 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGateMem: Benchmarking Memory Governance in Multi-Principal Shared-Memory Agents
Jun 17, 2026Memory benchmarks for LLM agents largely assume single-user settings, leaving shared assistants for hospitals, workplaces, campuses, and households understudied. In these deployments, multiple principals write to a common memory pool and query it under different roles, scopes, and relationships, so memory quality requires governance as well as recall. We introduce GateMem, a benchmark for multi-principal shared-memory agents. GateMem jointly evaluates utility for legitimate long-horizon requests with state updates, access control across contextual authorization boundaries, and agent-facing active forgetting after explicit deletion requests. It spans medical, office, education, and household domains, with long-form multi-party episodes, incremental memory injection, hidden checkpoints, structured judging, and leak-target annotations. Across diverse baselines and backbone models, no method simultaneously achieves strong utility, robust access control, and reliable forgetting. Long-context prompting often yields the best governance score at high token cost, while retrieval-based and external-memory methods reduce cost yet still leak unauthorized or deleted information. These results show current memory agents remain far from reliable shared institutional deployment.
How Much Can We Trust LLM Search Agents? Measuring Endorsement Vulnerability to Web Content Manipulation
Jun 15, 2026Large language model (LLM)-based search agents synthesize open-web content into actionable recommendations on behalf of users, creating a risk that attacker-published pages are transformed into endorsed claims. We introduce SearchGEO, a controlled evaluation framework for measuring endorsement corruption in LLM-based web-search agents, combining a web-evidence manipulation pipeline, a five-mode attack taxonomy, and multiple output-level metrics. We evaluate 13 LLM backends on 308 cases each. Results show that vulnerability patterns vary across backends: overall attack success rate (ASR) ranges from 0.0% on Claude-Sonnet-4.6 to 31.4% on Gemini-3-Flash, the strongest attack mode differs by model family, and the same deployment scaffold could amplify or decrease ASR on different backends. An auxiliary agent-skill probe, where endorsement becomes an install command, exposes a sharp split among otherwise robust backends: Claude over-rejects while GPT over-trusts. These findings argue for treating recommendation reliability under adversarial search content as a first-class dimension of backend safety evaluation.
Prompt Tuning for Few-Shot Continual Learning Named Entity Recognition
Aug 10, 2025Knowledge distillation has been successfully applied to Continual Learning Named Entity Recognition (CLNER) tasks, by using a teacher model trained on old-class data to distill old-class entities present in new-class data as a form of regularization, thereby avoiding catastrophic forgetting. However, in Few-Shot CLNER (FS-CLNER) tasks, the scarcity of new-class entities makes it difficult for the trained model to generalize during inference. More critically, the lack of old-class entity information hinders the distillation of old knowledge, causing the model to fall into what we refer to as the Few-Shot Distillation Dilemma. In this work, we address the above challenges through a prompt tuning paradigm and memory demonstration template strategy. Specifically, we designed an expandable Anchor words-oriented Prompt Tuning (APT) paradigm to bridge the gap between pre-training and fine-tuning, thereby enhancing performance in few-shot scenarios. Additionally, we incorporated Memory Demonstration Templates (MDT) into each training instance to provide replay samples from previous tasks, which not only avoids the Few-Shot Distillation Dilemma but also promotes in-context learning. Experiments show that our approach achieves competitive performances on FS-CLNER.
GEDepth: Ground Embedding for Monocular Depth Estimation
Sep 18, 2023



Monocular depth estimation is an ill-posed problem as the same 2D image can be projected from infinite 3D scenes. Although the leading algorithms in this field have reported significant improvement, they are essentially geared to the particular compound of pictorial observations and camera parameters (i.e., intrinsics and extrinsics), strongly limiting their generalizability in real-world scenarios. To cope with this challenge, this paper proposes a novel ground embedding module to decouple camera parameters from pictorial cues, thus promoting the generalization capability. Given camera parameters, the proposed module generates the ground depth, which is stacked with the input image and referenced in the final depth prediction. A ground attention is designed in the module to optimally combine ground depth with residual depth. Our ground embedding is highly flexible and lightweight, leading to a plug-in module that is amenable to be integrated into various depth estimation networks. Experiments reveal that our approach achieves the state-of-the-art results on popular benchmarks, and more importantly, renders significant generalization improvement on a wide range of cross-domain tests.
A constrained clustering based approach for matching a collection of feature sets
Jun 12, 2016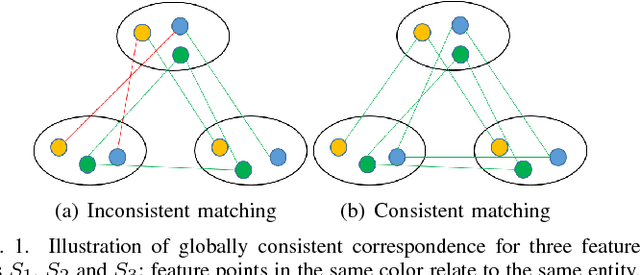
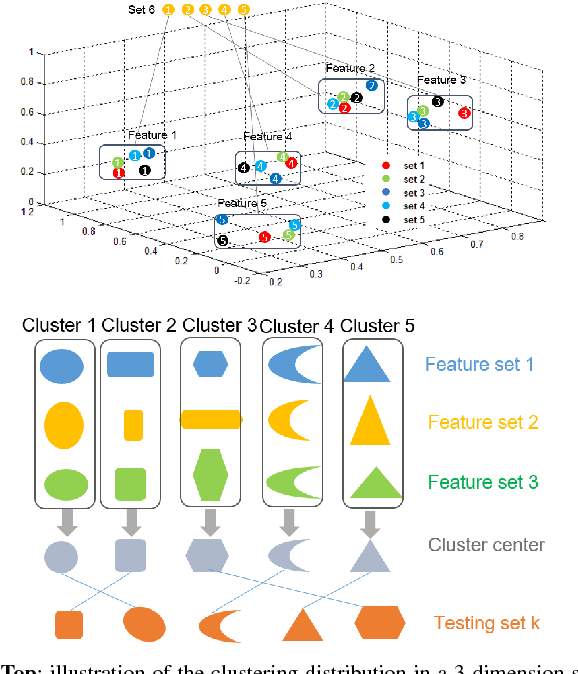
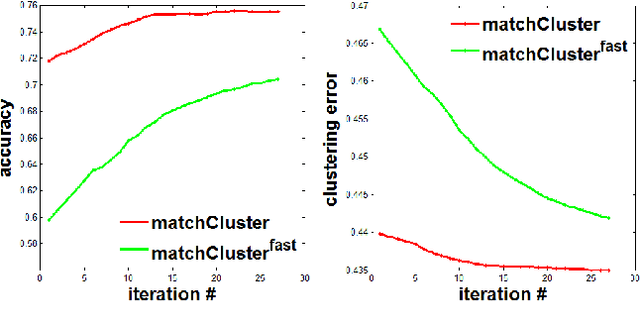
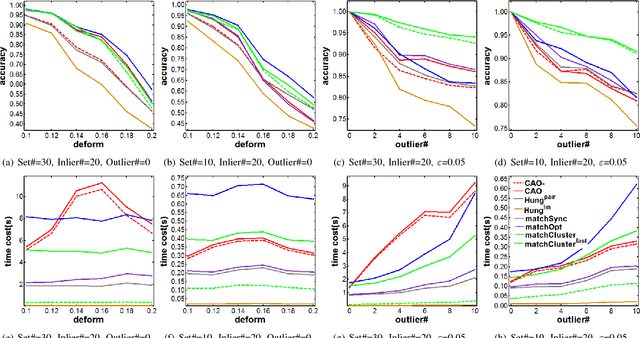
In this paper, we consider the problem of finding the feature correspondences among a collection of feature sets, by using their point-wise unary features. This is a fundamental problem in computer vision and pattern recognition, which also closely relates to other areas such as operational research. Different from two-set matching which can be transformed to a quadratic assignment programming task that is known NP-hard, inclusion of merely unary attributes leads to a linear assignment problem for matching two feature sets. This problem has been well studied and there are effective polynomial global optimum solvers such as the Hungarian method. However, it becomes ill-posed when the unary attributes are (heavily) corrupted. The global optimal correspondence concerning the best score defined by the attribute affinity/cost between the two sets can be distinct to the ground truth correspondence since the score function is biased by noises. To combat this issue, we devise a method for matching a collection of feature sets by synergetically exploring the information across the sets. In general, our method can be perceived from a (constrained) clustering perspective: in each iteration, it assigns the features of one set to the clusters formed by the rest of feature sets, and updates the cluster centers in turn. Results on both synthetic data and real images suggest the efficacy of our method against state-of-the-arts.