 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Capability of Video Question Generation for Expert Knowledge Elicitation
Dec 17, 2025Skilled human interviewers can extract valuable information from experts. This raises a fundamental question: what makes some questions more effective than others? To address this, a quantitative evaluation of question-generation models is essential. Video question generation (VQG) is a topic for video question answering (VideoQA), where questions are generated for given answers. Their evaluation typically focuses on the ability to answer questions, rather than the quality of generated questions. In contrast, we focus on the question quality in eliciting unseen knowledge from human experts. For a continuous improvement of VQG models, we propose a protocol that evaluates the ability by simulating question-answering communication with experts using a question-to-answer retrieval. We obtain the retriever by constructing a novel dataset, EgoExoAsk, which comprises 27,666 QA pairs generated from Ego-Exo4D's expert commentary annotation. The EgoExoAsk training set is used to obtain the retriever, and the benchmark is constructed on the validation set with Ego-Exo4D video segments. Experimental results demonstrate our metric reasonably aligns with question generation settings: models accessing richer context are evaluated better, supporting that our protocol works as intended. The EgoExoAsk dataset is available in https://github.com/omron-sinicx/VQG4ExpertKnowledge .
Zero-shot Composed Image Retrieval Considering Query-target Relationship Leveraging Masked Image-text Pairs
Jun 27, 2024



This paper proposes a novel zero-shot composed image retrieval (CIR) method considering the query-target relationship by masked image-text pairs. The objective of CIR is to retrieve the target image using a query image and a query text. Existing methods use a textual inversion network to convert the query image into a pseudo word to compose the image and text and use a pre-trained visual-language model to realize the retrieval. However, they do not consider the query-target relationship to train the textual inversion network to acquire information for retrieval. In this paper, we propose a novel zero-shot CIR method that is trained end-to-end using masked image-text pairs. By exploiting the abundant image-text pairs that are convenient to obtain with a masking strategy for learning the query-target relationship, it is expected that accurate zero-shot CIR using a retrieval-focused textual inversion network can be realized. Experimental results show the effectiveness of the proposed method.
Does Explicit Prediction Matter in Energy Management Based on Deep Reinforcement Learning?
Aug 11, 2021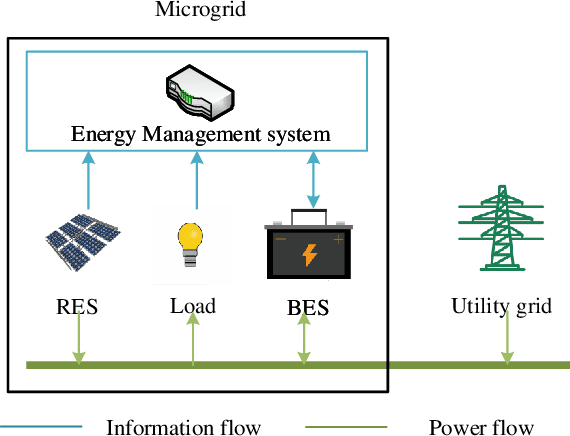
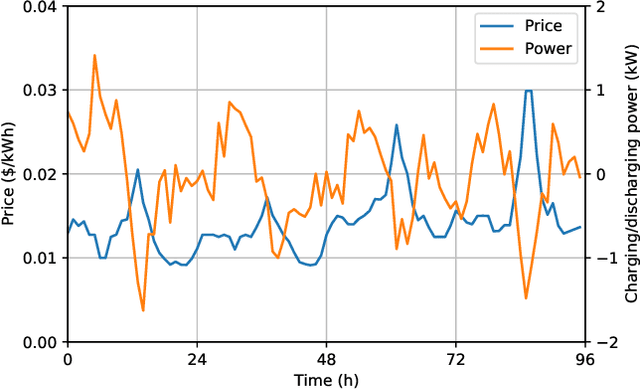
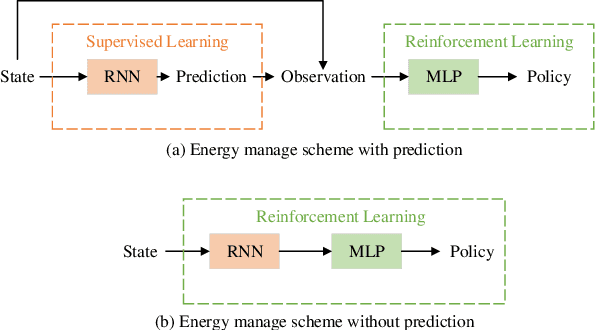
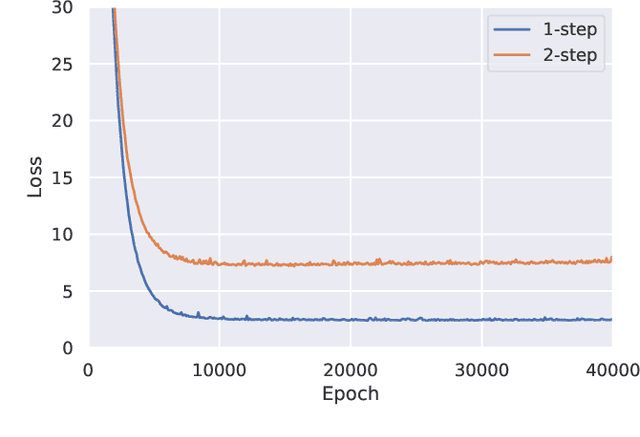
As a model-free optimization and decision-making method, deep reinforcement learning (DRL) has been widely applied to the filed of energy management in energy Internet. While, some DRL-based energy management schemes also incorporate the prediction module used by the traditional model-based methods, which seems to be unnecessary and even adverse. In this work, we present the standard DRL-based energy management scheme with and without prediction. Then, these two schemes are compared in the unified energy management framework. The simulation results demonstrate that the energy management scheme without prediction is superior over the scheme with prediction. This work intends to rectify the misuse of DRL methods in the field of energy management.