 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStability and Generalization for Randomized Coordinate Descent
Aug 17, 2021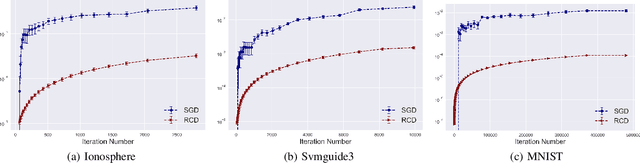
Randomized coordinate descent (RCD) is a popular optimization algorithm with wide applications in solving various machine learning problems, which motivates a lot of theoretical analysis on its convergence behavior. As a comparison, there is no work studying how the models trained by RCD would generalize to test examples. In this paper, we initialize the generalization analysis of RCD by leveraging the powerful tool of algorithmic stability. We establish argument stability bounds of RCD for both convex and strongly convex objectives, from which we develop optimal generalization bounds by showing how to early-stop the algorithm to tradeoff the estimation and optimization. Our analysis shows that RCD enjoys better stability as compared to stochastic gradient descent.
Fine-grained Generalization Analysis of Structured Output Prediction
May 31, 2021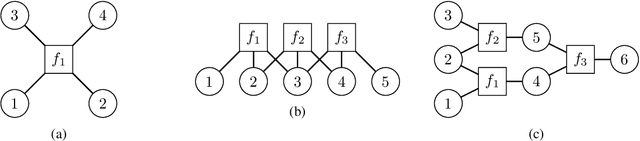
In machine learning we often encounter structured output prediction problems (SOPPs), i.e. problems where the output space admits a rich internal structure. Application domains where SOPPs naturally occur include natural language processing, speech recognition, and computer vision. Typical SOPPs have an extremely large label set, which grows exponentially as a function of the size of the output. Existing generalization analysis implies generalization bounds with at least a square-root dependency on the cardinality $d$ of the label set, which can be vacuous in practice. In this paper, we significantly improve the state of the art by developing novel high-probability bounds with a logarithmic dependency on $d$. Moreover, we leverage the lens of algorithmic stability to develop generalization bounds in expectation without any dependency on $d$. Our results therefore build a solid theoretical foundation for learning in large-scale SOPPs. Furthermore, we extend our results to learning with weakly dependent data.
Stability and Generalization of Stochastic Gradient Methods for Minimax Problems
May 08, 2021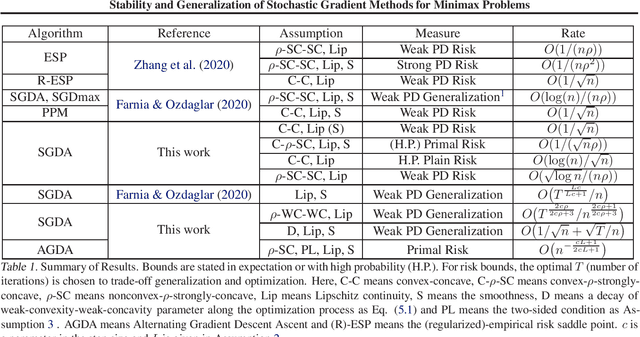
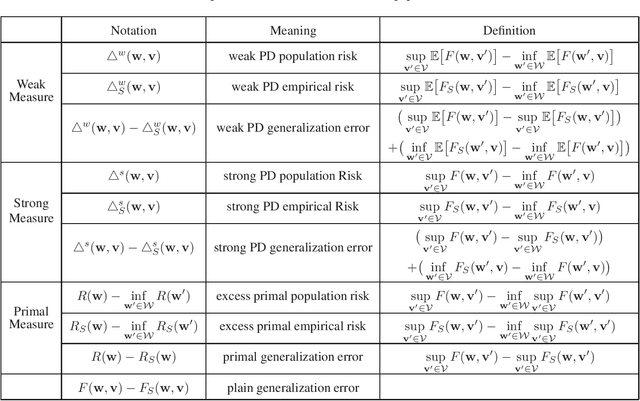

Many machine learning problems can be formulated as minimax problems such as Generative Adversarial Networks (GANs), AUC maximization and robust estimation, to mention but a few. A substantial amount of studies are devoted to studying the convergence behavior of their stochastic gradient-type algorithms. In contrast, there is relatively little work on their generalization, i.e., how the learning models built from training examples would behave on test examples. In this paper, we provide a comprehensive generalization analysis of stochastic gradient methods for minimax problems under both convex-concave and nonconvex-nonconcave cases through the lens of algorithmic stability. We establish a quantitative connection between stability and several generalization measures both in expectation and with high probability. For the convex-concave setting, our stability analysis shows that stochastic gradient descent ascent attains optimal generalization bounds for both smooth and nonsmooth minimax problems. We also establish generalization bounds for both weakly-convex-weakly-concave and gradient-dominated problems.
Fine-grained Generalization Analysis of Vector-valued Learning
Apr 29, 2021
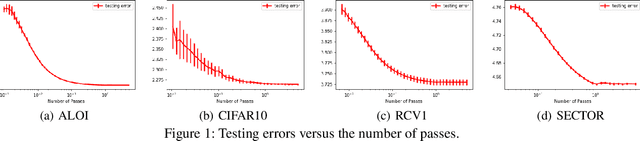
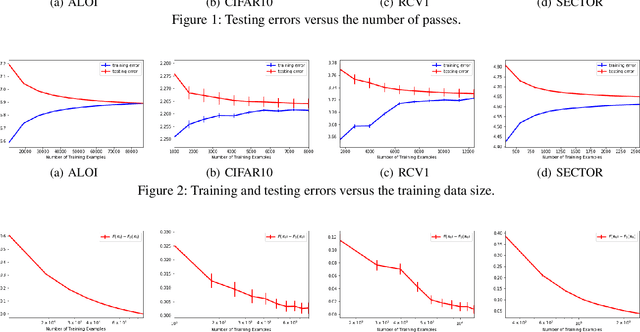

Many fundamental machine learning tasks can be formulated as a problem of learning with vector-valued functions, where we learn multiple scalar-valued functions together. Although there is some generalization analysis on different specific algorithms under the empirical risk minimization principle, a unifying analysis of vector-valued learning under a regularization framework is still lacking. In this paper, we initiate the generalization analysis of regularized vector-valued learning algorithms by presenting bounds with a mild dependency on the output dimension and a fast rate on the sample size. Our discussions relax the existing assumptions on the restrictive constraint of hypothesis spaces, smoothness of loss functions and low-noise condition. To understand the interaction between optimization and learning, we further use our results to derive the first generalization bounds for stochastic gradient descent with vector-valued functions. We apply our general results to multi-class classification and multi-label classification, which yield the first bounds with a logarithmic dependency on the output dimension for extreme multi-label classification with the Frobenius regularization. As a byproduct, we derive a Rademacher complexity bound for loss function classes defined in terms of a general strongly convex function.
Differentially Private SGD with Non-Smooth Loss
Jan 22, 2021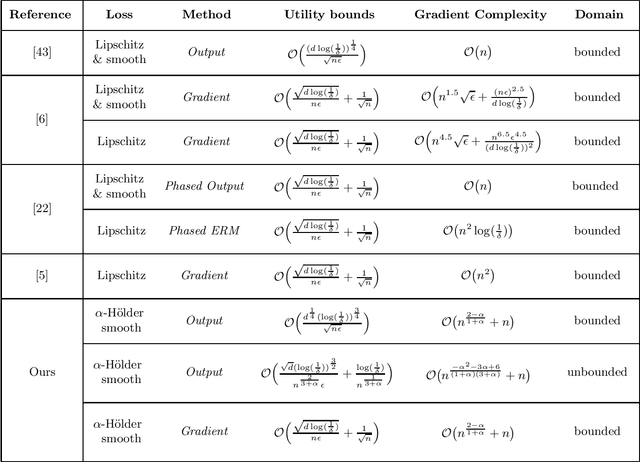
In this paper, we are concerned with differentially private SGD algorithms in the setting of stochastic convex optimization (SCO). Most of existing work requires the loss to be Lipschitz continuous and strongly smooth, and the model parameter to be uniformly bounded. However, these assumptions are restrictive as many popular losses violate these conditions including the hinge loss for SVM, the absolute loss in robust regression, and even the least square loss in an unbounded domain. We significantly relax these restrictive assumptions and establish privacy and generalization (utility) guarantees for private SGD algorithms using output and gradient perturbations associated with non-smooth convex losses. Specifically, the loss function is relaxed to have $\alpha$-H\"{o}lder continuous gradient (referred to as $\alpha$-H\"{o}lder smoothness) which instantiates the Lipschitz continuity ($\alpha=0$) and strong smoothness ($\alpha=1$). We prove that noisy SGD with $\alpha$-H\"older smooth losses using gradient perturbation can guarantee $(\epsilon,\delta)$-differential privacy (DP) and attain optimal excess population risk $O\Big(\frac{\sqrt{d\log(1/\delta)}}{n\epsilon}+\frac{1}{\sqrt{n}}\Big)$, up to logarithmic terms, with gradient complexity (i.e. the total number of iterations) $T =O( n^{2-\alpha\over 1+\alpha}+ n).$ This shows an important trade-off between $\alpha$-H\"older smoothness of the loss and the computational complexity $T$ for private SGD with statistically optimal performance. In particular, our results indicate that $\alpha$-H\"older smoothness with $\alpha\ge {1/2}$ is sufficient to guarantee $(\epsilon,\delta)$-DP of noisy SGD algorithms while achieving optimal excess risk with linear gradient complexity $T = O(n).$
Stochastic Hard Thresholding Algorithms for AUC Maximization
Nov 04, 2020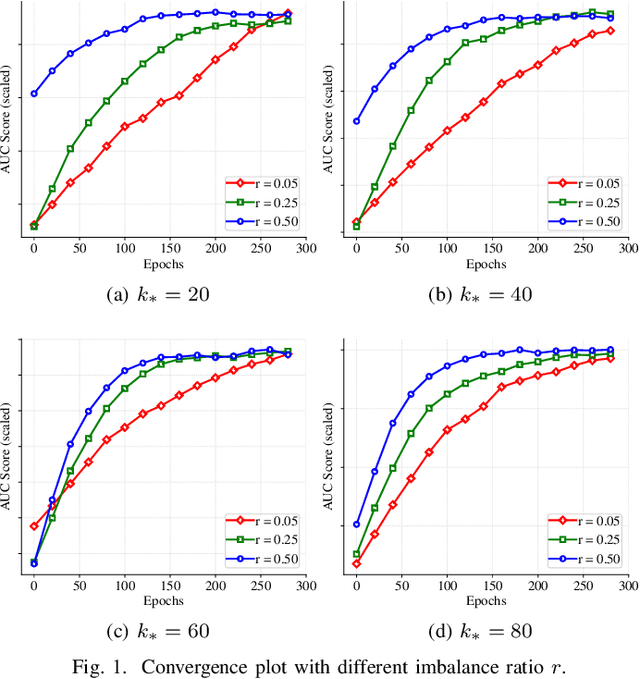
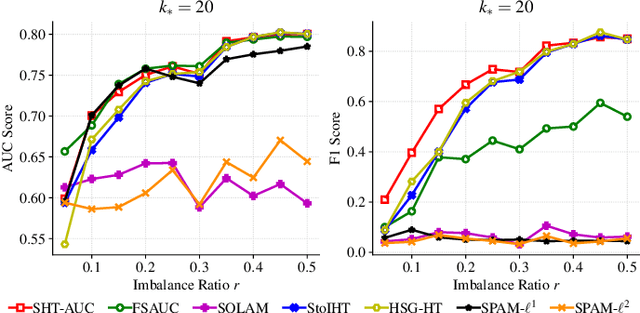
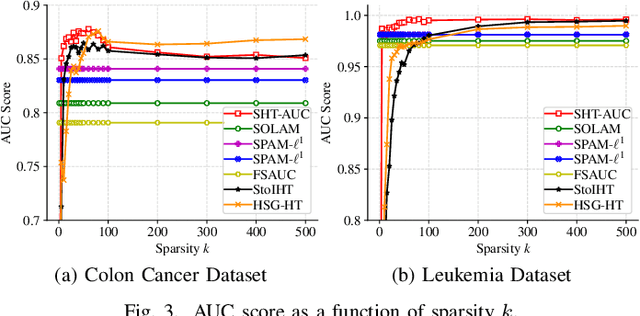
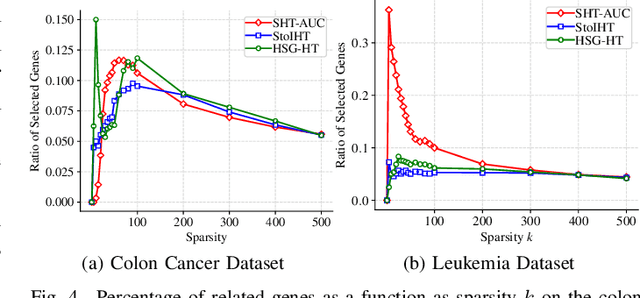
In this paper, we aim to develop stochastic hard thresholding algorithms for the important problem of AUC maximization in imbalanced classification. The main challenge is the pairwise loss involved in AUC maximization. We overcome this obstacle by reformulating the U-statistics objective function as an empirical risk minimization (ERM), from which a stochastic hard thresholding algorithm (\texttt{SHT-AUC}) is developed. To our best knowledge, this is the first attempt to provide stochastic hard thresholding algorithms for AUC maximization with a per-iteration cost $\O(b d)$ where $d$ and $b$ are the dimension of the data and the minibatch size, respectively. We show that the proposed algorithm enjoys the linear convergence rate up to a tolerance error. In particular, we show, if the data is generated from the Gaussian distribution, then its convergence becomes slower as the data gets more imbalanced. We conduct extensive experiments to show the efficiency and effectiveness of the proposed algorithms.
Fine-Grained Analysis of Stability and Generalization for Stochastic Gradient Descent
Jun 15, 2020Recently there are a considerable amount of work devoted to the study of the algorithmic stability and generalization for stochastic gradient descent (SGD). However, the existing stability analysis requires to impose restrictive assumptions on the boundedness of gradients, strong smoothness and convexity of loss functions. In this paper, we provide a fine-grained analysis of stability and generalization for SGD by substantially relaxing these assumptions. Firstly, we establish stability and generalization for SGD by removing the existing bounded gradient assumptions. The key idea is the introduction of a new stability measure called on-average model stability, for which we develop novel bounds controlled by the risks of SGD iterates. This yields generalization bounds depending on the behavior of the best model, and leads to the first-ever-known fast bounds in the low-noise setting using stability approach. Secondly, the smoothness assumption is relaxed by considering loss functions with Holder continuous (sub)gradients for which we show that optimal bounds are still achieved by balancing computation and stability. To our best knowledge, this gives the first-ever-known stability and generalization bounds for SGD with even non-differentiable loss functions. Finally, we study learning problems with (strongly) convex objectives but non-convex loss functions.
On Performance Estimation in Automatic Algorithm Configuration
Nov 19, 2019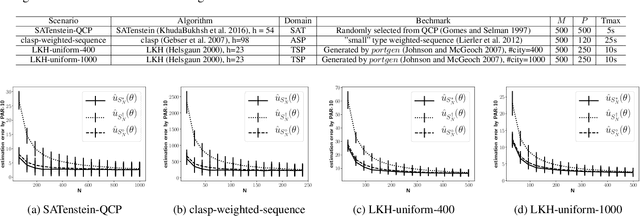


Over the last decade, research on automated parameter tuning, often referred to as automatic algorithm configuration (AAC), has made significant progress. Although the usefulness of such tools has been widely recognized in real world applications, the theoretical foundations of AAC are still very weak. This paper addresses this gap by studying the performance estimation problem in AAC. More specifically, this paper first proves the universal best performance estimator in a practical setting, and then establishes theoretical bounds on the estimation error, i.e., the difference between the training performance and the true performance for a parameter configuration, considering finite and infinite configuration spaces respectively. These findings were verified in extensive experiments conducted on four algorithm configuration scenarios involving different problem domains. Moreover, insights for enhancing existing AAC methods are also identified.
Stochastic Proximal AUC Maximization
Jun 14, 2019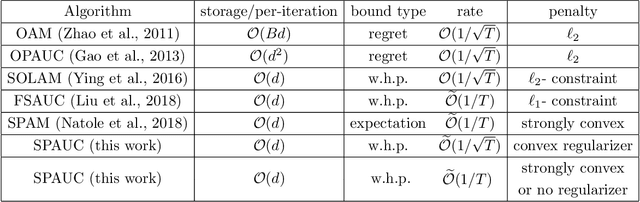
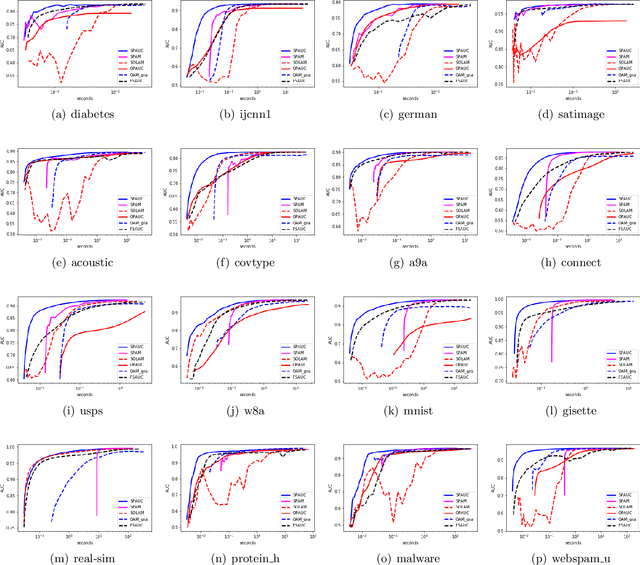
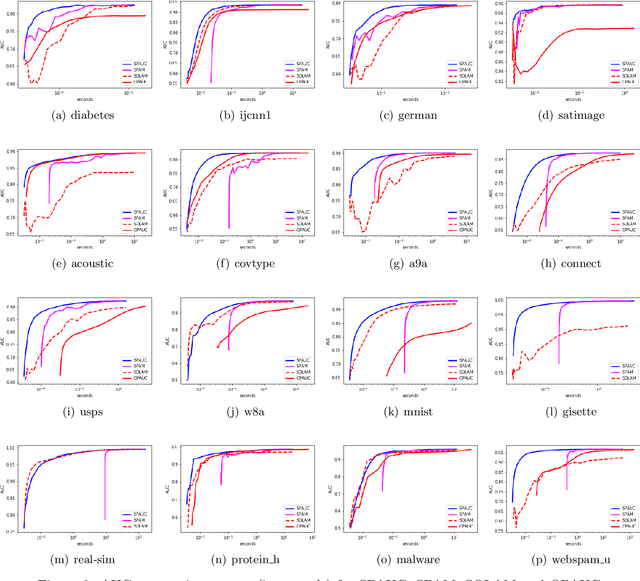
In this paper we consider the problem of maximizing the Area under the ROC curve (AUC) which is a widely used performance metric in imbalanced classification and anomaly detection. Due to the pairwise nonlinearity of the objective function, classical SGD algorithms do not apply to the task of AUC maximization. We propose a novel stochastic proximal algorithm for AUC maximization which is scalable to large scale streaming data. Our algorithm can accommodate general penalty terms and is easy to implement with favorable $O(d)$ space and per-iteration time complexities. We establish a high-probability convergence rate $O(1/\sqrt{T})$ for the general convex setting, and improve it to a fast convergence rate $O(1/T)$ for the cases of strongly convex regularizers and no regularization term (without strong convexity). Our proof does not need the uniform boundedness assumption on the loss function or the iterates which is more fidelity to the practice. Finally, we perform extensive experiments over various benchmark data sets from real-world application domains which show the superior performance of our algorithm over the existing AUC maximization algorithms.
Improved Generalisation Bounds for Deep Learning Through $L^\infty$ Covering Numbers
May 29, 2019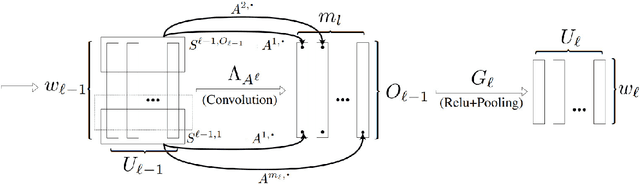
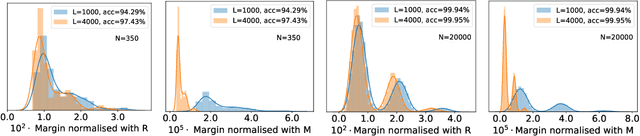
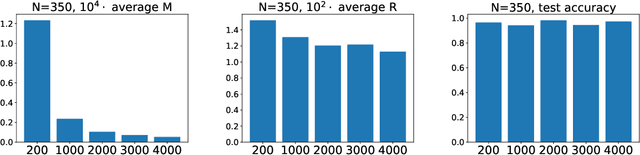
Using proof techniques involving $L^\infty$ covering numbers, we show generalisation error bounds for deep learning with two main improvements over the state of the art. First, our bounds have no explicit dependence on the number of classes except for logarithmic factors. This holds even when formulating the bounds in terms of the $L^2$-norm of the weight matrices, while previous bounds exhibit at least a square-root dependence on the number of classes in this case. Second, we adapt the Rademacher analysis of DNNs to incorporate weight sharing---a task of fundamental theoretical importance which was previously attempted only under very restrictive assumptions. In our results, each convolutional filter contributes only once to the bound, regardless of how many times it is applied. Finally we provide a few further technical improvements, including improving the width dependence from before to after pooling. We also examine our bound's behaviour on artificial data.