is not known to the robot before deployment (i.e. the open-vocabulary setting). In this work, we introduce OVAL-Prompt, a prompt-based approach for open-vocabulary affordance localization in RGB-D images. By leveraging a Vision Language Model (VLM) for open-vocabulary object part segmentation and a Large Language Model (LLM) to ground each part-segment-affordance, OVAL-Prompt demonstrates generalizability to novel object instances, categories, and affordances without domain-specific finetuning. Quantitative experiments demonstrate that without any finetuning, OVAL-Prompt achieves localization accuracy that is competitive with supervised baseline models. Moreover, qualitative experiments show that OVAL-Prompt enables affordance-based robot manipulation of open-vocabulary object instances and categories.
From Pixels to Predictions: Spectrogram and Vision Transformer for Better Time Series Forecasting
Mar 17, 2024Time series forecasting plays a crucial role in decision-making across various domains, but it presents significant challenges. Recent studies have explored image-driven approaches using computer vision models to address these challenges, often employing lineplots as the visual representation of time series data. In this paper, we propose a novel approach that uses time-frequency spectrograms as the visual representation of time series data. We introduce the use of a vision transformer for multimodal learning, showcasing the advantages of our approach across diverse datasets from different domains. To evaluate its effectiveness, we compare our method against statistical baselines (EMA and ARIMA), a state-of-the-art deep learning-based approach (DeepAR), other visual representations of time series data (lineplot images), and an ablation study on using only the time series as input. Our experiments demonstrate the benefits of utilizing spectrograms as a visual representation for time series data, along with the advantages of employing a vision transformer for simultaneous learning in both the time and frequency domains.
Financial Time Series Forecasting using CNN and Transformer
Apr 11, 2023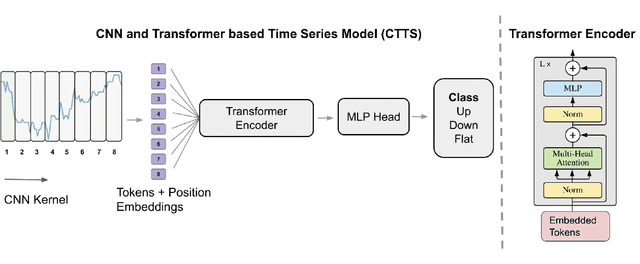
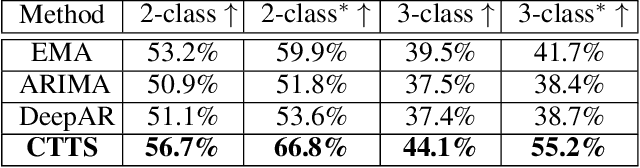
Time series forecasting is important across various domains for decision-making. In particular, financial time series such as stock prices can be hard to predict as it is difficult to model short-term and long-term temporal dependencies between data points. Convolutional Neural Networks (CNN) are good at capturing local patterns for modeling short-term dependencies. However, CNNs cannot learn long-term dependencies due to the limited receptive field. Transformers on the other hand are capable of learning global context and long-term dependencies. In this paper, we propose to harness the power of CNNs and Transformers to model both short-term and long-term dependencies within a time series, and forecast if the price would go up, down or remain the same (flat) in the future. In our experiments, we demonstrated the success of the proposed method in comparison to commonly adopted statistical and deep learning methods on forecasting intraday stock price change of S&P 500 constituents.
Self-supervised Graph Learning for Long-tailed Cognitive Diagnosis
Oct 15, 2022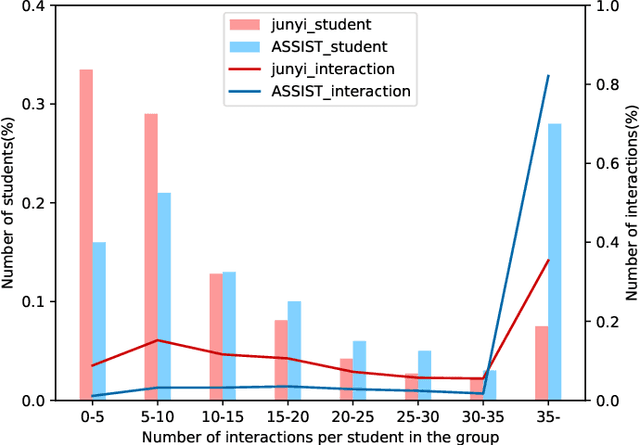
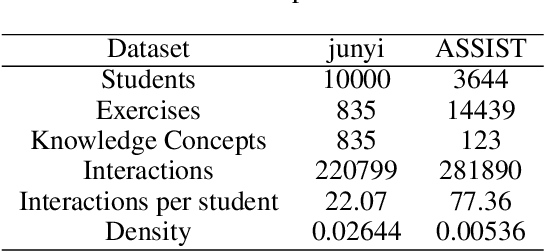
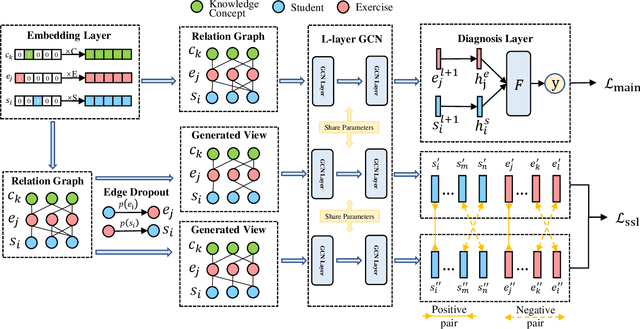
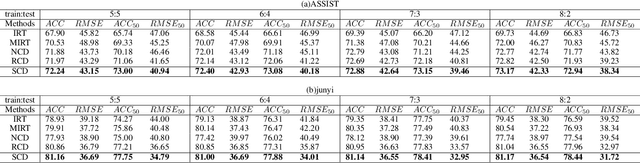
Cognitive diagnosis is a fundamental yet critical research task in the field of intelligent education, which aims to discover the proficiency level of different students on specific knowledge concepts. Despite the effectiveness of existing efforts, previous methods always considered the mastery level on the whole students, so they still suffer from the Long Tail Effect. A large number of students who have sparse data are performed poorly in the model. To relieve the situation, we proposed a Self-supervised Cognitive Diagnosis (SCD) framework which leverages the self-supervised manner to assist the graph-based cognitive diagnosis, then the performance on those students with sparse data can be improved. Specifically, we came up with a graph confusion method that drops edges under some special rules to generate different sparse views of the graph. By maximizing the consistency of the representation on the same node under different views, the model could be more focused on long-tailed students. Additionally, we proposed an importance-based view generation rule to improve the influence of long-tailed students. Extensive experiments on real-world datasets show the effectiveness of our approach, especially on the students with sparse data.
TGAVC: Improving Autoencoder Voice Conversion with Text-Guided and Adversarial Training
Aug 08, 2022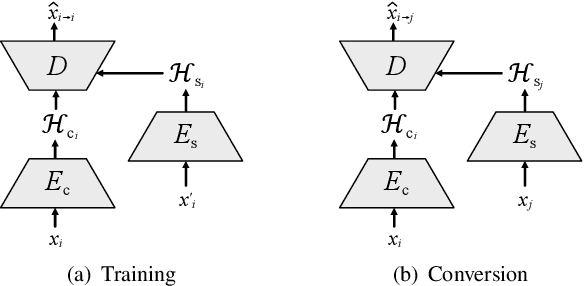
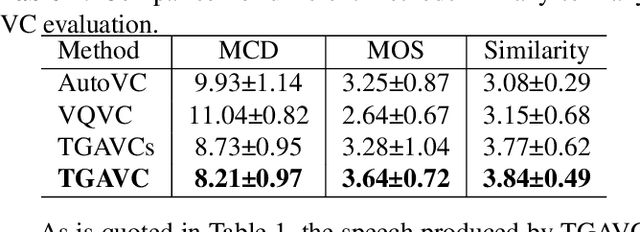
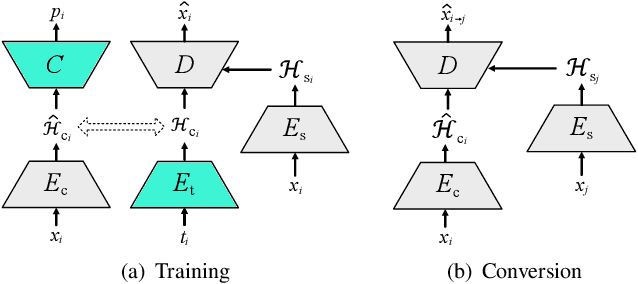

Non-parallel many-to-many voice conversion remains an interesting but challenging speech processing task. Recently, AutoVC, a conditional autoencoder based method, achieved excellent conversion results by disentangling the speaker identity and the speech content using information-constraining bottlenecks. However, due to the pure autoencoder training method, it is difficult to evaluate the separation effect of content and speaker identity. In this paper, a novel voice conversion framework, named $\boldsymbol T$ext $\boldsymbol G$uided $\boldsymbol A$utoVC(TGAVC), is proposed to more effectively separate content and timbre from speech, where an expected content embedding produced based on the text transcriptions is designed to guide the extraction of voice content. In addition, the adversarial training is applied to eliminate the speaker identity information in the estimated content embedding extracted from speech. Under the guidance of the expected content embedding and the adversarial training, the content encoder is trained to extract speaker-independent content embedding from speech. Experiments on AIShell-3 dataset show that the proposed model outperforms AutoVC in terms of naturalness and similarity of converted speech.
* ASRU 6 pages
Probabilistic Inference in Planning for Partially Observable Long Horizon Problems
Oct 18, 2021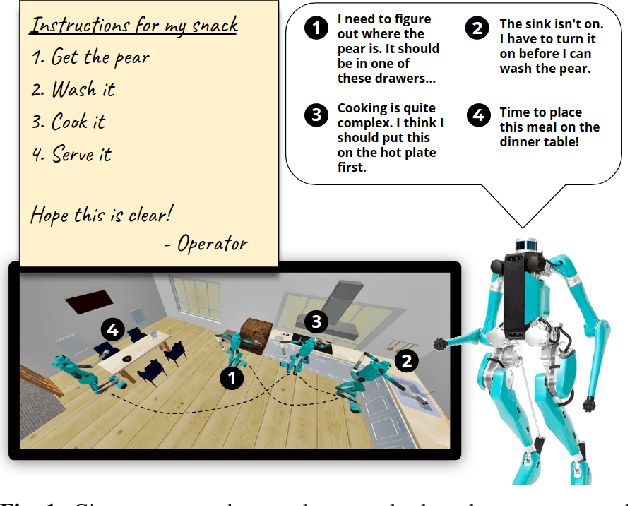
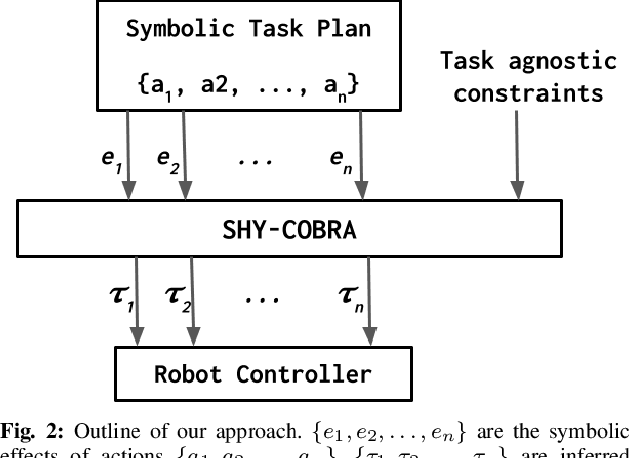
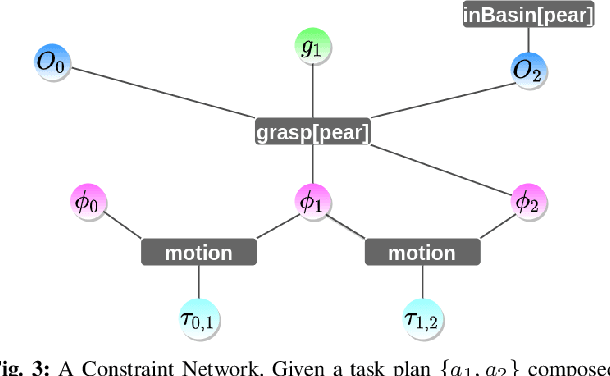
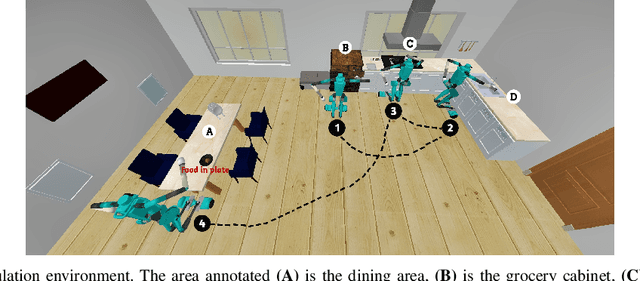
For autonomous service robots to successfully perform long horizon tasks in the real world, they must act intelligently in partially observable environments. Most Task and Motion Planning approaches assume full observability of their state space, making them ineffective in stochastic and partially observable domains that reflect the uncertainties in the real world. We propose an online planning and execution approach for performing long horizon tasks in partially observable domains. Given the robot's belief and a plan skeleton composed of symbolic actions, our approach grounds each symbolic action by inferring continuous action parameters needed to execute the plan successfully. To achieve this, we formulate the problem of joint inference of action parameters as a Hybrid Constraint Satisfaction Problem (H-CSP) and solve the H-CSP using Belief Propagation. The robot executes the resulting parameterized actions, updates its belief of the world and replans when necessary. Our approach is able to efficiently solve partially observable tasks in a realistic kitchen simulation environment. Our approach outperformed an adaptation of the state-of-the-art method across our experiments.
SeanNet: Semantic Understanding Network for Localization Under Object Dynamics
Oct 05, 2021
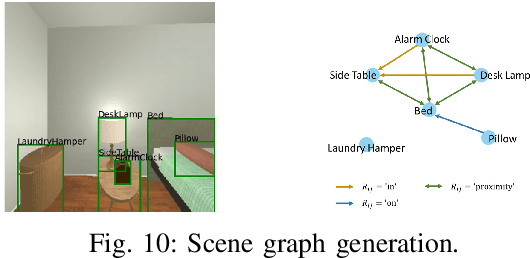
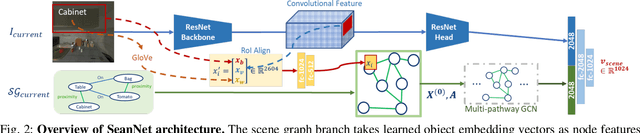

We aim for domestic robots to operate indoor for long-term service. Under the object-level scene dynamics induced by human daily activities, a robot needs to robustly localize itself in the environment subject to scene uncertainties. Previous works have addressed visual-based localization in static environments, yet the object-level scene dynamics challenge existing methods on long-term deployment of the robot. This paper proposes SEmantic understANding Network (SeanNet) that enables robots to measure the similarity between two scenes on both visual and semantic aspects. We further develop a similarity-based localization method based on SeanNet for monitoring the progress of visual navigation tasks. In our experiments, we benchmarked SeanNet against baselines methods on scene similarity measures, as well as visual navigation performance once integrated with a visual navigator. We demonstrate that SeanNet outperforms all baseline methods, by robustly localizing the robot under object dynamics, thus reliably informing visual navigation about the task status.
Visual Time Series Forecasting: An Image-driven Approach
Jul 02, 2021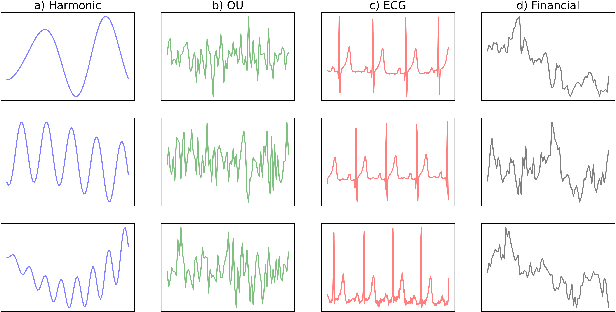
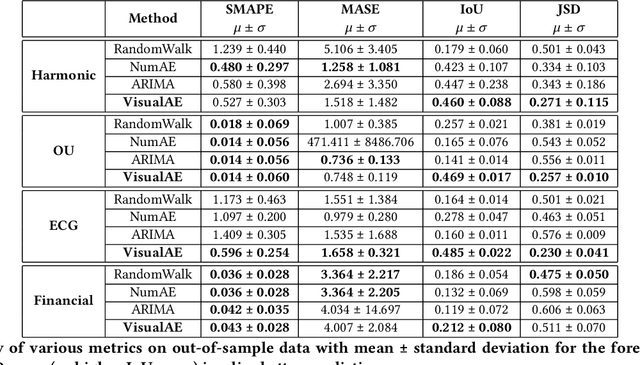
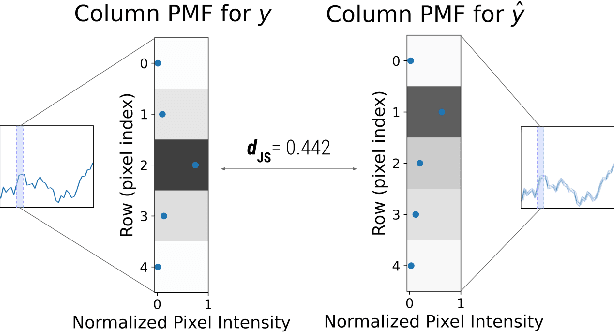
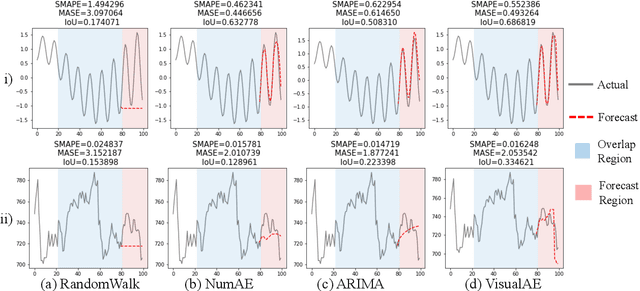
In this work, we address time-series forecasting as a computer vision task. We capture input data as an image and train a model to produce the subsequent image. This approach results in predicting distributions as opposed to pointwise values. To assess the robustness and quality of our approach, we examine various datasets and multiple evaluation metrics. Our experiments show that our forecasting tool is effective for cyclic data but somewhat less for irregular data such as stock prices. Importantly, when using image-based evaluation metrics, we find our method to outperform various baselines, including ARIMA, and a numerical variation of our deep learning approach.