 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussianFluent: Gaussian Simulation for Dynamic Scenes with Mixed Materials
Jan 14, 20263D Gaussian Splatting (3DGS) has emerged as a prominent 3D representation for high-fidelity and real-time rendering. Prior work has coupled physics simulation with Gaussians, but predominantly targets soft, deformable materials, leaving brittle fracture largely unresolved. This stems from two key obstacles: the lack of volumetric interiors with coherent textures in GS representation, and the absence of fracture-aware simulation methods for Gaussians. To address these challenges, we introduce GaussianFluent, a unified framework for realistic simulation and rendering of dynamic object states. First, it synthesizes photorealistic interiors by densifying internal Gaussians guided by generative models. Second, it integrates an optimized Continuum Damage Material Point Method (CD-MPM) to enable brittle fracture simulation at remarkably high speed. Our approach handles complex scenarios including mixed-material objects and multi-stage fracture propagation, achieving results infeasible with previous methods. Experiments clearly demonstrate GaussianFluent's capability for photo-realistic, real-time rendering with structurally consistent interiors, highlighting its potential for downstream application, such as VR and Robotics.
Enhanced Random Forest with Image/Patch-Level Learning for Image Understanding
Oct 14, 2014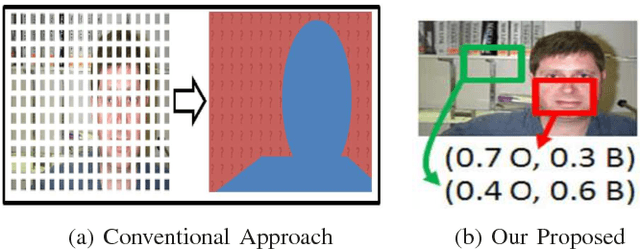
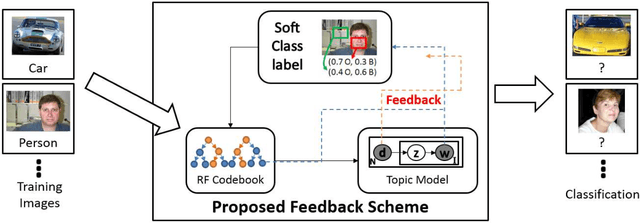
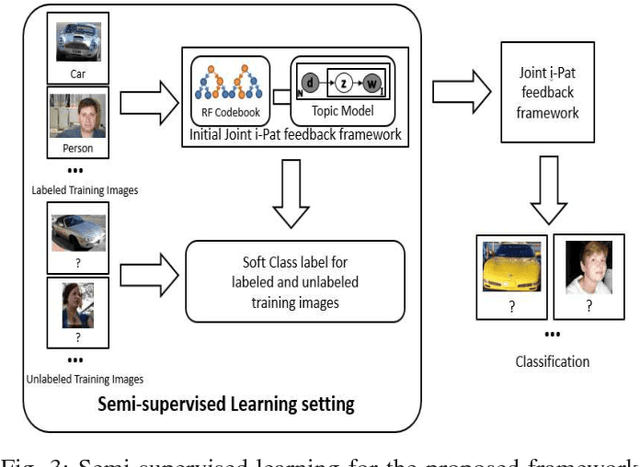
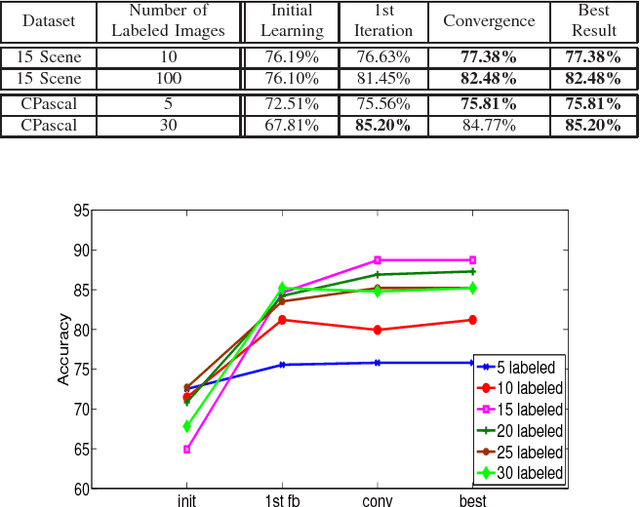
Image understanding is an important research domain in the computer vision due to its wide real-world applications. For an image understanding framework that uses the Bag-of-Words model representation, the visual codebook is an essential part. Random forest (RF) as a tree-structure discriminative codebook has been a popular choice. However, the performance of the RF can be degraded if the local patch labels are poorly assigned. In this paper, we tackle this problem by a novel way to update the RF codebook learning for a more discriminative codebook with the introduction of the soft class labels, estimated from the pLSA model based on a feedback scheme. The feedback scheme is performed on both the image and patch levels respectively, which is in contrast to the state- of-the-art RF codebook learning that focused on either image or patch level only. Experiments on 15-Scene and C-Pascal datasets had shown the effectiveness of the proposed method in image understanding task.