 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnveiling Deep Semantic Uncertainty Perception for Language-Anchored Multi-modal Vision-Brain Alignment
Nov 06, 2025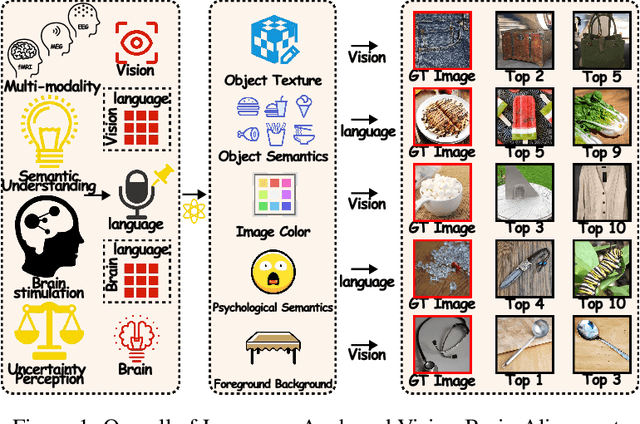
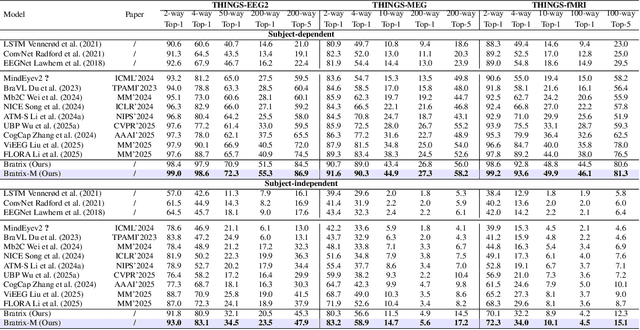
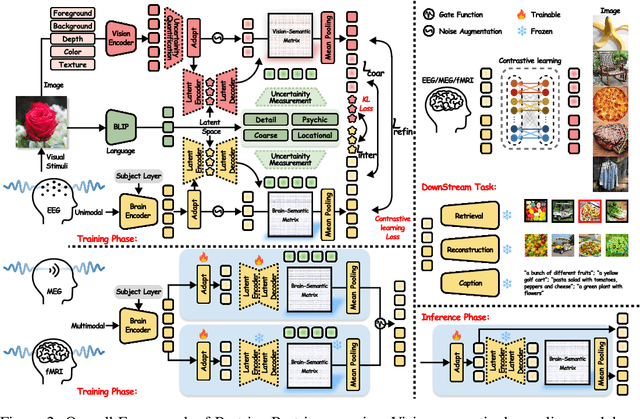
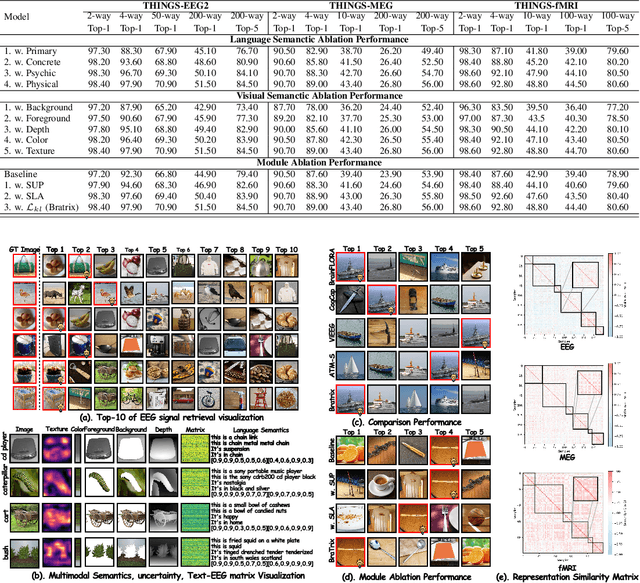
Unveiling visual semantics from neural signals such as EEG, MEG, and fMRI remains a fundamental challenge due to subject variability and the entangled nature of visual features. Existing approaches primarily align neural activity directly with visual embeddings, but visual-only representations often fail to capture latent semantic dimensions, limiting interpretability and deep robustness. To address these limitations, we propose Bratrix, the first end-to-end framework to achieve multimodal Language-Anchored Vision-Brain alignment. Bratrix decouples visual stimuli into hierarchical visual and linguistic semantic components, and projects both visual and brain representations into a shared latent space, enabling the formation of aligned visual-language and brain-language embeddings. To emulate human-like perceptual reliability and handle noisy neural signals, Bratrix incorporates a novel uncertainty perception module that applies uncertainty-aware weighting during alignment. By leveraging learnable language-anchored semantic matrices to enhance cross-modal correlations and employing a two-stage training strategy of single-modality pretraining followed by multimodal fine-tuning, Bratrix-M improves alignment precision. Extensive experiments on EEG, MEG, and fMRI benchmarks demonstrate that Bratrix improves retrieval, reconstruction, and captioning performance compared to state-of-the-art methods, specifically surpassing 14.3% in 200-way EEG retrieval task. Code and model are available.
3D-CLMI: A Motor Imagery EEG Classification Model via Fusion of 3D-CNN and LSTM with Attention
Dec 20, 2023Due to the limitations in the accuracy and robustness of current electroencephalogram (EEG) classification algorithms, applying motor imagery (MI) for practical Brain-Computer Interface (BCI) applications remains challenging. This paper proposed a model that combined a three-dimensional convolutional neural network (CNN) with a long short-term memory (LSTM) network with attention to classify MI-EEG signals. This model combined MI-EEG signals from different channels into three-dimensional features and extracted spatial features through convolution operations with multiple three-dimensional convolutional kernels of different scales. At the same time, to ensure the integrity of the extracted MI-EEG signal temporal features, the LSTM network was directly trained on the preprocessed raw signal. Finally, the features obtained from these two networks were combined and used for classification. Experimental results showed that this model achieved a classification accuracy of 92.7% and an F1-score of 0.91 on the public dataset BCI Competition IV dataset 2a, which were both higher than the state-of-the-art models in the field of MI tasks. Additionally, 12 participants were invited to complete a four-class MI task in our lab, and experiments on the collected dataset showed that the 3D-CLMI model also maintained the highest classification accuracy and F1-score. The model greatly improved the classification accuracy of users' motor imagery intentions, giving brain-computer interfaces better application prospects in emerging fields such as autonomous vehicles and medical rehabilitation.