 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-clue Consistency Learning to Bridge Gaps Between General and Oriented Object in Semi-supervised Detection
Jul 08, 2024



While existing semi-supervised object detection (SSOD) methods perform well in general scenes, they encounter challenges in handling oriented objects in aerial images. We experimentally find three gaps between general and oriented object detection in semi-supervised learning: 1) Sampling inconsistency: the common center sampling is not suitable for oriented objects with larger aspect ratios when selecting positive labels from labeled data. 2) Assignment inconsistency: balancing the precision and localization quality of oriented pseudo-boxes poses greater challenges which introduces more noise when selecting positive labels from unlabeled data. 3) Confidence inconsistency: there exists more mismatch between the predicted classification and localization qualities when considering oriented objects, affecting the selection of pseudo-labels. Therefore, we propose a Multi-clue Consistency Learning (MCL) framework to bridge gaps between general and oriented objects in semi-supervised detection. Specifically, considering various shapes of rotated objects, the Gaussian Center Assignment is specially designed to select the pixel-level positive labels from labeled data. We then introduce the Scale-aware Label Assignment to select pixel-level pseudo-labels instead of unreliable pseudo-boxes, which is a divide-and-rule strategy suited for objects with various scales. The Consistent Confidence Soft Label is adopted to further boost the detector by maintaining the alignment of the predicted results. Comprehensive experiments on DOTA-v1.5 and DOTA-v1.0 benchmarks demonstrate that our proposed MCL can achieve state-of-the-art performance in the semi-supervised oriented object detection task.
UniKG: A Benchmark and Universal Embedding for Large-Scale Knowledge Graphs
Sep 11, 2023Irregular data in real-world are usually organized as heterogeneous graphs (HGs) consisting of multiple types of nodes and edges. To explore useful knowledge from real-world data, both the large-scale encyclopedic HG datasets and corresponding effective learning methods are crucial, but haven't been well investigated. In this paper, we construct a large-scale HG benchmark dataset named UniKG from Wikidata to facilitate knowledge mining and heterogeneous graph representation learning. Overall, UniKG contains more than 77 million multi-attribute entities and 2000 diverse association types, which significantly surpasses the scale of existing HG datasets. To perform effective learning on the large-scale UniKG, two key measures are taken, including (i) the semantic alignment strategy for multi-attribute entities, which projects the feature description of multi-attribute nodes into a common embedding space to facilitate node aggregation in a large receptive field; (ii) proposing a novel plug-and-play anisotropy propagation module (APM) to learn effective multi-hop anisotropy propagation kernels, which extends methods of large-scale homogeneous graphs to heterogeneous graphs. These two strategies enable efficient information propagation among a tremendous number of multi-attribute entities and meantimes adaptively mine multi-attribute association through the multi-hop aggregation in large-scale HGs. We set up a node classification task on our UniKG dataset, and evaluate multiple baseline methods which are constructed by embedding our APM into large-scale homogenous graph learning methods. Our UniKG dataset and the baseline codes have been released at https://github.com/Yide-Qiu/UniKG.
Big-model Driven Few-shot Continual Learning
Sep 02, 2023



Few-shot continual learning (FSCL) has attracted intensive attention and achieved some advances in recent years, but now it is difficult to again make a big stride in accuracy due to the limitation of only few-shot incremental samples. Inspired by distinctive human cognition ability in life learning, in this work, we propose a novel Big-model driven Few-shot Continual Learning (B-FSCL) framework to gradually evolve the model under the traction of the world's big-models (like human accumulative knowledge). Specifically, we perform the big-model driven transfer learning to leverage the powerful encoding capability of these existing big-models, which can adapt the continual model to a few of newly added samples while avoiding the over-fitting problem. Considering that the big-model and the continual model may have different perceived results for the identical images, we introduce an instance-level adaptive decision mechanism to provide the high-level flexibility cognitive support adjusted to varying samples. In turn, the adaptive decision can be further adopted to optimize the parameters of the continual model, performing the adaptive distillation of big-model's knowledge information. Experimental results of our proposed B-FSCL on three popular datasets (including CIFAR100, minilmageNet and CUB200) completely surpass all state-of-the-art FSCL methods.
Dual-Stream Diffusion Net for Text-to-Video Generation
Aug 18, 2023



With the emerging diffusion models, recently, text-to-video generation has aroused increasing attention. But an important bottleneck therein is that generative videos often tend to carry some flickers and artifacts. In this work, we propose a dual-stream diffusion net (DSDN) to improve the consistency of content variations in generating videos. In particular, the designed two diffusion streams, video content and motion branches, could not only run separately in their private spaces for producing personalized video variations as well as content, but also be well-aligned between the content and motion domains through leveraging our designed cross-transformer interaction module, which would benefit the smoothness of generated videos. Besides, we also introduce motion decomposer and combiner to faciliate the operation on video motion. Qualitative and quantitative experiments demonstrate that our method could produce amazing continuous videos with fewer flickers.
Edit Temporal-Consistent Videos with Image Diffusion Model
Aug 17, 2023



Large-scale text-to-image (T2I) diffusion models have been extended for text-guided video editing, yielding impressive zero-shot video editing performance. Nonetheless, the generated videos usually show spatial irregularities and temporal inconsistencies as the temporal characteristics of videos have not been faithfully modeled. In this paper, we propose an elegant yet effective Temporal-Consistent Video Editing (TCVE) method, to mitigate the temporal inconsistency challenge for robust text-guided video editing. In addition to the utilization of a pretrained 2D Unet for spatial content manipulation, we establish a dedicated temporal Unet architecture to faithfully capture the temporal coherence of the input video sequences. Furthermore, to establish coherence and interrelation between the spatial-focused and temporal-focused components, a cohesive joint spatial-temporal modeling unit is formulated. This unit effectively interconnects the temporal Unet with the pretrained 2D Unet, thereby enhancing the temporal consistency of the generated video output while simultaneously preserving the capacity for video content manipulation. Quantitative experimental results and visualization results demonstrate that TCVE achieves state-of-the-art performance in both video temporal consistency and video editing capability, surpassing existing benchmarks in the field.
Structure-Sensitive Graph Dictionary Embedding for Graph Classification
Jun 18, 2023



Graph structure expression plays a vital role in distinguishing various graphs. In this work, we propose a Structure-Sensitive Graph Dictionary Embedding (SS-GDE) framework to transform input graphs into the embedding space of a graph dictionary for the graph classification task. Instead of a plain use of a base graph dictionary, we propose the variational graph dictionary adaptation (VGDA) to generate a personalized dictionary (named adapted graph dictionary) for catering to each input graph. In particular, for the adaptation, the Bernoulli sampling is introduced to adjust substructures of base graph keys according to each input, which increases the expression capacity of the base dictionary tremendously. To make cross-graph measurement sensitive as well as stable, multi-sensitivity Wasserstein encoding is proposed to produce the embeddings by designing multi-scale attention on optimal transport. To optimize the framework, we introduce mutual information as the objective, which further deduces to variational inference of the adapted graph dictionary. We perform our SS-GDE on multiple datasets of graph classification, and the experimental results demonstrate the effectiveness and superiority over the state-of-the-art methods.
Decoupled Multimodal Distilling for Emotion Recognition
Mar 24, 2023



Human multimodal emotion recognition (MER) aims to perceive human emotions via language, visual and acoustic modalities. Despite the impressive performance of previous MER approaches, the inherent multimodal heterogeneities still haunt and the contribution of different modalities varies significantly. In this work, we mitigate this issue by proposing a decoupled multimodal distillation (DMD) approach that facilitates flexible and adaptive crossmodal knowledge distillation, aiming to enhance the discriminative features of each modality. Specially, the representation of each modality is decoupled into two parts, i.e., modality-irrelevant/-exclusive spaces, in a self-regression manner. DMD utilizes a graph distillation unit (GD-Unit) for each decoupled part so that each GD can be performed in a more specialized and effective manner. A GD-Unit consists of a dynamic graph where each vertice represents a modality and each edge indicates a dynamic knowledge distillation. Such GD paradigm provides a flexible knowledge transfer manner where the distillation weights can be automatically learned, thus enabling diverse crossmodal knowledge transfer patterns. Experimental results show DMD consistently obtains superior performance than state-of-the-art MER methods. Visualization results show the graph edges in DMD exhibit meaningful distributional patterns w.r.t. the modality-irrelevant/-exclusive feature spaces. Codes are released at \url{https://github.com/mdswyz/DMD}.
Unbiased Multiple Instance Learning for Weakly Supervised Video Anomaly Detection
Mar 22, 2023Weakly Supervised Video Anomaly Detection (WSVAD) is challenging because the binary anomaly label is only given on the video level, but the output requires snippet-level predictions. So, Multiple Instance Learning (MIL) is prevailing in WSVAD. However, MIL is notoriously known to suffer from many false alarms because the snippet-level detector is easily biased towards the abnormal snippets with simple context, confused by the normality with the same bias, and missing the anomaly with a different pattern. To this end, we propose a new MIL framework: Unbiased MIL (UMIL), to learn unbiased anomaly features that improve WSVAD. At each MIL training iteration, we use the current detector to divide the samples into two groups with different context biases: the most confident abnormal/normal snippets and the rest ambiguous ones. Then, by seeking the invariant features across the two sample groups, we can remove the variant context biases. Extensive experiments on benchmarks UCF-Crime and TAD demonstrate the effectiveness of our UMIL. Our code is provided at https://github.com/ktr-hubrt/UMIL.
Spatio-Temporal Relation Learning for Video Anomaly Detection
Sep 27, 2022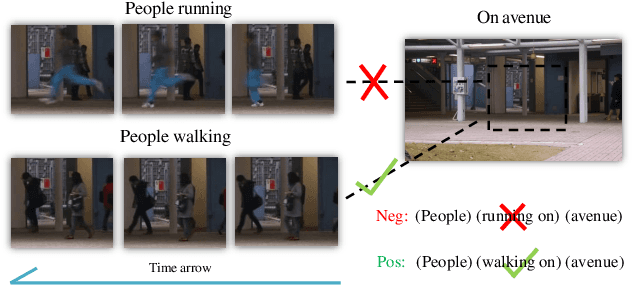
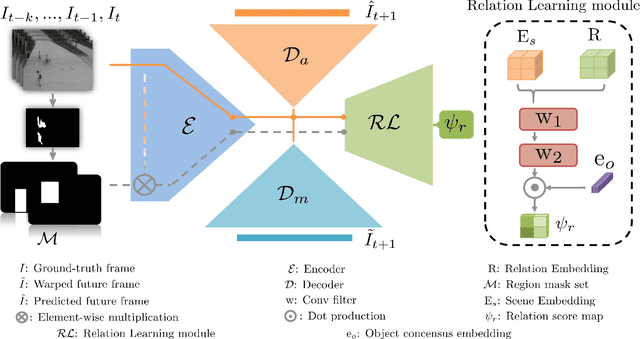
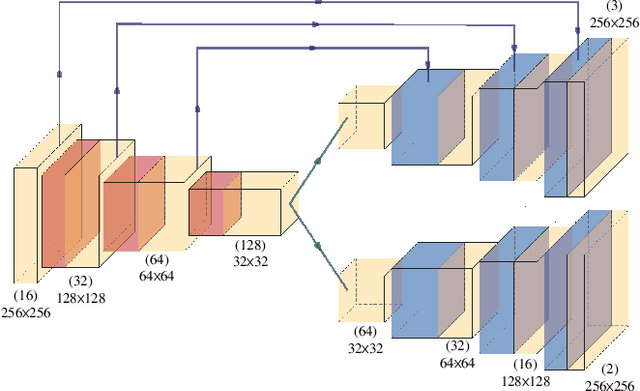
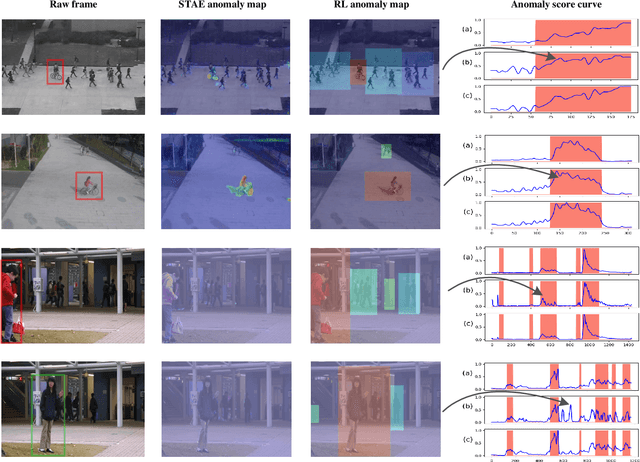
Anomaly identification is highly dependent on the relationship between the object and the scene, as different/same object actions in same/different scenes may lead to various degrees of normality and anomaly. Therefore, object-scene relation actually plays a crucial role in anomaly detection but is inadequately explored in previous works. In this paper, we propose a Spatial-Temporal Relation Learning (STRL) framework to tackle the video anomaly detection task. First, considering dynamic characteristics of the objects as well as scene areas, we construct a Spatio-Temporal Auto-Encoder (STAE) to jointly exploit spatial and temporal evolution patterns for representation learning. For better pattern extraction, two decoding branches are designed in the STAE module, i.e. an appearance branch capturing spatial cues by directly predicting the next frame, and a motion branch focusing on modeling the dynamics via optical flow prediction. Then, to well concretize the object-scene relation, a Relation Learning (RL) module is devised to analyze and summarize the normal relations by introducing the Knowledge Graph Embedding methodology. Specifically in this process, the plausibility of object-scene relation is measured by jointly modeling object/scene features and optimizable object-scene relation maps. Extensive experiments are conducted on three public datasets, and the superior performance over the state-of-the-art methods demonstrates the effectiveness of our method.
A collaborative decomposition-based evolutionary algorithm integrating normal and penalty-based boundary intersection for many-objective optimization
Apr 14, 2022Decomposition-based evolutionary algorithms have become fairly popular for many-objective optimization in recent years. However, the existing decomposition methods still are quite sensitive to the various shapes of frontiers of many-objective optimization problems (MaOPs). On the one hand, the cone decomposition methods such as the penalty-based boundary intersection (PBI) are incapable of acquiring uniform frontiers for MaOPs with very convex frontiers. On the other hand, the parallel reference lines of the parallel decomposition methods including the normal boundary intersection (NBI) might result in poor diversity because of under-sampling near the boundaries for MaOPs with concave frontiers. In this paper, a collaborative decomposition method is first proposed to integrate the advantages of parallel decomposition and cone decomposition to overcome their respective disadvantages. This method inherits the NBI-style Tchebycheff function as a convergence measure to heighten the convergence and uniformity of distribution of the PBI method. Moreover, this method also adaptively tunes the extent of rotating an NBI reference line towards a PBI reference line for every subproblem to enhance the diversity of distribution of the NBI method. Furthermore, a collaborative decomposition-based evolutionary algorithm (CoDEA) is presented for many-objective optimization. A collaborative decomposition-based environmental selection mechanism is primarily designed in CoDEA to rank all the individuals associated with the same PBI reference line in the boundary layer and pick out the best ranks. CoDEA is compared with several popular algorithms on 85 benchmark test instances. The experimental results show that CoDEA achieves high competitiveness benefiting from the collaborative decomposition maintaining a good balance among the convergence, uniformity, and diversity of distribution.