 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhanced Random Forest with Image/Patch-Level Learning for Image Understanding
Oct 14, 2014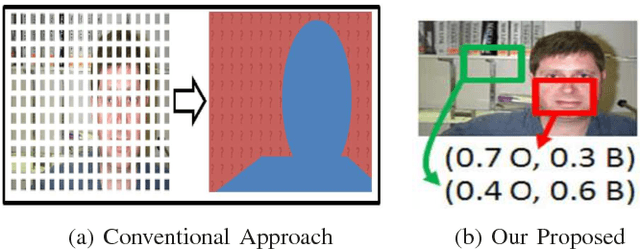
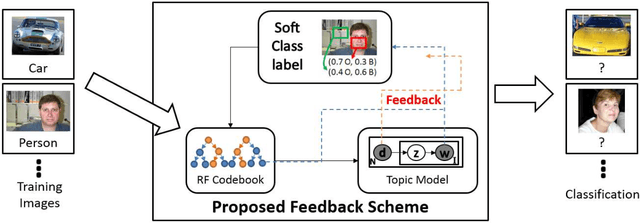
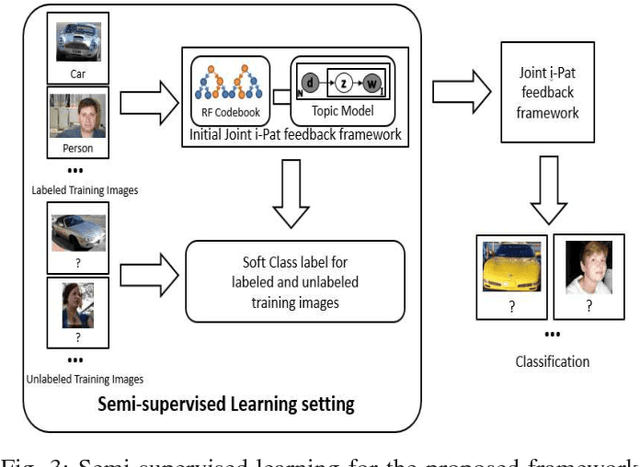
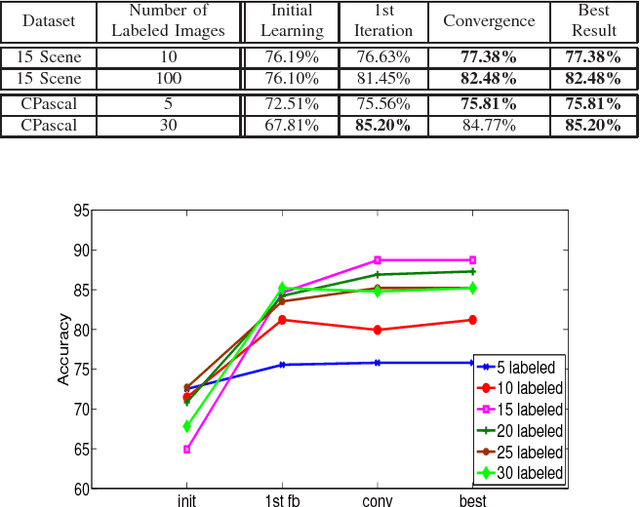
Image understanding is an important research domain in the computer vision due to its wide real-world applications. For an image understanding framework that uses the Bag-of-Words model representation, the visual codebook is an essential part. Random forest (RF) as a tree-structure discriminative codebook has been a popular choice. However, the performance of the RF can be degraded if the local patch labels are poorly assigned. In this paper, we tackle this problem by a novel way to update the RF codebook learning for a more discriminative codebook with the introduction of the soft class labels, estimated from the pLSA model based on a feedback scheme. The feedback scheme is performed on both the image and patch levels respectively, which is in contrast to the state- of-the-art RF codebook learning that focused on either image or patch level only. Experiments on 15-Scene and C-Pascal datasets had shown the effectiveness of the proposed method in image understanding task.
Zero-Shot Object Recognition System based on Topic Model
Oct 14, 2014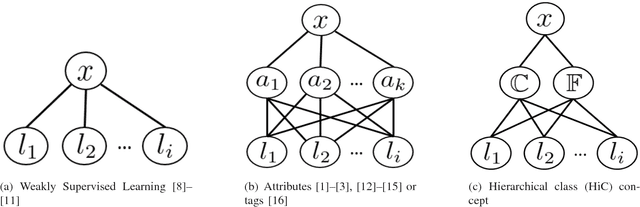
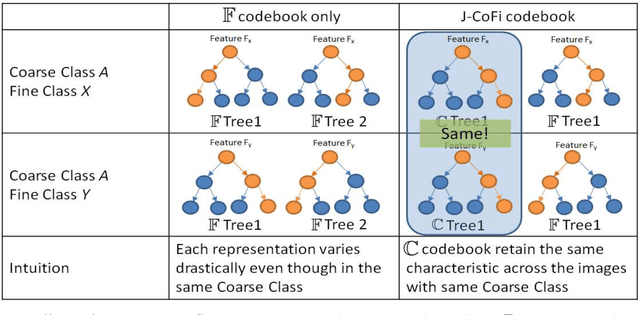
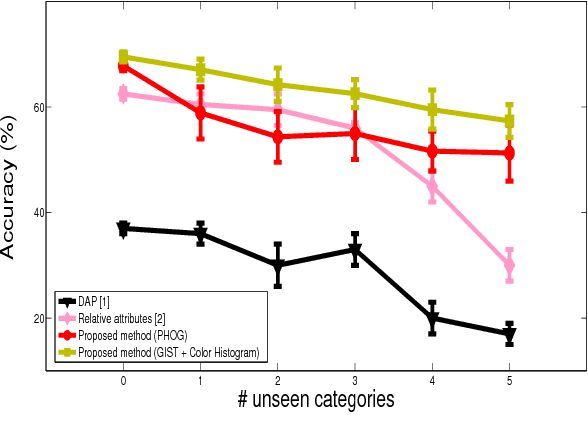
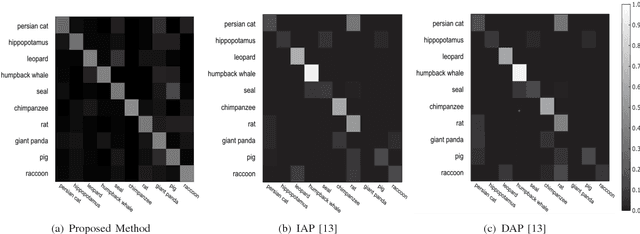
Object recognition systems usually require fully complete manually labeled training data to train the classifier. In this paper, we study the problem of object recognition where the training samples are missing during the classifier learning stage, a task also known as zero-shot learning. We propose a novel zero-shot learning strategy that utilizes the topic model and hierarchical class concept. Our proposed method advanced where cumbersome human annotation stage (i.e. attribute-based classification) is eliminated. We achieve comparable performance with state-of-the-art algorithms in four public datasets: PubFig (67.09%), Cifar-100 (54.85%), Caltech-256 (52.14%), and Animals with Attributes (49.65%) when unseen classes exist in the classification task.