 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoBEV: Learning Geometric BEV Representation for Multi-view 3D Object Detection
Sep 03, 2024



Bird's-Eye-View (BEV) representation has emerged as a mainstream paradigm for multi-view 3D object detection, demonstrating impressive perceptual capabilities. However, existing methods overlook the geometric quality of BEV representation, leaving it in a low-resolution state and failing to restore the authentic geometric information of the scene. In this paper, we identify the reasons why previous approaches are constrained by low BEV representation resolution and propose Radial-Cartesian BEV Sampling (RC-Sampling), enabling efficient generation of high-resolution dense BEV representations without the need for complex operators. Additionally, we design a novel In-Box Label to substitute the traditional depth label generated from the LiDAR points. This label reflects the actual geometric structure of objects rather than just their surfaces, injecting real-world geometric information into the BEV representation. Furthermore, in conjunction with the In-Box Label, a Centroid-Aware Inner Loss (CAI Loss) is developed to capture the fine-grained inner geometric structure of objects. Finally, we integrate the aforementioned modules into a novel multi-view 3D object detection framework, dubbed GeoBEV. Extensive experiments on the nuScenes dataset exhibit that GeoBEV achieves state-of-the-art performance, highlighting its effectiveness.
Pixel-Level Domain Adaptation: A New Perspective for Enhancing Weakly Supervised Semantic Segmentation
Aug 04, 2024



Recent attention has been devoted to the pursuit of learning semantic segmentation models exclusively from image tags, a paradigm known as image-level Weakly Supervised Semantic Segmentation (WSSS). Existing attempts adopt the Class Activation Maps (CAMs) as priors to mine object regions yet observe the imbalanced activation issue, where only the most discriminative object parts are located. In this paper, we argue that the distribution discrepancy between the discriminative and the non-discriminative parts of objects prevents the model from producing complete and precise pseudo masks as ground truths. For this purpose, we propose a Pixel-Level Domain Adaptation (PLDA) method to encourage the model in learning pixel-wise domain-invariant features. Specifically, a multi-head domain classifier trained adversarially with the feature extraction is introduced to promote the emergence of pixel features that are invariant with respect to the shift between the source (i.e., the discriminative object parts) and the target (\textit{i.e.}, the non-discriminative object parts) domains. In addition, we come up with a Confident Pseudo-Supervision strategy to guarantee the discriminative ability of each pixel for the segmentation task, which serves as a complement to the intra-image domain adversarial training. Our method is conceptually simple, intuitive and can be easily integrated into existing WSSS methods. Taking several strong baseline models as instances, we experimentally demonstrate the effectiveness of our approach under a wide range of settings.
Improving Multi-Person Pose Tracking with A Confidence Network
Oct 29, 2023



Human pose estimation and tracking are fundamental tasks for understanding human behaviors in videos. Existing top-down framework-based methods usually perform three-stage tasks: human detection, pose estimation and tracking. Although promising results have been achieved, these methods rely heavily on high-performance detectors and may fail to track persons who are occluded or miss-detected. To overcome these problems, in this paper, we develop a novel keypoint confidence network and a tracking pipeline to improve human detection and pose estimation in top-down approaches. Specifically, the keypoint confidence network is designed to determine whether each keypoint is occluded, and it is incorporated into the pose estimation module. In the tracking pipeline, we propose the Bbox-revision module to reduce missing detection and the ID-retrieve module to correct lost trajectories, improving the performance of the detection stage. Experimental results show that our approach is universal in human detection and pose estimation, achieving state-of-the-art performance on both PoseTrack 2017 and 2018 datasets.
D$^{\bf{3}}$: Duplicate Detection Decontaminator for Multi-Athlete Tracking in Sports Videos
Sep 25, 2022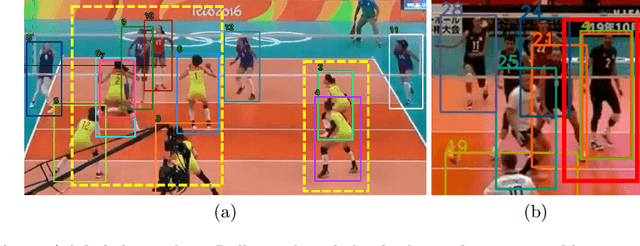
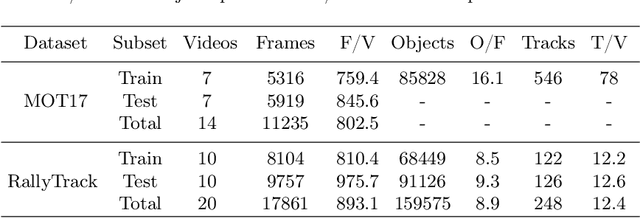
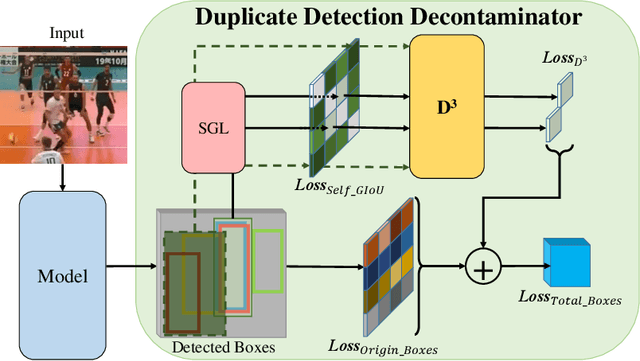

Tracking multiple athletes in sports videos is a very challenging Multi-Object Tracking (MOT) task, since athletes often have the same appearance and are intimately covered with each other, making a common occlusion problem becomes an abhorrent duplicate detection. In this paper, the duplicate detection is newly and precisely defined as occlusion misreporting on the same athlete by multiple detection boxes in one frame. To address this problem, we meticulously design a novel transformer-based Duplicate Detection Decontaminator (D$^3$) for training, and a specific algorithm Rally-Hungarian (RH) for matching. Once duplicate detection occurs, D$^3$ immediately modifies the procedure by generating enhanced boxes losses. RH, triggered by the team sports substitution rules, is exceedingly suitable for sports videos. Moreover, to complement the tracking dataset that without shot changes, we release a new dataset based on sports video named RallyTrack. Extensive experiments on RallyTrack show that combining D$^3$ and RH can dramatically improve the tracking performance with 9.2 in MOTA and 4.5 in HOTA. Meanwhile, experiments on MOT-series and DanceTrack discover that D$^3$ can accelerate convergence during training, especially save up to 80 percent of the original training time on MOT17. Finally, our model, which is trained only with volleyball videos, can be applied directly to basketball and soccer videos for MAT, which shows priority of our method. Our dataset is available at https://github.com/heruihr/rallytrack.
Learning from Future: A Novel Self-Training Framework for Semantic Segmentation
Sep 18, 2022



Self-training has shown great potential in semi-supervised learning. Its core idea is to use the model learned on labeled data to generate pseudo-labels for unlabeled samples, and in turn teach itself. To obtain valid supervision, active attempts typically employ a momentum teacher for pseudo-label prediction yet observe the confirmation bias issue, where the incorrect predictions may provide wrong supervision signals and get accumulated in the training process. The primary cause of such a drawback is that the prevailing self-training framework acts as guiding the current state with previous knowledge, because the teacher is updated with the past student only. To alleviate this problem, we propose a novel self-training strategy, which allows the model to learn from the future. Concretely, at each training step, we first virtually optimize the student (i.e., caching the gradients without applying them to the model weights), then update the teacher with the virtual future student, and finally ask the teacher to produce pseudo-labels for the current student as the guidance. In this way, we manage to improve the quality of pseudo-labels and thus boost the performance. We also develop two variants of our future-self-training (FST) framework through peeping at the future both deeply (FST-D) and widely (FST-W). Taking the tasks of unsupervised domain adaptive semantic segmentation and semi-supervised semantic segmentation as the instances, we experimentally demonstrate the effectiveness and superiority of our approach under a wide range of settings. Code will be made publicly available.
SparseTT: Visual Tracking with Sparse Transformers
May 08, 2022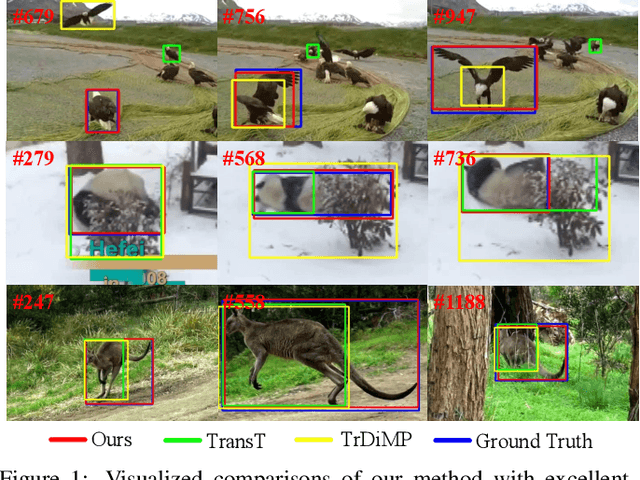
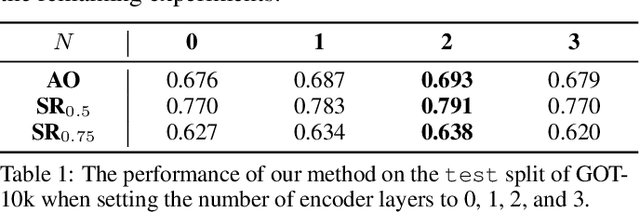
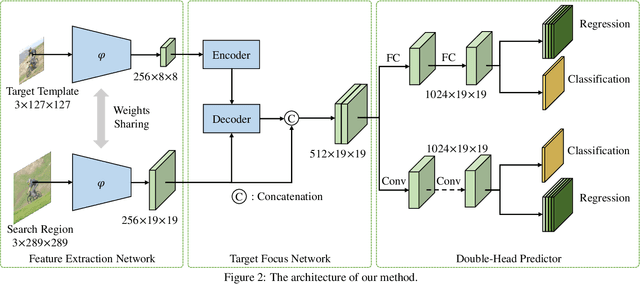
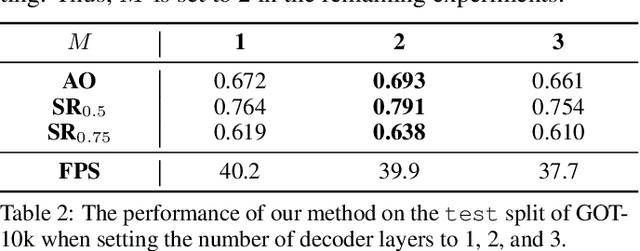
Transformers have been successfully applied to the visual tracking task and significantly promote tracking performance. The self-attention mechanism designed to model long-range dependencies is the key to the success of Transformers. However, self-attention lacks focusing on the most relevant information in the search regions, making it easy to be distracted by background. In this paper, we relieve this issue with a sparse attention mechanism by focusing the most relevant information in the search regions, which enables a much accurate tracking. Furthermore, we introduce a double-head predictor to boost the accuracy of foreground-background classification and regression of target bounding boxes, which further improve the tracking performance. Extensive experiments show that, without bells and whistles, our method significantly outperforms the state-of-the-art approaches on LaSOT, GOT-10k, TrackingNet, and UAV123, while running at 40 FPS. Notably, the training time of our method is reduced by 75% compared to that of TransT. The source code and models are available at https://github.com/fzh0917/SparseTT.
Segmentation-Reconstruction-Guided Facial Image De-occlusion
Dec 15, 2021
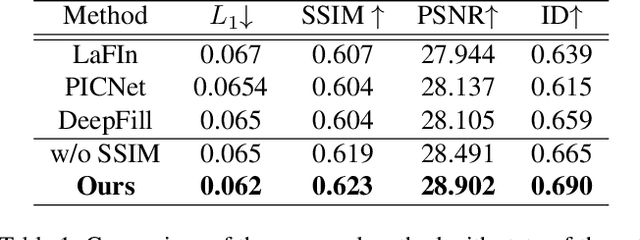
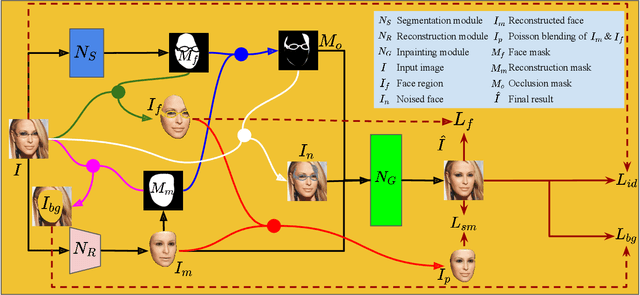
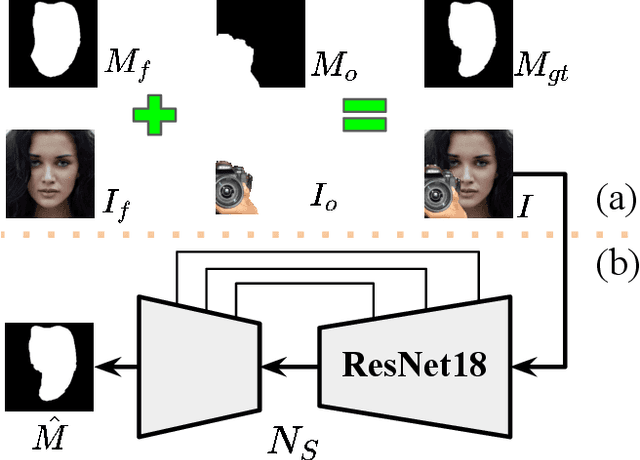
Occlusions are very common in face images in the wild, leading to the degraded performance of face-related tasks. Although much effort has been devoted to removing occlusions from face images, the varying shapes and textures of occlusions still challenge the robustness of current methods. As a result, current methods either rely on manual occlusion masks or only apply to specific occlusions. This paper proposes a novel face de-occlusion model based on face segmentation and 3D face reconstruction, which automatically removes all kinds of face occlusions with even blurred boundaries,e.g., hairs. The proposed model consists of a 3D face reconstruction module, a face segmentation module, and an image generation module. With the face prior and the occlusion mask predicted by the first two, respectively, the image generation module can faithfully recover the missing facial textures. To supervise the training, we further build a large occlusion dataset, with both manually labeled and synthetic occlusions. Qualitative and quantitative results demonstrate the effectiveness and robustness of the proposed method.
Weakly Supervised Semantic Segmentation by Pixel-to-Prototype Contrast
Oct 14, 2021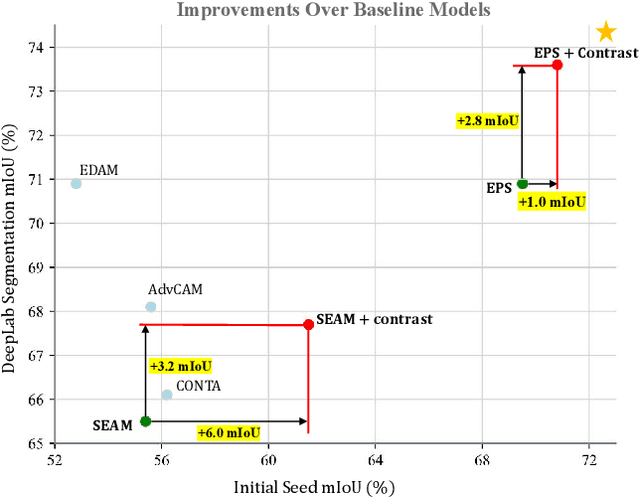
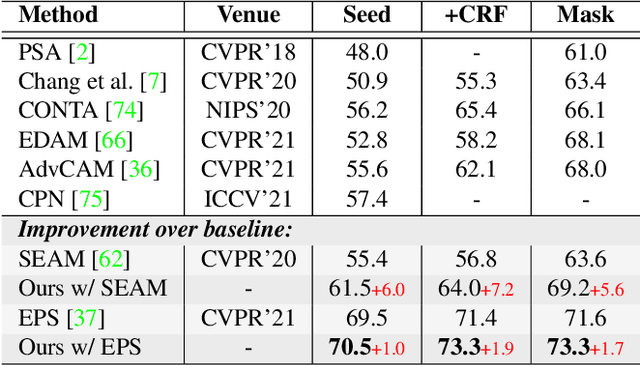
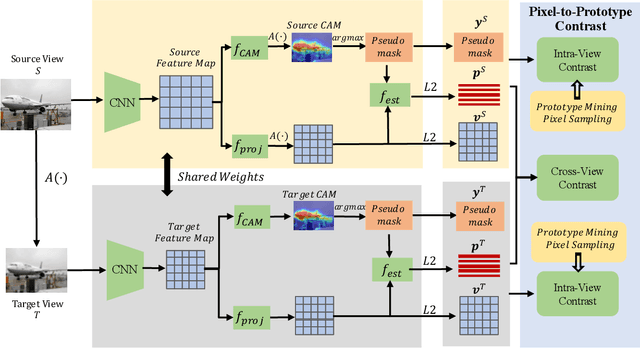
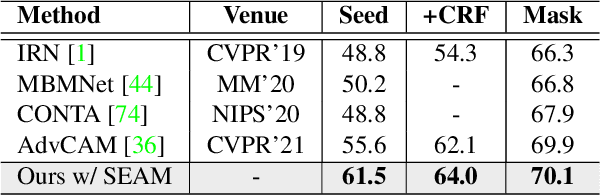
Though image-level weakly supervised semantic segmentation (WSSS) has achieved great progress with Class Activation Map (CAM) as the cornerstone, the large supervision gap between classification and segmentation still hampers the model to generate more complete and precise pseudo masks for segmentation. In this study, we explore two implicit but intuitive constraints, i.e., cross-view feature semantic consistency and intra(inter)-class compactness(dispersion), to narrow the supervision gap. To this end, we propose two novel pixel-to-prototype contrast regularization terms that are conducted cross different views and within per single view of an image, respectively. Besides, we adopt two sample mining strategies, named semi-hard prototype mining and hard pixel sampling, to better leverage hard examples while reducing incorrect contrasts caused due to the absence of precise pixel-wise labels. Our method can be seamlessly incorporated into existing WSSS models without any changes to the base network and does not incur any extra inference burden. Experiments on standard benchmark show that our method consistently improves two strong baselines by large margins, demonstrating the effectiveness of our method. Specifically, built on top of SEAM, we improve the initial seed mIoU on PASCAL VOC 2012 from 55.4% to 61.5%. Moreover, armed with our method, we increase the segmentation mIoU of EPS from 70.8% to 73.6%, achieving new state-of-the-art.
Weakly-Supervised Photo-realistic Texture Generation for 3D Face Reconstruction
Jun 14, 2021
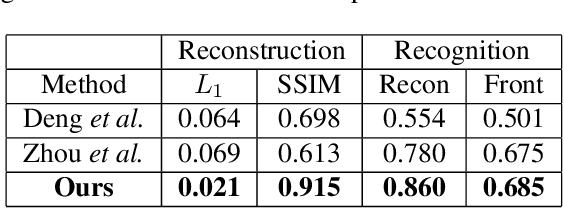
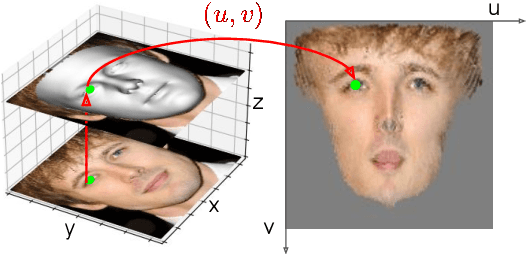
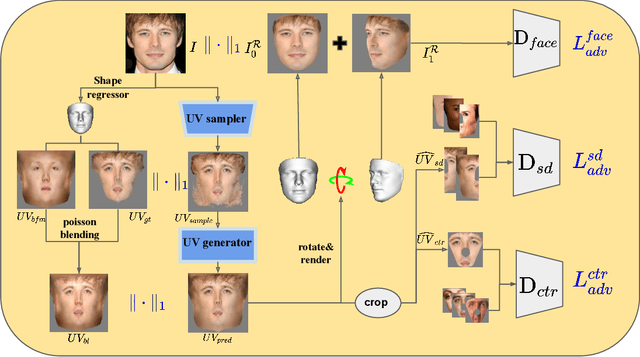
Although much progress has been made recently in 3D face reconstruction, most previous work has been devoted to predicting accurate and fine-grained 3D shapes. In contrast, relatively little work has focused on generating high-fidelity face textures. Compared with the prosperity of photo-realistic 2D face image generation, high-fidelity 3D face texture generation has yet to be studied. In this paper, we proposed a novel UV map generation model that predicts the UV map from a single face image. The model consists of a UV sampler and a UV generator. By selectively sampling the input face image's pixels and adjusting their relative locations, the UV sampler generates an incomplete UV map that could faithfully reconstruct the original face. Missing textures in the incomplete UV map are further full-filled by the UV generator. The training is based on pseudo ground truth blended by the 3DMM texture and the input face texture, thus weakly supervised. To deal with the artifacts in the imperfect pseudo UV map, multiple partial UV map discriminators are leveraged.
Pixel Sampling for Style Preserving Face Pose Editing
Jun 14, 2021


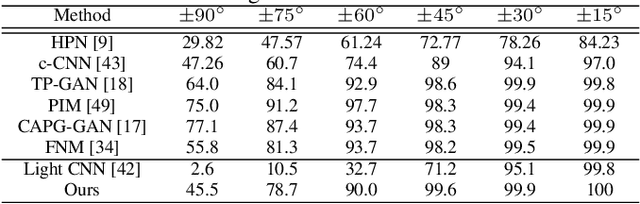
The existing auto-encoder based face pose editing methods primarily focus on modeling the identity preserving ability during pose synthesis, but are less able to preserve the image style properly, which refers to the color, brightness, saturation, etc. In this paper, we take advantage of the well-known frontal/profile optical illusion and present a novel two-stage approach to solve the aforementioned dilemma, where the task of face pose manipulation is cast into face inpainting. By selectively sampling pixels from the input face and slightly adjust their relative locations with the proposed ``Pixel Attention Sampling" module, the face editing result faithfully keeps the identity information as well as the image style unchanged. By leveraging high-dimensional embedding at the inpainting stage, finer details are generated. Further, with the 3D facial landmarks as guidance, our method is able to manipulate face pose in three degrees of freedom, i.e., yaw, pitch, and roll, resulting in more flexible face pose editing than merely controlling the yaw angle as usually achieved by the current state-of-the-art. Both the qualitative and quantitative evaluations validate the superiority of the proposed approach.