 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient is All You Need?
Jun 16, 2023

In this paper we provide a novel analytical perspective on the theoretical understanding of gradient-based learning algorithms by interpreting consensus-based optimization (CBO), a recently proposed multi-particle derivative-free optimization method, as a stochastic relaxation of gradient descent. Remarkably, we observe that through communication of the particles, CBO exhibits a stochastic gradient descent (SGD)-like behavior despite solely relying on evaluations of the objective function. The fundamental value of such link between CBO and SGD lies in the fact that CBO is provably globally convergent to global minimizers for ample classes of nonsmooth and nonconvex objective functions, hence, on the one side, offering a novel explanation for the success of stochastic relaxations of gradient descent. On the other side, contrary to the conventional wisdom for which zero-order methods ought to be inefficient or not to possess generalization abilities, our results unveil an intrinsic gradient descent nature of such heuristics. This viewpoint furthermore complements previous insights into the working principles of CBO, which describe the dynamics in the mean-field limit through a nonlinear nonlocal partial differential equation that allows to alleviate complexities of the nonconvex function landscape. Our proofs leverage a completely nonsmooth analysis, which combines a novel quantitative version of the Laplace principle (log-sum-exp trick) and the minimizing movement scheme (proximal iteration). In doing so, we furnish useful and precise insights that explain how stochastic perturbations of gradient descent overcome energy barriers and reach deep levels of nonconvex functions. Instructive numerical illustrations support the provided theoretical insights.
Finite Sample Identification of Wide Shallow Neural Networks with Biases
Nov 08, 2022

Artificial neural networks are functions depending on a finite number of parameters typically encoded as weights and biases. The identification of the parameters of the network from finite samples of input-output pairs is often referred to as the \emph{teacher-student model}, and this model has represented a popular framework for understanding training and generalization. Even if the problem is NP-complete in the worst case, a rapidly growing literature -- after adding suitable distributional assumptions -- has established finite sample identification of two-layer networks with a number of neurons $m=\mathcal O(D)$, $D$ being the input dimension. For the range $D<m<D^2$ the problem becomes harder, and truly little is known for networks parametrized by biases as well. This paper fills the gap by providing constructive methods and theoretical guarantees of finite sample identification for such wider shallow networks with biases. Our approach is based on a two-step pipeline: first, we recover the direction of the weights, by exploiting second order information; next, we identify the signs by suitable algebraic evaluations, and we recover the biases by empirical risk minimization via gradient descent. Numerical results demonstrate the effectiveness of our approach.
Semi-Supervised Manifold Learning with Complexity Decoupled Chart Autoencoders
Aug 22, 2022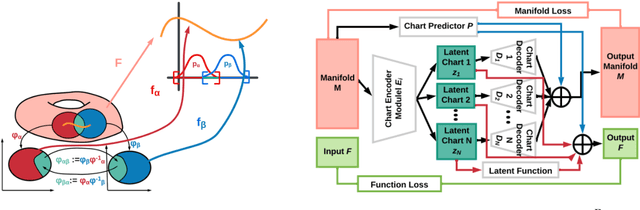
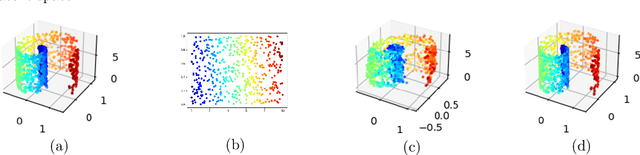
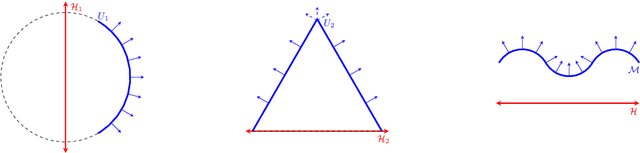
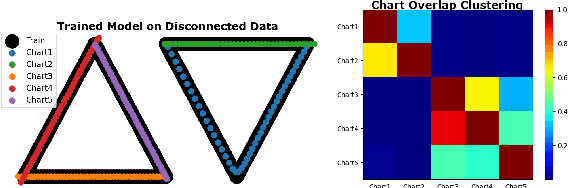
Autoencoding is a popular method in representation learning. Conventional autoencoders employ symmetric encoding-decoding procedures and a simple Euclidean latent space to detect hidden low-dimensional structures in an unsupervised way. This work introduces a chart autoencoder with an asymmetric encoding-decoding process that can incorporate additional semi-supervised information such as class labels. Besides enhancing the capability for handling data with complicated topological and geometric structures, these models can successfully differentiate nearby but disjoint manifolds and intersecting manifolds with only a small amount of supervision. Moreover, this model only requires a low complexity encoder, such as local linear projection. We discuss the theoretical approximation power of such networks that essentially depends on the intrinsic dimension of the data manifold and not the dimension of the observations. Our numerical experiments on synthetic and real-world data verify that the proposed model can effectively manage data with multi-class nearby but disjoint manifolds of different classes, overlapping manifolds, and manifolds with non-trivial topology.
Landscape analysis of an improved power method for tensor decomposition
Oct 29, 2021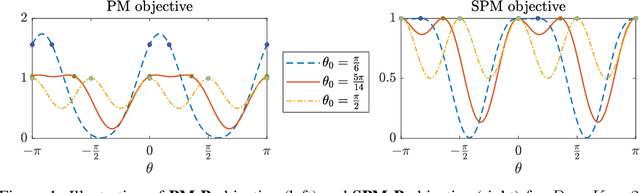
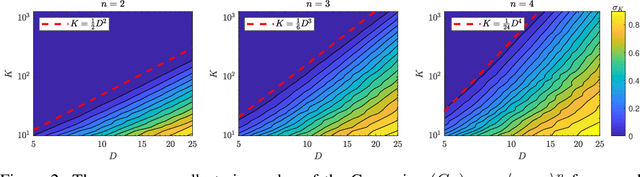
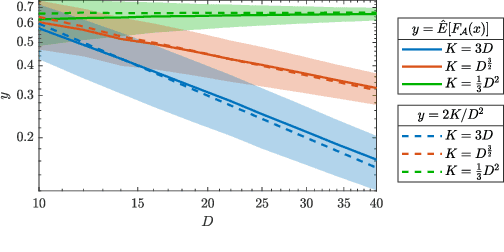
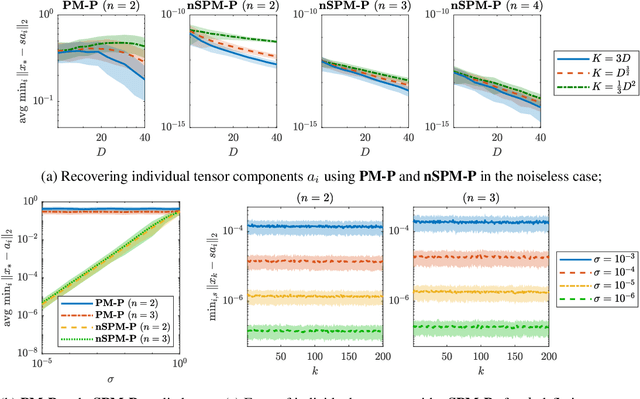
In this work, we consider the optimization formulation for symmetric tensor decomposition recently introduced in the Subspace Power Method (SPM) of Kileel and Pereira. Unlike popular alternative functionals for tensor decomposition, the SPM objective function has the desirable properties that its maximal value is known in advance, and its global optima are exactly the rank-1 components of the tensor when the input is sufficiently low-rank. We analyze the non-convex optimization landscape associated with the SPM objective. Our analysis accounts for working with noisy tensors. We derive quantitative bounds such that any second-order critical point with SPM objective value exceeding the bound must equal a tensor component in the noiseless case, and must approximate a tensor component in the noisy case. For decomposing tensors of size $D^{\times m}$, we obtain a near-global guarantee up to rank $\widetilde{o}(D^{\lfloor m/2 \rfloor})$ under a random tensor model, and a global guarantee up to rank $\mathcal{O}(D)$ assuming deterministic frame conditions. This implies that SPM with suitable initialization is a provable, efficient, robust algorithm for low-rank symmetric tensor decomposition. We conclude with numerics that show a practical preferability for using the SPM functional over a more established counterpart.
Stable Recovery of Entangled Weights: Towards Robust Identification of Deep Neural Networks from Minimal Samples
Jan 18, 2021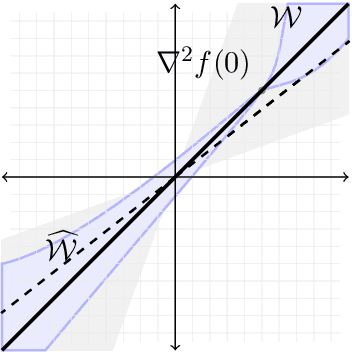

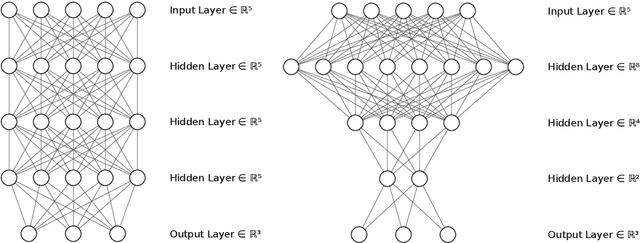
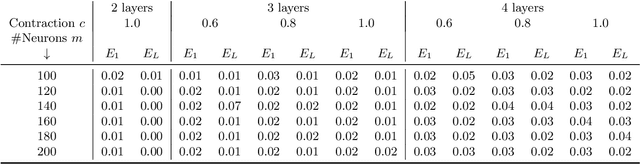
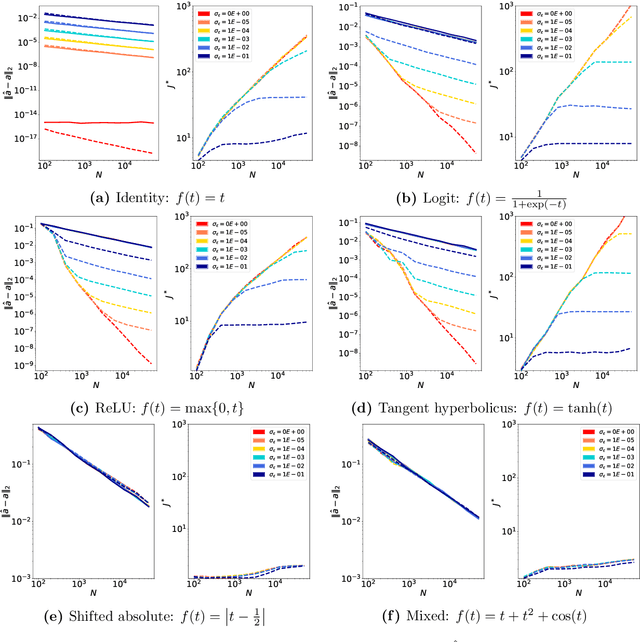
In this paper we approach the problem of unique and stable identifiability of generic deep artificial neural networks with pyramidal shape and smooth activation functions from a finite number of input-output samples. More specifically we introduce the so-called entangled weights, which compose weights of successive layers intertwined with suitable diagonal and invertible matrices depending on the activation functions and their shifts. We prove that entangled weights are completely and stably approximated by an efficient and robust algorithm as soon as $\mathcal O(D^2 \times m)$ nonadaptive input-output samples of the network are collected, where $D$ is the input dimension and $m$ is the number of neurons of the network. Moreover, we empirically observe that the approach applies to networks with up to $\mathcal O(D \times m_L)$ neurons, where $m_L$ is the number of output neurons at layer $L$. Provided knowledge of layer assignments of entangled weights and of remaining scaling and shift parameters, which may be further heuristically obtained by least squares, the entangled weights identify the network completely and uniquely. To highlight the relevance of the theoretical result of stable recovery of entangled weights, we present numerical experiments, which demonstrate that multilayered networks with generic weights can be robustly identified and therefore uniformly approximated by the presented algorithmic pipeline. In contrast backpropagation cannot generalize stably very well in this setting, being always limited by relatively large uniform error. In terms of practical impact, our study shows that we can relate input-output information uniquely and stably to network parameters, providing a form of explainability. Moreover, our method paves the way for compression of overparametrized networks and for the training of minimal complexity networks.
ReLU nets adapt to intrinsic dimensionality beyond the target domain
Aug 06, 2020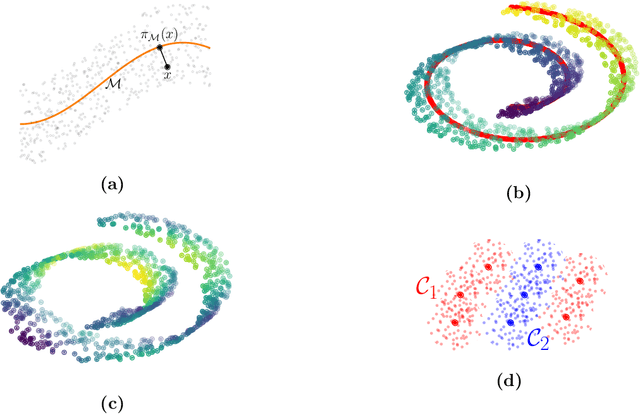

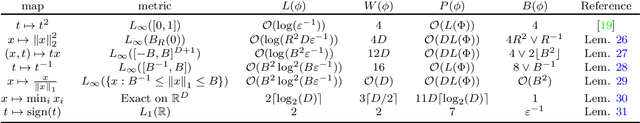
We study the approximation of two-layer compositions $f(x) = g(\phi(x))$ via deep ReLU networks, where $\phi$ is a nonlinear, geometrically intuitive, and dimensionality reducing feature map. We focus on two complementary choices for $\phi$ that are intuitive and frequently appearing in the statistical literature. The resulting approximation rates are near optimal and show adaptivity to intrinsic notions of complexity, which significantly extend a series of recent works on approximating targets over low-dimensional manifolds. Specifically, we show that ReLU nets can express functions, which are invariant to the input up to an orthogonal projection onto a low-dimensional manifold, with the same efficiency as if the target domain would be the manifold itself. This implies approximation via ReLU nets is faithful to an intrinsic dimensionality governed by the target $f$ itself, rather than the dimensionality of the approximation domain. As an application of our approximation bounds, we study empirical risk minimization over a space of sparsely constrained ReLU nets under the assumption that the conditional expectation satisfies one of the proposed models. We show near-optimal estimation guarantees in regression and classifications problems, for which, to the best of our knowledge, no efficient estimator has been developed so far.
Estimating covariance and precision matrices along subspaces
Sep 26, 2019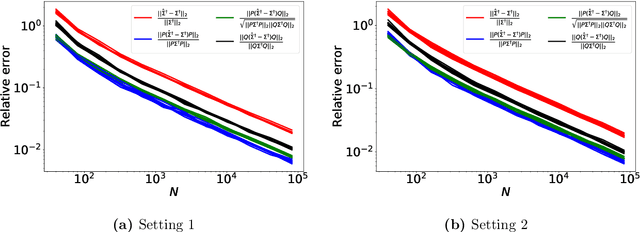
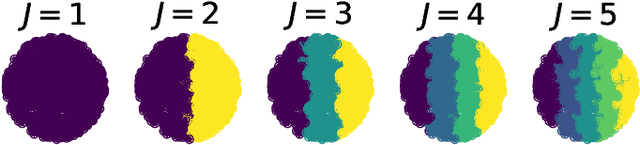
We study the accuracy of estimating the covariance and the precision matrix of a $D$-variate sub-Gaussian distribution along a prescribed subspace or direction using the finite sample covariance with $N \geq D$ samples. Our results show that the estimation accuracy depends almost exclusively only on the components of the distribution that correspond to desired subspaces or directions. This is relevant for problems where behavior of data along a lower-dimensional space is of specific interest, such as dimension reduction or structured regression problems. As a by-product of the analysis, we reduce the effect the matrix condition number has on the estimation of precision matrices. Two applications are presented: direction-sensitive eigenspace perturbation bounds, and estimation of the single-index model. For the latter, a new estimator, derived from the analysis, with strong theoretical guarantees and superior numerical performance is proposed.
Robust and Resource Efficient Identification of Two Hidden Layer Neural Networks
Jun 30, 2019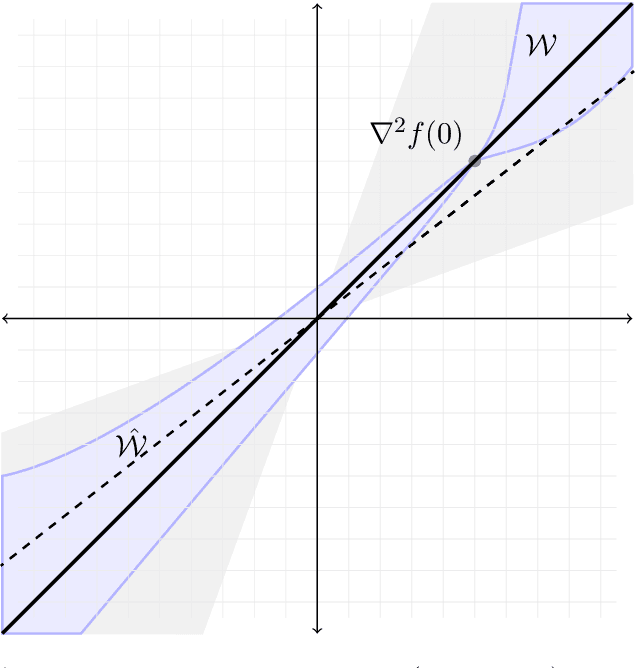
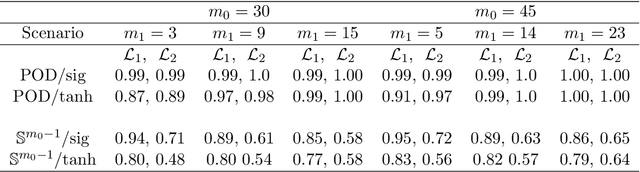
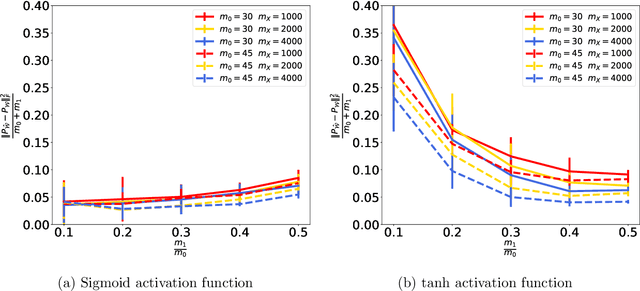
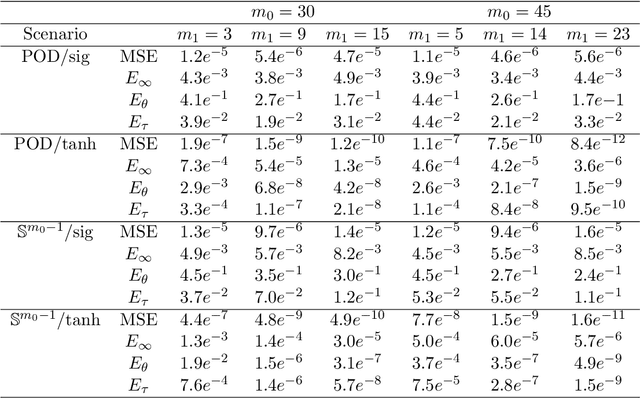
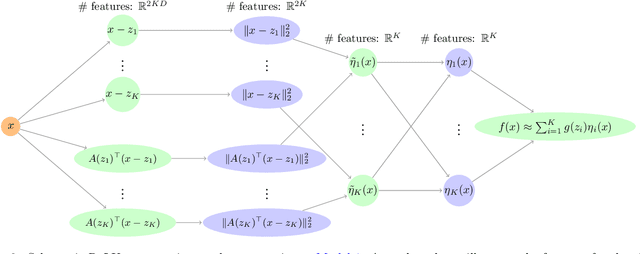
We address the structure identification and the uniform approximation of two fully nonlinear layer neural networks of the type $f(x)=1^T h(B^T g(A^T x))$ on $\mathbb R^d$ from a small number of query samples. We approach the problem by sampling actively finite difference approximations to Hessians of the network. Gathering several approximate Hessians allows reliably to approximate the matrix subspace $\mathcal W$ spanned by symmetric tensors $a_1 \otimes a_1 ,\dots,a_{m_0}\otimes a_{m_0}$ formed by weights of the first layer together with the entangled symmetric tensors $v_1 \otimes v_1 ,\dots,v_{m_1}\otimes v_{m_1}$, formed by suitable combinations of the weights of the first and second layer as $v_\ell=A G_0 b_\ell/\|A G_0 b_\ell\|_2$, $\ell \in [m_1]$, for a diagonal matrix $G_0$ depending on the activation functions of the first layer. The identification of the 1-rank symmetric tensors within $\mathcal W$ is then performed by the solution of a robust nonlinear program. We provide guarantees of stable recovery under a posteriori verifiable conditions. We further address the correct attribution of approximate weights to the first or second layer. By using a suitably adapted gradient descent iteration, it is possible then to estimate, up to intrinsic symmetries, the shifts of the activations functions of the first layer and compute exactly the matrix $G_0$. Our method of identification of the weights of the network is fully constructive, with quantifiable sample complexity, and therefore contributes to dwindle the black-box nature of the network training phase. We corroborate our theoretical results by extensive numerical experiments.
Nonlinear generalization of the single index model
Feb 24, 2019

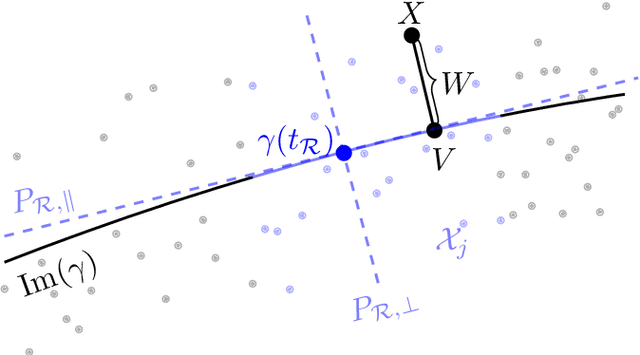

Single index model is a powerful yet simple model, widely used in statistics, machine learning, and other scientific fields. It models the regression function as $g(<a,x>)$, where a is an unknown index vector and x are the features. This paper deals with a nonlinear generalization of this framework to allow for a regressor that uses multiple index vectors, adapting to local changes in the responses. To do so we exploit the conditional distribution over function-driven partitions, and use linear regression to locally estimate index vectors. We then regress by applying a kNN type estimator that uses a localized proxy of the geodesic metric. We present theoretical guarantees for estimation of local index vectors and out-of-sample prediction, and demonstrate the performance of our method with experiments on synthetic and real-world data sets, comparing it with state-of-the-art methods.
Adaptive multi-penalty regularization based on a generalized Lasso path
Oct 11, 2017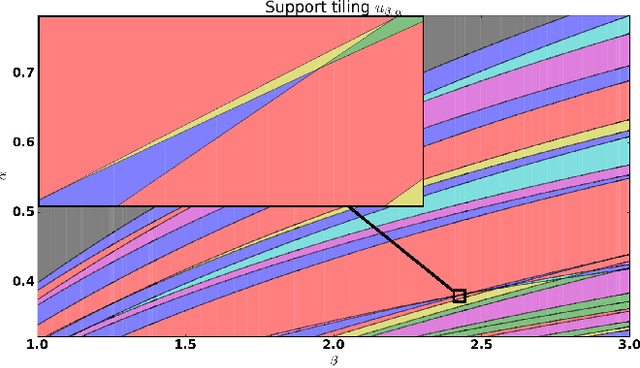
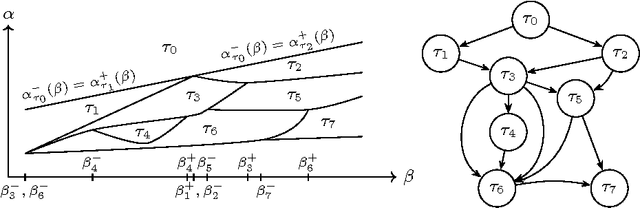
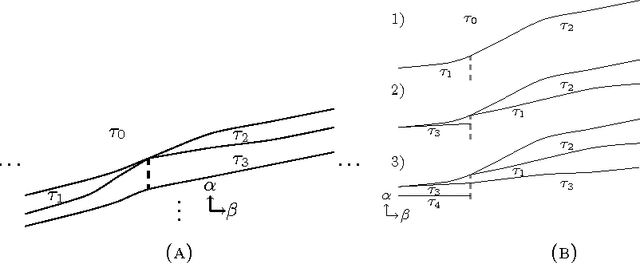
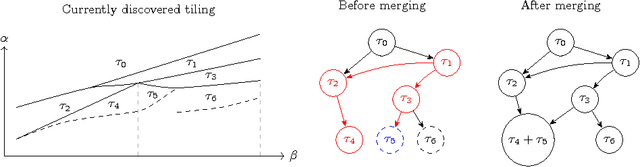
For many algorithms, parameter tuning remains a challenging and critical task, which becomes tedious and infeasible in a multi-parameter setting. Multi-penalty regularization, successfully used for solving undetermined sparse regression of problems of unmixing type where signal and noise are additively mixed, is one of such examples. In this paper, we propose a novel algorithmic framework for an adaptive parameter choice in multi-penalty regularization with a focus on the correct support recovery. Building upon the theory of regularization paths and algorithms for single-penalty functionals, we extend these ideas to a multi-penalty framework by providing an efficient procedure for the construction of regions containing structurally similar solutions, i.e., solutions with the same sparsity and sign pattern, over the whole range of parameters. Combining this with a model selection criterion, we can choose regularization parameters in a data-adaptive manner. Another advantage of our algorithm is that it provides an overview on the solution stability over the whole range of parameters. This can be further exploited to obtain additional insights into the problem of interest. We provide a numerical analysis of our method and compare it to the state-of-the-art single-penalty algorithms for compressed sensing problems in order to demonstrate the robustness and power of the proposed algorithm.