 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Language Model for Large Scale Search, Recommendation, and Reasoning
Mar 18, 2026LLMs are increasingly applied to recommendation, retrieval, and reasoning, yet deploying a single end-to-end model that can jointly support these behaviors over large, heterogeneous catalogs remains challenging. Such systems must generate unambiguous references to real items, handle multiple entity types, and operate under strict latency and reliability constraints requirements that are difficult to satisfy with text-only generation. While tool-augmented recommender systems address parts of this problem, they introduce orchestration complexity and limit end-to-end optimization. We view this setting as an instance of a broader research problem: how to adapt LLMs to reason jointly over multiple-domain entities, users, and language in a fully self-contained manner. To this end, we introduce NEO, a framework that adapts a pre-trained decoder-only LLM into a tool-free, catalog-grounded generator. NEO represents items as SIDs and trains a single model to interleave natural language and typed item identifiers within a shared sequence. Text prompts control the task, target entity type, and output format (IDs, text, or mixed), while constrained decoding guarantees catalog-valid item generation without restricting free-form text. We refer to this instruction-conditioned controllability as language-steerability. We treat SIDs as a distinct modality and study design choices for integrating discrete entity representations into LLMs via staged alignment and instruction tuning. We evaluate NEO at scale on a real-world catalog of over 10M items across multiple media types and discovery tasks, including recommendation, search, and user understanding. In offline experiments, NEO consistently outperforms strong task-specific baselines and exhibits cross-task transfer, demonstrating a practical path toward consolidating large-scale discovery capabilities into a single language-steerable generative model.
Pre-training Is All You Need: An Application to Commonsense Reasoning
Apr 29, 2020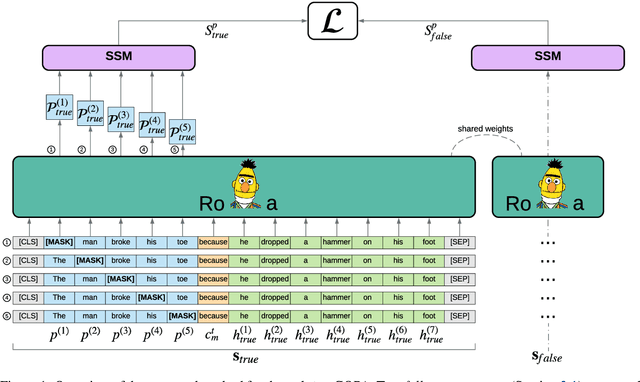


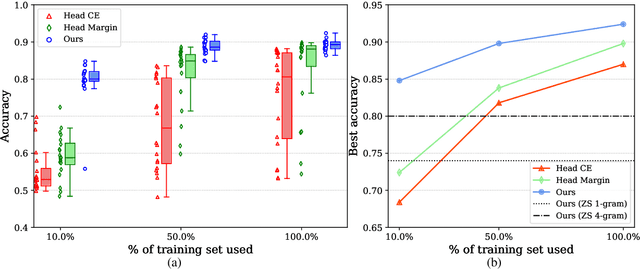
Fine-tuning of pre-trained transformer models has become the standard approach for solving common NLP tasks. Most of the existing approaches rely on a randomly initialized classifier on top of such networks. We argue that this fine-tuning procedure is sub-optimal as the pre-trained model has no prior on the specific classifier labels, while it might have already learned an intrinsic textual representation of the task. In this paper, we introduce a new scoring method that casts a plausibility ranking task in a full-text format and leverages the masked language modeling head tuned during the pre-training phase. We study commonsense reasoning tasks where the model must rank a set of hypotheses given a premise, focusing on the COPA, Swag, HellaSwag and CommonsenseQA datasets. By exploiting our scoring method without fine-tuning, we are able to produce strong baselines (e.g. 80% test accuracy on COPA) that are comparable to supervised approaches. Moreover, when fine-tuning directly on the proposed scoring function, we show that our method provides a much more stable training phase across random restarts (e.g $\times 10$ standard deviation reduction on COPA test accuracy) and requires less annotated data than the standard classifier approach to reach equivalent performances.