 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChain-of-Image Generation: Toward Monitorable and Controllable Image Generation
Dec 09, 2025While state-of-the-art image generation models achieve remarkable visual quality, their internal generative processes remain a "black box." This opacity limits human observation and intervention, and poses a barrier to ensuring model reliability, safety, and control. Furthermore, their non-human-like workflows make them difficult for human observers to interpret. To address this, we introduce the Chain-of-Image Generation (CoIG) framework, which reframes image generation as a sequential, semantic process analogous to how humans create art. Similar to the advantages in monitorability and performance that Chain-of-Thought (CoT) brought to large language models (LLMs), CoIG can produce equivalent benefits in text-to-image generation. CoIG utilizes an LLM to decompose a complex prompt into a sequence of simple, step-by-step instructions. The image generation model then executes this plan by progressively generating and editing the image. Each step focuses on a single semantic entity, enabling direct monitoring. We formally assess this property using two novel metrics: CoIG Readability, which evaluates the clarity of each intermediate step via its corresponding output; and Causal Relevance, which quantifies the impact of each procedural step on the final generated image. We further show that our framework mitigates entity collapse by decomposing the complex generation task into simple subproblems, analogous to the procedural reasoning employed by CoT. Our experimental results indicate that CoIG substantially enhances quantitative monitorability while achieving competitive compositional robustness compared to established baseline models. The framework is model-agnostic and can be integrated with any image generation model.
P3S-Diffusion:A Selective Subject-driven Generation Framework via Point Supervision
Dec 27, 2024



Recent research in subject-driven generation increasingly emphasizes the importance of selective subject features. Nevertheless, accurately selecting the content in a given reference image still poses challenges, especially when selecting the similar subjects in an image (e.g., two different dogs). Some methods attempt to use text prompts or pixel masks to isolate specific elements. However, text prompts often fall short in precisely describing specific content, and pixel masks are often expensive. To address this, we introduce P3S-Diffusion, a novel architecture designed for context-selected subject-driven generation via point supervision. P3S-Diffusion leverages minimal cost label (e.g., points) to generate subject-driven images. During fine-tuning, it can generate an expanded base mask from these points, obviating the need for additional segmentation models. The mask is employed for inpainting and aligning with subject representation. The P3S-Diffusion preserves fine features of the subjects through Multi-layers Condition Injection. Enhanced by the Attention Consistency Loss for improved training, extensive experiments demonstrate its excellent feature preservation and image generation capabilities.
Does Explicit Prediction Matter in Energy Management Based on Deep Reinforcement Learning?
Aug 11, 2021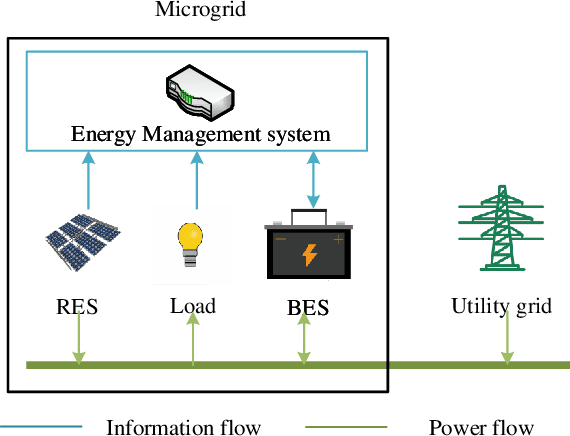
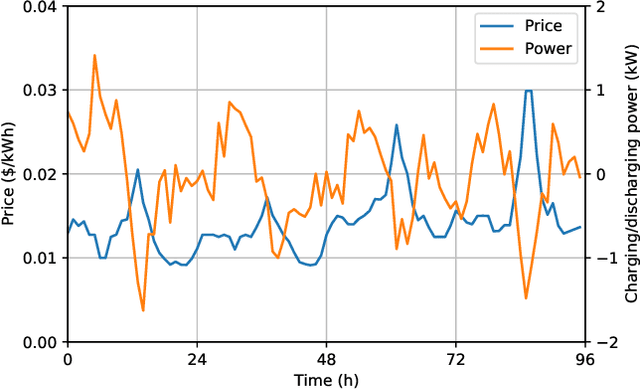
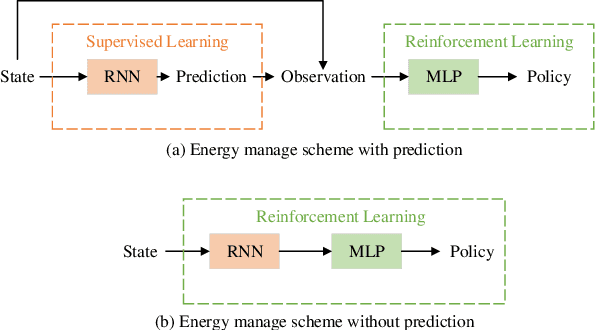
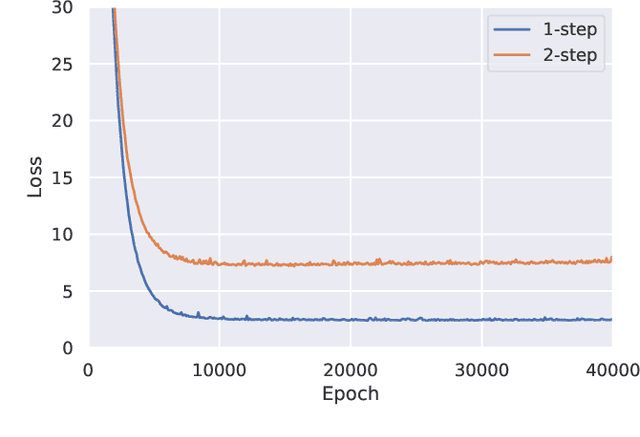
As a model-free optimization and decision-making method, deep reinforcement learning (DRL) has been widely applied to the filed of energy management in energy Internet. While, some DRL-based energy management schemes also incorporate the prediction module used by the traditional model-based methods, which seems to be unnecessary and even adverse. In this work, we present the standard DRL-based energy management scheme with and without prediction. Then, these two schemes are compared in the unified energy management framework. The simulation results demonstrate that the energy management scheme without prediction is superior over the scheme with prediction. This work intends to rectify the misuse of DRL methods in the field of energy management.