 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOMG-Agent: Toward Robust Missing Modality Generation with Decoupled Coarse-to-Fine Agentic Workflows
Feb 04, 2026Data incompleteness severely impedes the reliability of multimodal systems. Existing reconstruction methods face distinct bottlenecks: conventional parametric/generative models are prone to hallucinations due to over-reliance on internal memory, while retrieval-augmented frameworks struggle with retrieval rigidity. Critically, these end-to-end architectures are fundamentally constrained by Semantic-Detail Entanglement -- a structural conflict between logical reasoning and signal synthesis that compromises fidelity. In this paper, we present \textbf{\underline{O}}mni-\textbf{\underline{M}}odality \textbf{\underline{G}}eneration Agent (\textbf{OMG-Agent}), a novel framework that shifts the paradigm from static mapping to a dynamic coarse-to-fine Agentic Workflow. By mimicking a \textit{deliberate-then-act} cognitive process, OMG-Agent explicitly decouples the task into three synergistic stages: (1) an MLLM-driven Semantic Planner that resolves input ambiguity via Progressive Contextual Reasoning, creating a deterministic structured semantic plan; (2) a non-parametric Evidence Retriever that grounds abstract semantics in external knowledge; and (3) a Retrieval-Injected Executor that utilizes retrieved evidence as flexible feature prompts to overcome rigidity and synthesize high-fidelity details. Extensive experiments on multiple benchmarks demonstrate that OMG-Agent consistently surpasses state-of-the-art methods, maintaining robustness under extreme missingness, e.g., a $2.6$-point gain on CMU-MOSI at $70$\% missing rates.
Mixture of Distributions Matters: Dynamic Sparse Attention for Efficient Video Diffusion Transformers
Jan 14, 2026While Diffusion Transformers (DiTs) have achieved notable progress in video generation, this long-sequence generation task remains constrained by the quadratic complexity inherent to self-attention mechanisms, creating significant barriers to practical deployment. Although sparse attention methods attempt to address this challenge, existing approaches either rely on oversimplified static patterns or require computationally expensive sampling operations to achieve dynamic sparsity, resulting in inaccurate pattern predictions and degraded generation quality. To overcome these limitations, we propose a \underline{\textbf{M}}ixtrue-\underline{\textbf{O}}f-\underline{\textbf{D}}istribution \textbf{DiT} (\textbf{MOD-DiT}), a novel sampling-free dynamic attention framework that accurately models evolving attention patterns through a two-stage process. First, MOD-DiT leverages prior information from early denoising steps and adopts a {distributed mixing approach} to model an efficient linear approximation model, which is then used to predict mask patterns for a specific denoising interval. Second, an online block masking strategy dynamically applies these predicted masks while maintaining historical sparsity information, eliminating the need for repetitive sampling operations. Extensive evaluations demonstrate consistent acceleration and quality improvements across multiple benchmarks and model architectures, validating MOD-DiT's effectiveness for efficient, high-quality video generation while overcoming the computational limitations of traditional sparse attention approaches.
An Uncertainty-Driven Adaptive Self-Alignment Framework for Large Language Models
Jul 23, 2025Large Language Models (LLMs) have demonstrated remarkable progress in instruction following and general-purpose reasoning. However, achieving high-quality alignment with human intent and safety norms without human annotations remains a fundamental challenge. In this work, we propose an Uncertainty-Driven Adaptive Self-Alignment (UDASA) framework designed to improve LLM alignment in a fully automated manner. UDASA first generates multiple responses for each input and quantifies output uncertainty across three dimensions: semantics, factuality, and value alignment. Based on these uncertainty scores, the framework constructs preference pairs and categorizes training samples into three stages, conservative, moderate, and exploratory, according to their uncertainty difference. The model is then optimized progressively across these stages. In addition, we conduct a series of preliminary studies to validate the core design assumptions and provide strong empirical motivation for the proposed framework. Experimental results show that UDASA outperforms existing alignment methods across multiple tasks, including harmlessness, helpfulness, truthfulness, and controlled sentiment generation, significantly improving model performance.
Human Stone Toolmaking Action Grammar (HSTAG): A Challenging Benchmark for Fine-grained Motor Behavior Recognition
Oct 10, 2024Action recognition has witnessed the development of a growing number of novel algorithms and datasets in the past decade. However, the majority of public benchmarks were constructed around activities of daily living and annotated at a rather coarse-grained level, which lacks diversity in domain-specific datasets, especially for rarely seen domains. In this paper, we introduced Human Stone Toolmaking Action Grammar (HSTAG), a meticulously annotated video dataset showcasing previously undocumented stone toolmaking behaviors, which can be used for investigating the applications of advanced artificial intelligence techniques in understanding a rapid succession of complex interactions between two hand-held objects. HSTAG consists of 18,739 video clips that record 4.5 hours of experts' activities in stone toolmaking. Its unique features include (i) brief action durations and frequent transitions, mirroring the rapid changes inherent in many motor behaviors; (ii) multiple angles of view and switches among multiple tools, increasing intra-class variability; (iii) unbalanced class distributions and high similarity among different action sequences, adding difficulty in capturing distinct patterns for each action. Several mainstream action recognition models are used to conduct experimental analysis, which showcases the challenges and uniqueness of HSTAG https://nyu.databrary.org/volume/1697.
Large Language Model Aided QoS Prediction for Service Recommendation
Aug 05, 2024



Large language models (LLMs) have seen rapid improvement in the recent years, and are used in a wider range of applications. After being trained on large text corpus, LLMs obtain the capability of extracting rich features from textual data. Such capability is potentially useful for the web service recommendation task, where the web users and services have intrinsic attributes that can be described using natural language sentences and are useful for recommendation. In this paper, we explore the possibility and practicality of using LLMs for web service recommendation. We propose the large language model aided QoS prediction (llmQoS) model, which use LLMs to extract useful information from attributes of web users and services via descriptive sentences. This information is then used in combination with the QoS values of historical interactions of users and services, to predict QoS values for any given user-service pair. Our proposed model is shown to overcome the data sparsity issue for QoS prediction. We show that on the WSDream dataset, llmQoS outperforms comparable baseline models consistently.
Adversarial Distillation for Ordered Top-k Attacks
May 25, 2019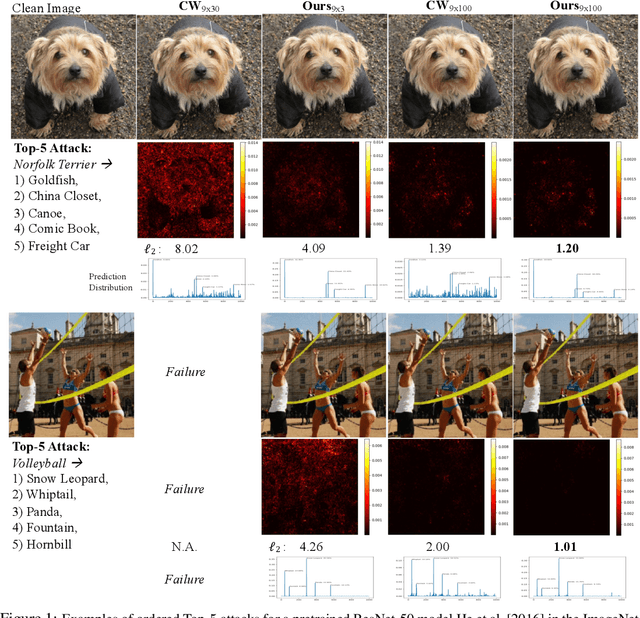

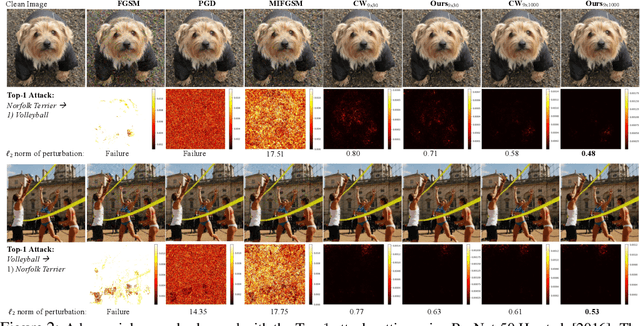
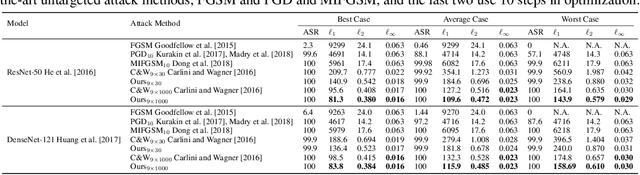
Deep Neural Networks (DNNs) are vulnerable to adversarial attacks, especially white-box targeted attacks. One scheme of learning attacks is to design a proper adversarial objective function that leads to the imperceptible perturbation for any test image (e.g., the Carlini-Wagner (C&W) method). Most methods address targeted attacks in the Top-1 manner. In this paper, we propose to learn ordered Top-k attacks (k>= 1) for image classification tasks, that is to enforce the Top-k predicted labels of an adversarial example to be the k (randomly) selected and ordered labels (the ground-truth label is exclusive). To this end, we present an adversarial distillation framework: First, we compute an adversarial probability distribution for any given ordered Top-k targeted labels with respect to the ground-truth of a test image. Then, we learn adversarial examples by minimizing the Kullback-Leibler (KL) divergence together with the perturbation energy penalty, similar in spirit to the network distillation method. We explore how to leverage label semantic similarities in computing the targeted distributions, leading to knowledge-oriented attacks. In experiments, we thoroughly test Top-1 and Top-5 attacks in the ImageNet-1000 validation dataset using two popular DNNs trained with clean ImageNet-1000 train dataset, ResNet-50 and DenseNet-121. For both models, our proposed adversarial distillation approach outperforms the C&W method in the Top-1 setting, as well as other baseline methods. Our approach shows significant improvement in the Top-5 setting against a strong modified C&W method.
Unsupervised Abstractive Meeting Summarization with Multi-Sentence Compression and Budgeted Submodular Maximization
May 14, 2018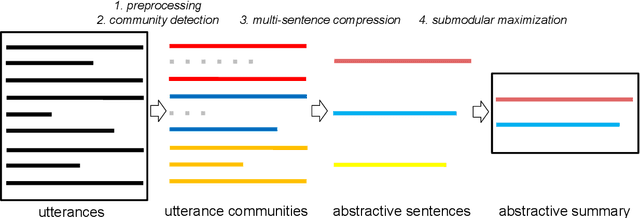

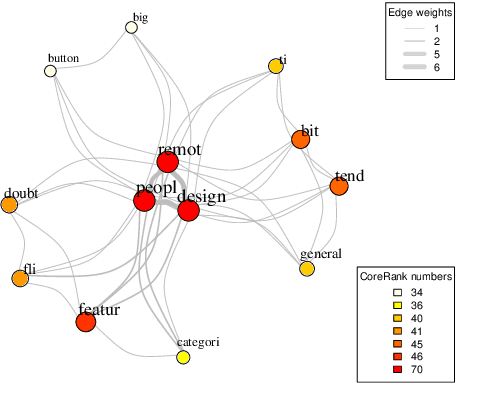
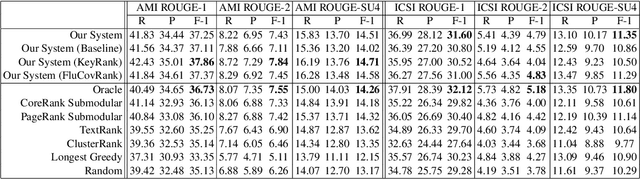
We introduce a novel graph-based framework for abstractive meeting speech summarization that is fully unsupervised and does not rely on any annotations. Our work combines the strengths of multiple recent approaches while addressing their weaknesses. Moreover, we leverage recent advances in word embeddings and graph degeneracy applied to NLP to take exterior semantic knowledge into account, and to design custom diversity and informativeness measures. Experiments on the AMI and ICSI corpus show that our system improves on the state-of-the-art. Code and data are publicly available, and our system can be interactively tested.