 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhao Kang
Hyperspectral Image Denoising Using Non-convex Local Low-rank and Sparse Separation with Spatial-Spectral Total Variation Regularization
Jan 08, 2022
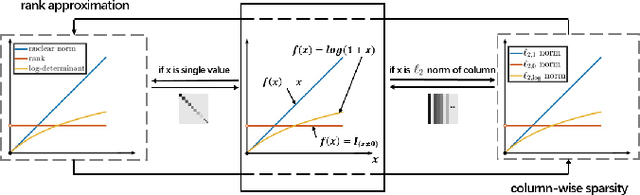


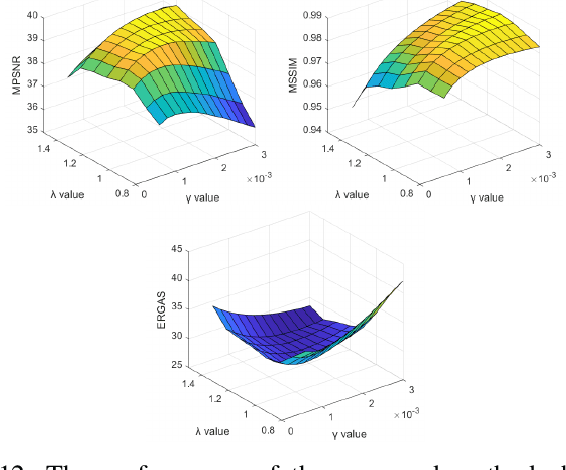
In this paper, we propose a novel nonconvex approach to robust principal component analysis for HSI denoising, which focuses on simultaneously developing more accurate approximations to both rank and column-wise sparsity for the low-rank and sparse components, respectively. In particular, the new method adopts the log-determinant rank approximation and a novel $\ell_{2,\log}$ norm, to restrict the local low-rank or column-wisely sparse properties for the component matrices, respectively. For the $\ell_{2,\log}$-regularized shrinkage problem, we develop an efficient, closed-form solution, which is named $\ell_{2,\log}$-shrinkage operator. The new regularization and the corresponding operator can be generally used in other problems that require column-wise sparsity. Moreover, we impose the spatial-spectral total variation regularization in the log-based nonconvex RPCA model, which enhances the global piece-wise smoothness and spectral consistency from the spatial and spectral views in the recovered HSI. Extensive experiments on both simulated and real HSIs demonstrate the effectiveness of the proposed method in denoising HSIs.
Multilayer Graph Contrastive Clustering Network
Dec 28, 2021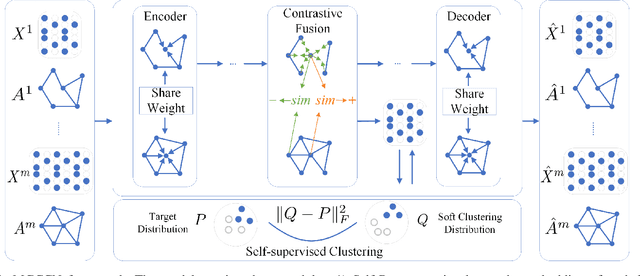
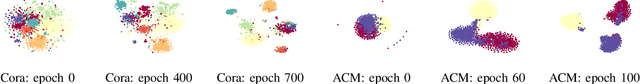
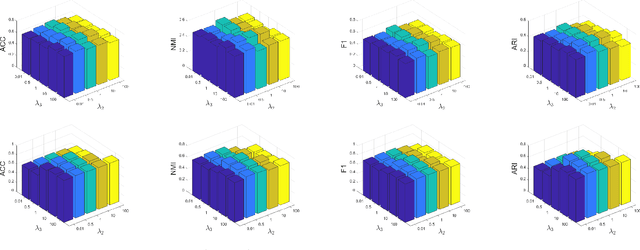
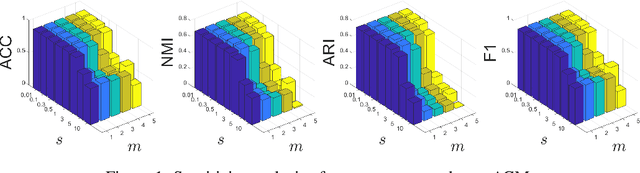
Multilayer graph has garnered plenty of research attention in many areas due to their high utility in modeling interdependent systems. However, clustering of multilayer graph, which aims at dividing the graph nodes into categories or communities, is still at a nascent stage. Existing methods are often limited to exploiting the multiview attributes or multiple networks and ignoring more complex and richer network frameworks. To this end, we propose a generic and effective autoencoder framework for multilayer graph clustering named Multilayer Graph Contrastive Clustering Network (MGCCN). MGCCN consists of three modules: (1)Attention mechanism is applied to better capture the relevance between nodes and neighbors for better node embeddings. (2)To better explore the consistent information in different networks, a contrastive fusion strategy is introduced. (3)MGCCN employs a self-supervised component that iteratively strengthens the node embedding and clustering. Extensive experiments on different types of real-world graph data indicate that our proposed method outperforms state-of-the-art techniques.
Multi-view Contrastive Graph Clustering
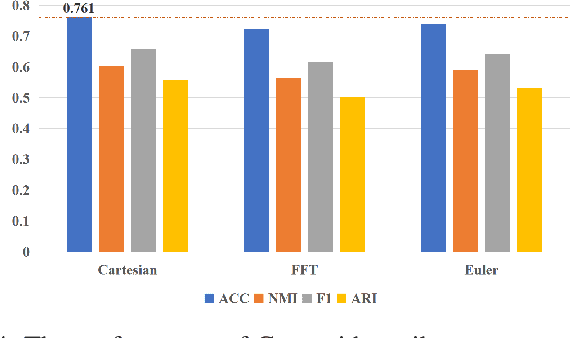
Oct 22, 2021
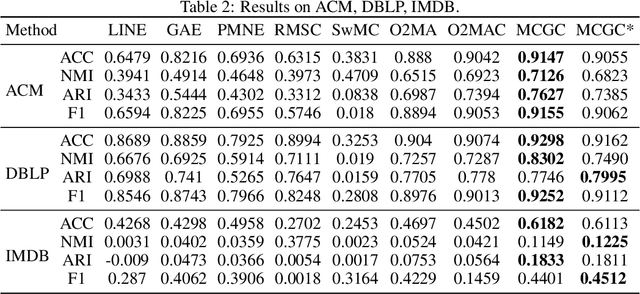
With the explosive growth of information technology, multi-view graph data have become increasingly prevalent and valuable. Most existing multi-view clustering techniques either focus on the scenario of multiple graphs or multi-view attributes. In this paper, we propose a generic framework to cluster multi-view attributed graph data. Specifically, inspired by the success of contrastive learning, we propose multi-view contrastive graph clustering (MCGC) method to learn a consensus graph since the original graph could be noisy or incomplete and is not directly applicable. Our method composes of two key steps: we first filter out the undesirable high-frequency noise while preserving the graph geometric features via graph filtering and obtain a smooth representation of nodes; we then learn a consensus graph regularized by graph contrastive loss. Results on several benchmark datasets show the superiority of our method with respect to state-of-the-art approaches. In particular, our simple approach outperforms existing deep learning-based methods.
Self-supervised Consensus Representation Learning for Attributed Graph
Aug 10, 2021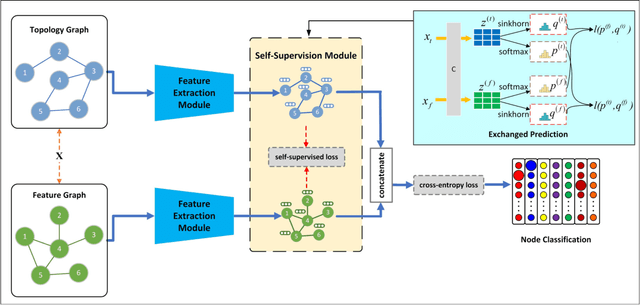

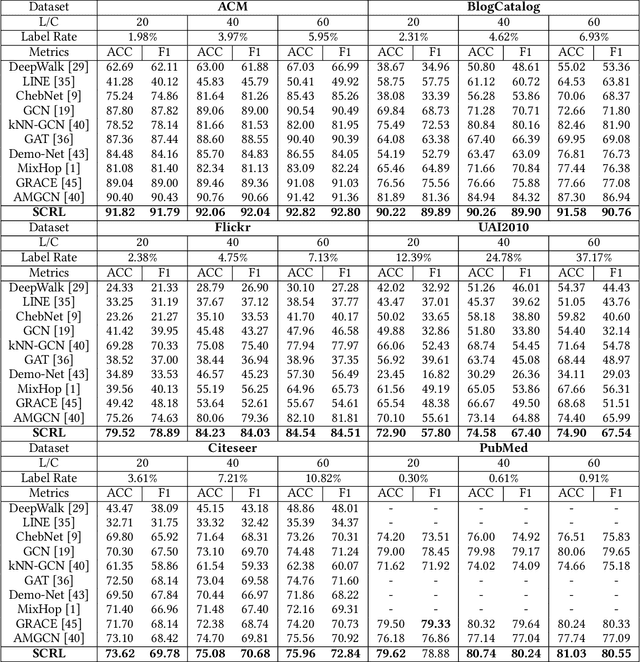
Attempting to fully exploit the rich information of topological structure and node features for attributed graph, we introduce self-supervised learning mechanism to graph representation learning and propose a novel Self-supervised Consensus Representation Learning (SCRL) framework. In contrast to most existing works that only explore one graph, our proposed SCRL method treats graph from two perspectives: topology graph and feature graph. We argue that their embeddings should share some common information, which could serve as a supervisory signal. Specifically, we construct the feature graph of node features via k-nearest neighbor algorithm. Then graph convolutional network (GCN) encoders extract features from two graphs respectively. Self-supervised loss is designed to maximize the agreement of the embeddings of the same node in the topology graph and the feature graph. Extensive experiments on real citation networks and social networks demonstrate the superiority of our proposed SCRL over the state-of-the-art methods on semi-supervised node classification task. Meanwhile, compared with its main competitors, SCRL is rather efficient.
Self-paced Principal Component Analysis
Jun 25, 2021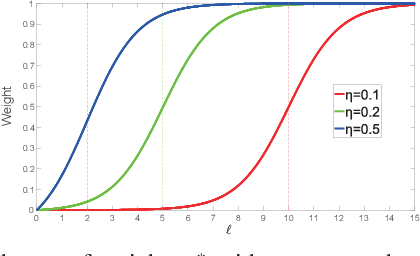
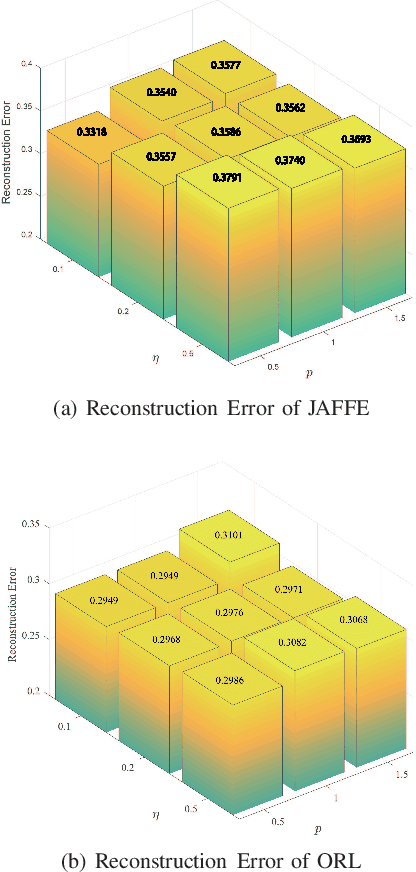


Principal Component Analysis (PCA) has been widely used for dimensionality reduction and feature extraction. Robust PCA (RPCA), under different robust distance metrics, such as l1-norm and l2, p-norm, can deal with noise or outliers to some extent. However, real-world data may display structures that can not be fully captured by these simple functions. In addition, existing methods treat complex and simple samples equally. By contrast, a learning pattern typically adopted by human beings is to learn from simple to complex and less to more. Based on this principle, we propose a novel method called Self-paced PCA (SPCA) to further reduce the effect of noise and outliers. Notably, the complexity of each sample is calculated at the beginning of each iteration in order to integrate samples from simple to more complex into training. Based on an alternating optimization, SPCA finds an optimal projection matrix and filters out outliers iteratively. Theoretical analysis is presented to show the rationality of SPCA. Extensive experiments on popular data sets demonstrate that the proposed method can improve the state of-the-art results considerably.
Smoothed Multi-View Subspace Clustering
Jun 18, 2021
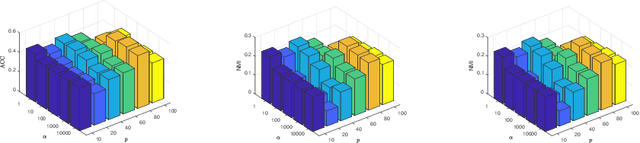
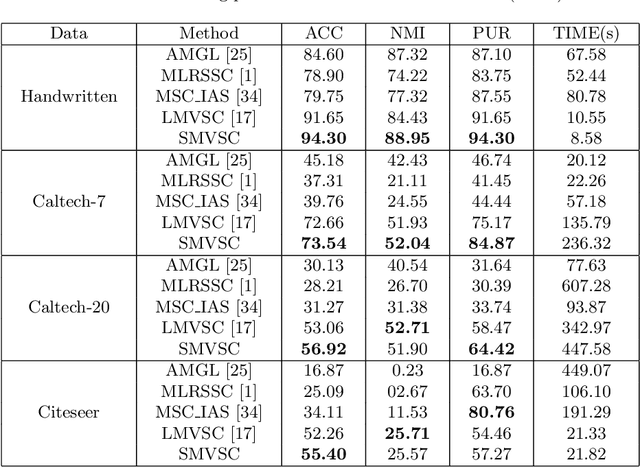
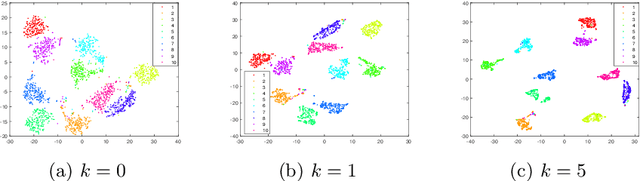
In recent years, multi-view subspace clustering has achieved impressive performance due to the exploitation of complementary imformation across multiple views. However, multi-view data can be very complicated and are not easy to cluster in real-world applications. Most existing methods operate on raw data and may not obtain the optimal solution. In this work, we propose a novel multi-view clustering method named smoothed multi-view subspace clustering (SMVSC) by employing a novel technique, i.e., graph filtering, to obtain a smooth representation for each view, in which similar data points have similar feature values. Specifically, it retains the graph geometric features through applying a low-pass filter. Consequently, it produces a ``clustering-friendly" representation and greatly facilitates the downstream clustering task. Extensive experiments on benchmark datasets validate the superiority of our approach. Analysis shows that graph filtering increases the separability of classes.
Towards Clustering-friendly Representations: Subspace Clustering via Graph Filtering
Jun 18, 2021
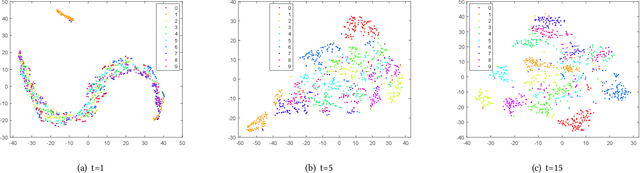
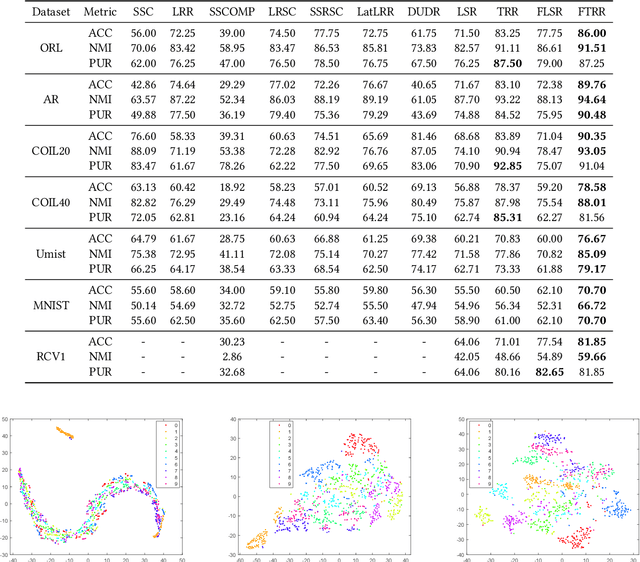

Finding a suitable data representation for a specific task has been shown to be crucial in many applications. The success of subspace clustering depends on the assumption that the data can be separated into different subspaces. However, this simple assumption does not always hold since the raw data might not be separable into subspaces. To recover the ``clustering-friendly'' representation and facilitate the subsequent clustering, we propose a graph filtering approach by which a smooth representation is achieved. Specifically, it injects graph similarity into data features by applying a low-pass filter to extract useful data representations for clustering. Extensive experiments on image and document clustering datasets demonstrate that our method improves upon state-of-the-art subspace clustering techniques. Especially, its comparable performance with deep learning methods emphasizes the effectiveness of the simple graph filtering scheme for many real-world applications. An ablation study shows that graph filtering can remove noise, preserve structure in the image, and increase the separability of classes.
Pseudo-supervised Deep Subspace Clustering
Apr 08, 2021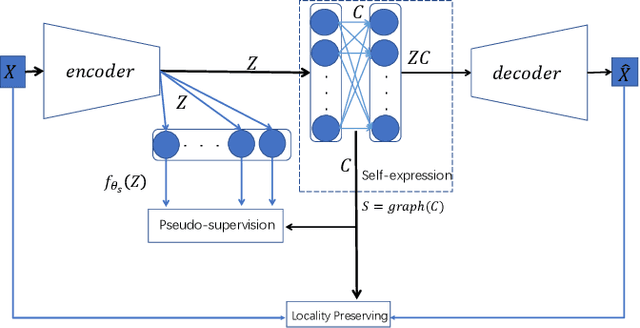
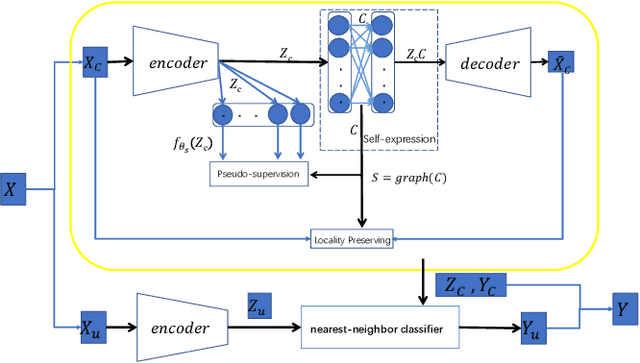
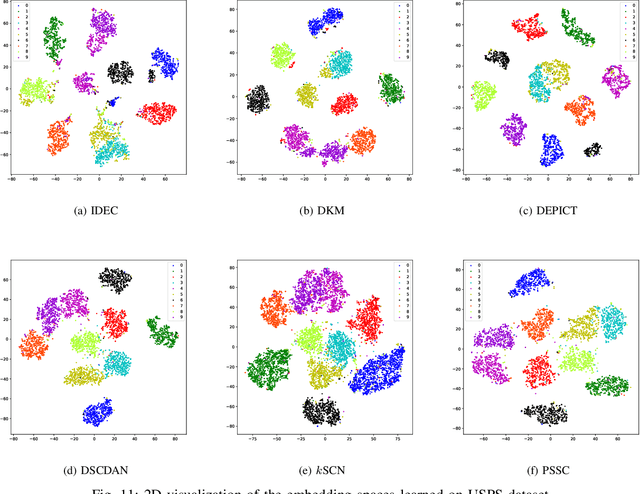
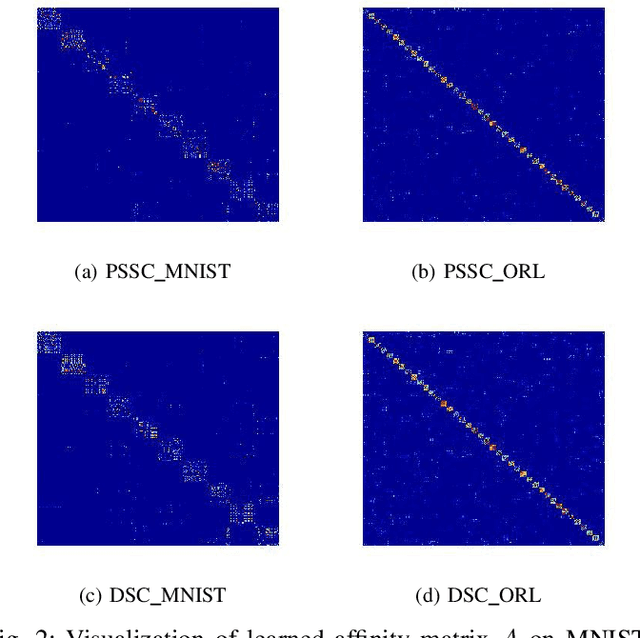
Auto-Encoder (AE)-based deep subspace clustering (DSC) methods have achieved impressive performance due to the powerful representation extracted using deep neural networks while prioritizing categorical separability. However, self-reconstruction loss of an AE ignores rich useful relation information and might lead to indiscriminative representation, which inevitably degrades the clustering performance. It is also challenging to learn high-level similarity without feeding semantic labels. Another unsolved problem facing DSC is the huge memory cost due to $n\times n$ similarity matrix, which is incurred by the self-expression layer between an encoder and decoder. To tackle these problems, we use pairwise similarity to weigh the reconstruction loss to capture local structure information, while a similarity is learned by the self-expression layer. Pseudo-graphs and pseudo-labels, which allow benefiting from uncertain knowledge acquired during network training, are further employed to supervise similarity learning. Joint learning and iterative training facilitate to obtain an overall optimal solution. Extensive experiments on benchmark datasets demonstrate the superiority of our approach. By combining with the $k$-nearest neighbors algorithm, we further show that our method can address the large-scale and out-of-sample problems.
Structured Graph Learning for Scalable Subspace Clustering: From Single-view to Multi-view
Feb 16, 2021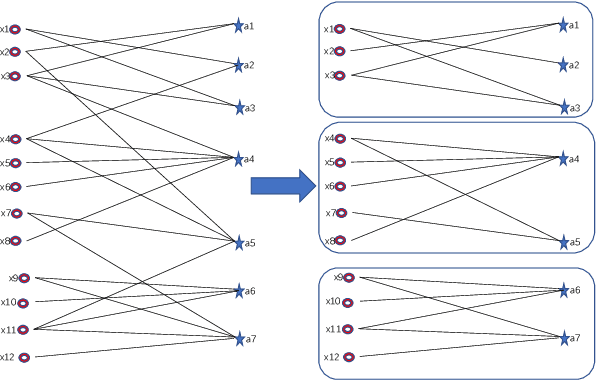
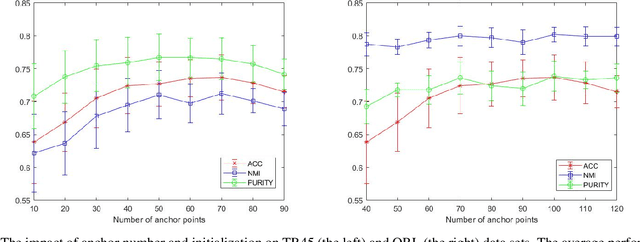
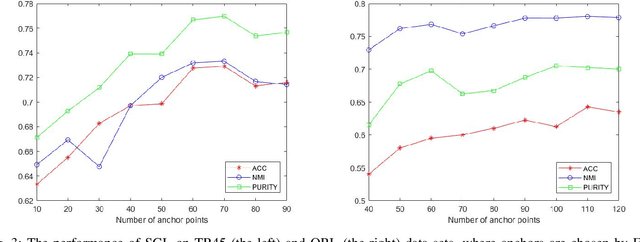
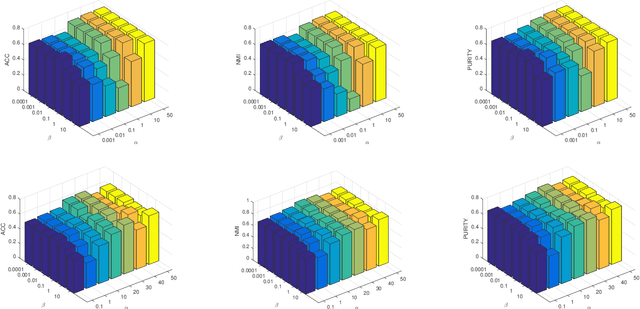
Graph-based subspace clustering methods have exhibited promising performance. However, they still suffer some of these drawbacks: encounter the expensive time overhead, fail in exploring the explicit clusters, and cannot generalize to unseen data points. In this work, we propose a scalable graph learning framework, seeking to address the above three challenges simultaneously. Specifically, it is based on the ideas of anchor points and bipartite graph. Rather than building a $n\times n$ graph, where $n$ is the number of samples, we construct a bipartite graph to depict the relationship between samples and anchor points. Meanwhile, a connectivity constraint is employed to ensure that the connected components indicate clusters directly. We further establish the connection between our method and the K-means clustering. Moreover, a model to process multi-view data is also proposed, which is linear scaled with respect to $n$. Extensive experiments demonstrate the efficiency and effectiveness of our approach with respect to many state-of-the-art clustering methods.
Kernel Two-Dimensional Ridge Regression for Subspace Clustering
Nov 03, 2020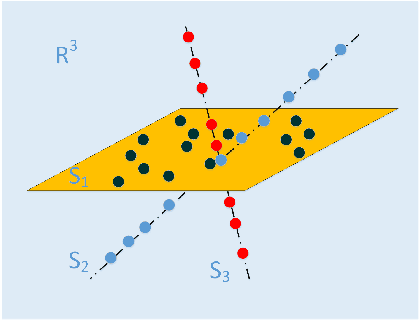


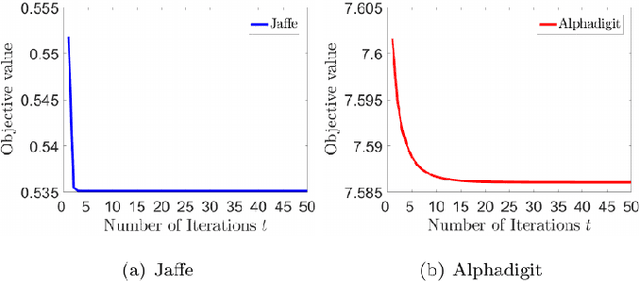
Subspace clustering methods have been widely studied recently. When the inputs are 2-dimensional (2D) data, existing subspace clustering methods usually convert them into vectors, which severely damages inherent structures and relationships from original data. In this paper, we propose a novel subspace clustering method for 2D data. It directly uses 2D data as inputs such that the learning of representations benefits from inherent structures and relationships of the data. It simultaneously seeks image projection and representation coefficients such that they mutually enhance each other and lead to powerful data representations. An efficient algorithm is developed to solve the proposed objective function with provable decreasing and convergence property. Extensive experimental results verify the effectiveness of the new method.