 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-Attention GAN for Large-Pose Face Frontalization
Feb 17, 2020
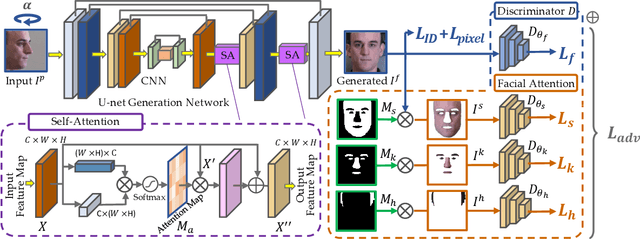


Face frontalization provides an effective and efficient way for face data augmentation and further improves the face recognition performance in extreme pose scenario. Despite recent advances in deep learning-based face synthesis approaches, this problem is still challenging due to significant pose and illumination discrepancy. In this paper, we present a novel Dual-Attention Generative Adversarial Network (DA-GAN) for photo-realistic face frontalization by capturing both contextual dependencies and local consistency during GAN training. Specifically, a self-attention-based generator is introduced to integrate local features with their long-range dependencies yielding better feature representations, and hence generate faces that preserve identities better, especially for larger pose angles. Moreover, a novel face-attention-based discriminator is applied to emphasize local features of face regions, and hence reinforce the realism of synthetic frontal faces. Guided by semantic segmentation, four independent discriminators are used to distinguish between different aspects of a face (\ie skin, keypoints, hairline, and frontalized face). By introducing these two complementary attention mechanisms in generator and discriminator separately, we can learn a richer feature representation and generate identity preserving inference of frontal views with much finer details (i.e., more accurate facial appearance and textures) comparing to the state-of-the-art. Quantitative and qualitative experimental results demonstrate the effectiveness and efficiency of our DA-GAN approach.
Face Recognition: Too Bias, or Not Too Bias?
Feb 16, 2020
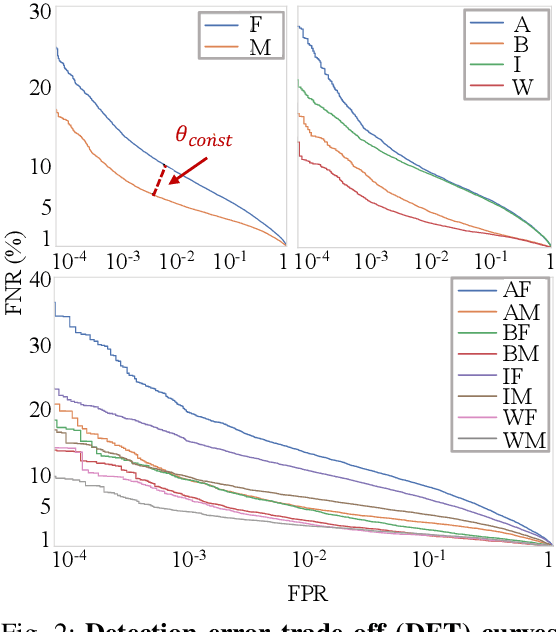
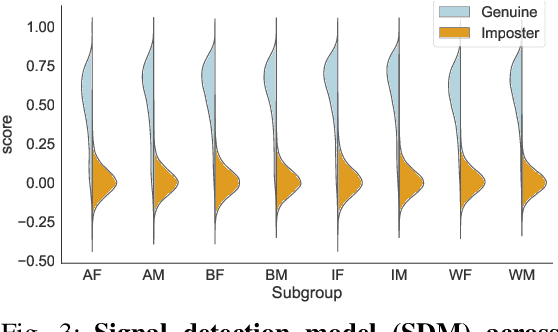
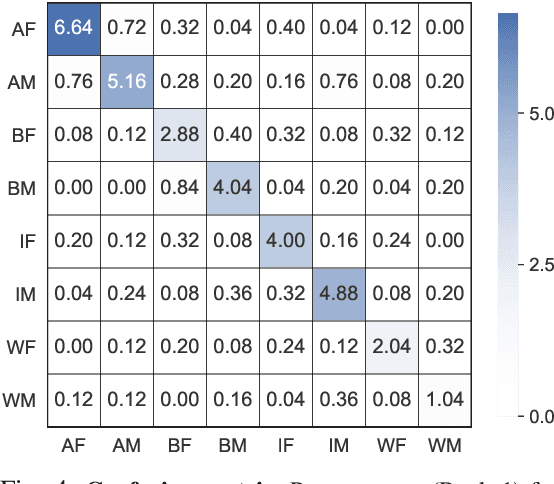
We reveal critical insights into problems of bias in state-of-the-art facial recognition (FR) systems using a novel Balanced Faces In the Wild (BFW) dataset: data balanced for gender and ethnic groups. We show variations in the optimal scoring threshold for face-pairs across different subgroups. Thus, the conventional approach of learning a global threshold for all pairs resulting in performance gaps among subgroups. By learning subgroup-specific thresholds, we not only mitigate problems in performance gaps but also show a notable boost in the overall performance. Furthermore, we do a human evaluation to measure the bias in humans, which supports the hypothesis that such a bias exists in human perception. For the BFW database, source code, and more, visit github.com/visionjo/facerec-bias-bfw.
Opposite Structure Learning for Semi-supervised Domain Adaptation
Feb 06, 2020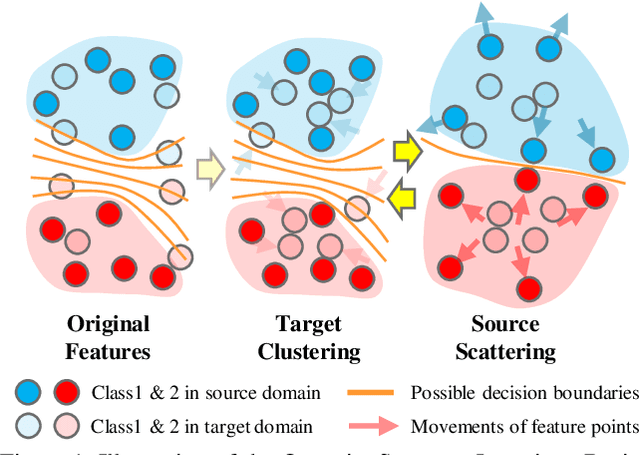
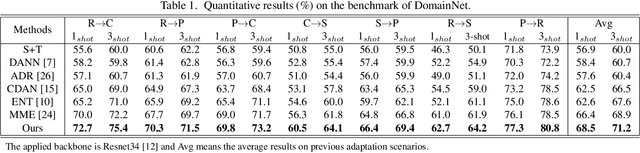
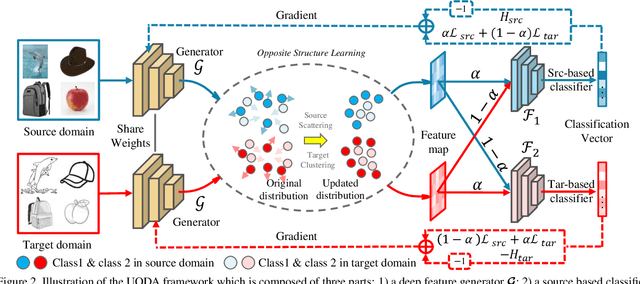
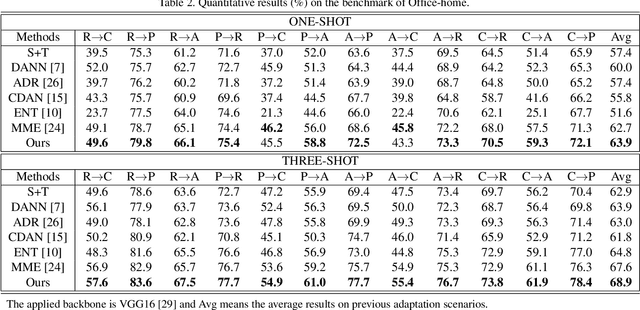
Current adversarial adaptation methods attempt to align the cross-domain features whereas two challenges remain unsolved: 1) conditional distribution mismatch between different domains and 2) the bias of decision boundary towards the source domain. To solve these challenges, we propose a novel framework for semi-supervised domain adaptation by unifying the learning of opposite structures (UODA). UODA consists of a generator and two classifiers (i.e., the source-based and the target-based classifiers respectively) which are trained with opposite forms of losses for a unified object. The target-based classifier attempts to cluster the target features to improve intra-class density and enlarge inter-class divergence. Meanwhile, the source-based classifier is designed to scatter the source features to enhance the smoothness of decision boundary. Through the alternation of source-feature expansion and target-feature clustering procedures, the target features are well-enclosed within the dilated boundary of the corresponding source features. This strategy effectively makes the cross-domain features precisely aligned. To overcome the model collapse through training, we progressively update the measurement of distance and the feature representation on both domains via an adversarial training paradigm. Extensive experiments on the benchmarks of DomainNet and Office-home datasets demonstrate the effectiveness of our approach over the state-of-the-art method.
Texture Hallucination for Large-Scale Painting Super-Resolution
Dec 01, 2019
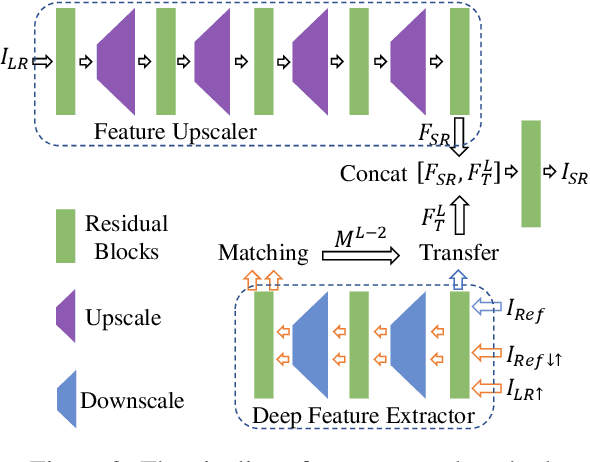
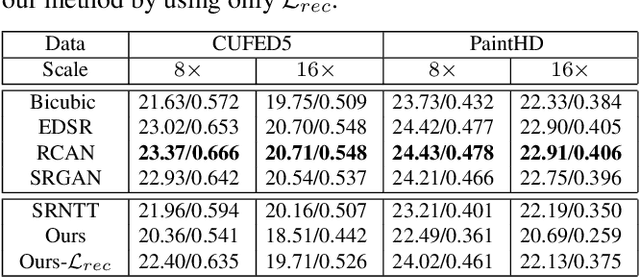
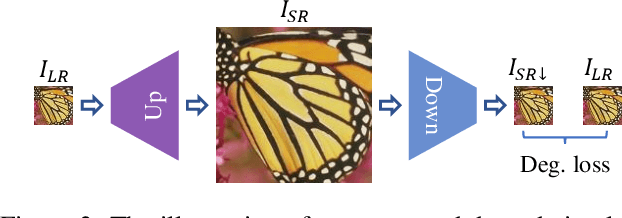
We aim to super-resolve digital paintings, synthesizing realistic details from high-resolution reference painting materials for very large scaling factors (e.g., 8x, 16x). However, previous single image super-resolution (SISR) methods would either lose textural details or introduce unpleasing artifacts. On the other hand, reference-based SR (Ref-SR) methods can transfer textures to some extent, but is still impractical to handle very large scales and keep fidelity with original input. To solve these problems, we propose an efficient high-resolution hallucination network for very large scaling factors with efficient network structure and feature transferring. To transfer more detailed textures, we design a wavelet texture loss, which helps to enhance more high-frequency components. At the same time, to reduce the smoothing effect brought by the image reconstruction loss, we further relax the reconstruction constraint with a degradation loss which ensures the consistency between downscaled super-resolution results and low-resolution inputs. We also collected a high-resolution (e.g., 4K resolution) painting dataset PaintHD by considering both physical size and image resolution. We demonstrate the effectiveness of our method with extensive experiments on PaintHD by comparing with SISR and Ref-SR state-of-the-art methods.
Lifelong Spectral Clustering
Nov 29, 2019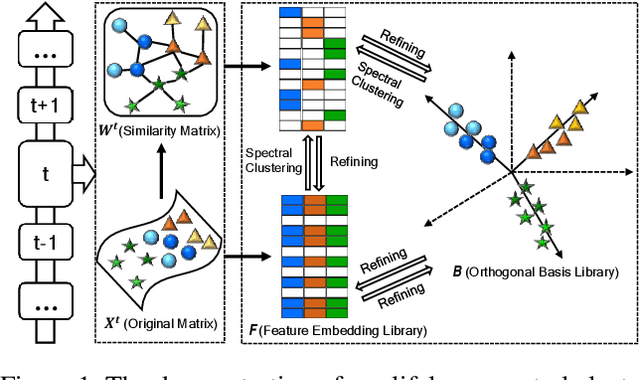
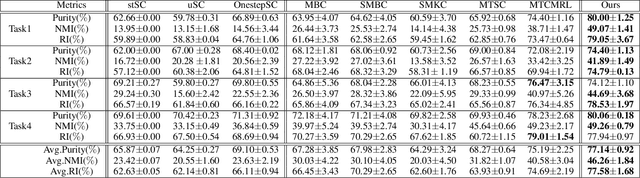
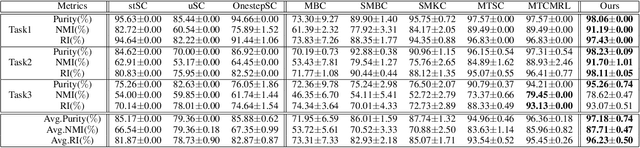
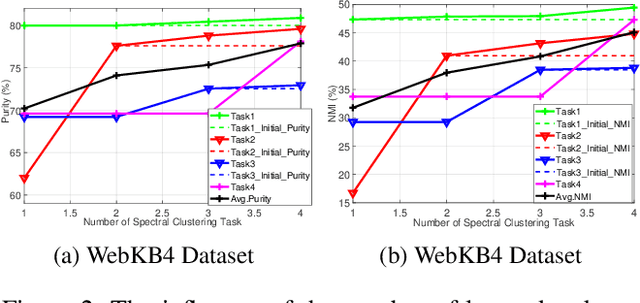
In the past decades, spectral clustering (SC) has become one of the most effective clustering algorithms. However, most previous studies focus on spectral clustering tasks with a fixed task set, which cannot incorporate with a new spectral clustering task without accessing to previously learned tasks. In this paper, we aim to explore the problem of spectral clustering in a lifelong machine learning framework, i.e., Lifelong Spectral Clustering (L2SC). Its goal is to efficiently learn a model for a new spectral clustering task by selectively transferring previously accumulated experience from knowledge library. Specifically, the knowledge library of L2SC contains two components: 1) orthogonal basis library: capturing latent cluster centers among the clusters in each pair of tasks; 2) feature embedding library: embedding the feature manifold information shared among multiple related tasks. As a new spectral clustering task arrives, L2SC firstly transfers knowledge from both basis library and feature library to obtain encoding matrix, and further redefines the library base over time to maximize performance across all the clustering tasks. Meanwhile, a general online update formulation is derived to alternatively update the basis library and feature library. Finally, the empirical experiments on several real-world benchmark datasets demonstrate that our L2SC model can effectively improve the clustering performance when comparing with other state-of-the-art spectral clustering algorithms.
* 9 pages,7 figures
Multi-View Time Series Classification via Global-Local Correlative Channel-Aware Fusion Mechanism
Nov 24, 2019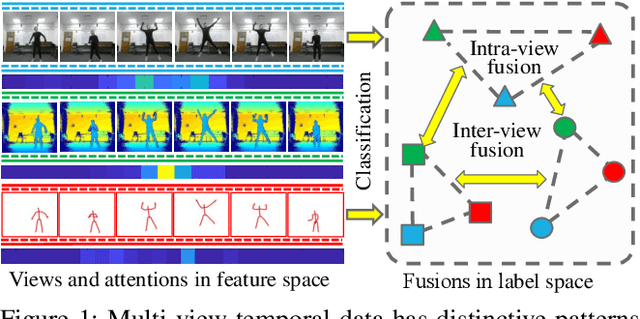
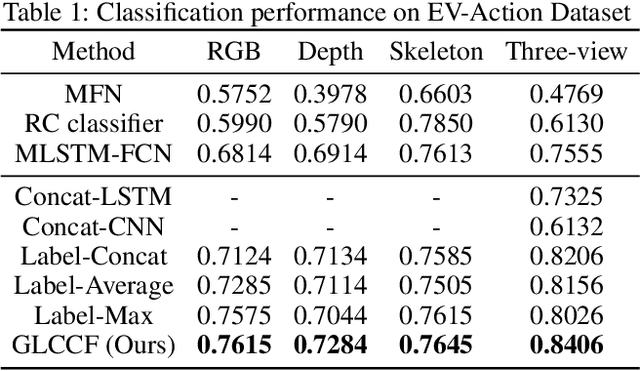
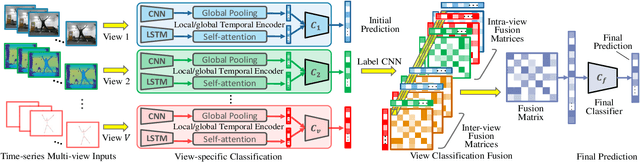
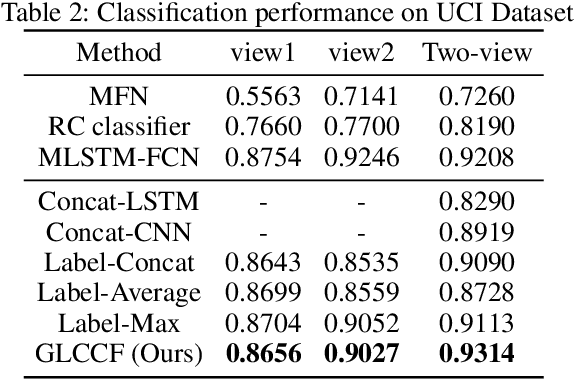
Multi-view time series classification aims to fuse the distinctive temporal information from different views to further enhance the classification performance. Existing methods mainly focus on fusing multi-view features at an early stage (e.g., learning a common representation shared by multiple views). However, these early fusion methods may not fully exploit the view-specific distinctive patterns in high-dimension time series data. Moreover, the intra-view and inter-view label correlations, which are critical for multi-view classification, are usually ignored in previous works. In this paper, we propose a Global-Local Correlative Channel-AwareFusion (GLCCF) model to address the aforementioned issues. Particularly, our model extracts global and local temporal patterns by a two-stream structure encoder, captures the intra-view and inter-view label correlations by constructing a graph based correlation matrix, and extracts the cross-view global patterns via a learnable channel-aware late fusion mechanism, which could be effectively implemented with a convolutional neural network. Extensive experiments on two real-world datasets demonstrate the superiority of our approach over the state-of-the-art methods. An ablation study is furtherprovided to show the effectiveness of each model component.
Joint Super-Resolution and Alignment of Tiny Faces
Nov 19, 2019

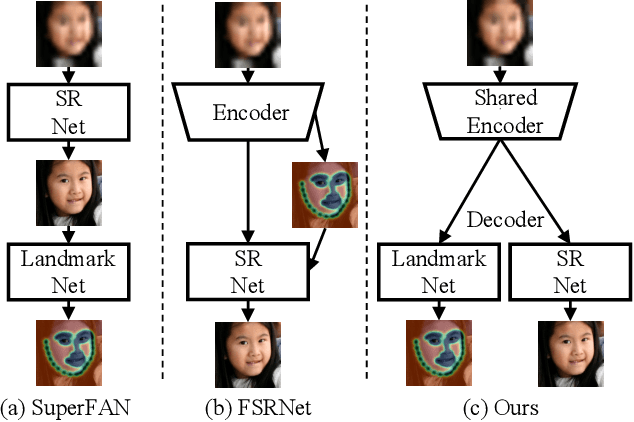
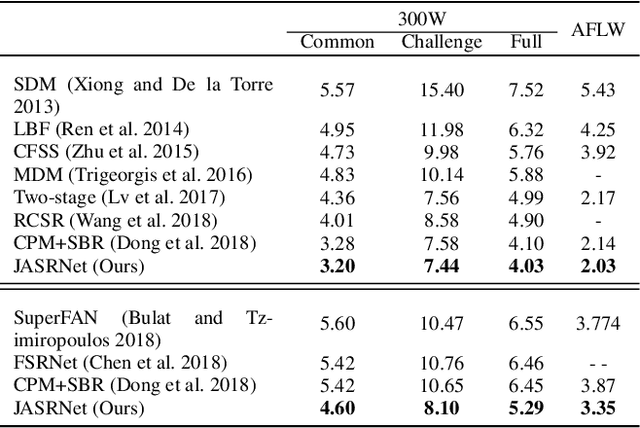
Super-resolution (SR) and landmark localization of tiny faces are highly correlated tasks. On the one hand, landmark localization could obtain higher accuracy with faces of high-resolution (HR). On the other hand, face SR would benefit from prior knowledge of facial attributes such as landmarks. Thus, we propose a joint alignment and SR network to simultaneously detect facial landmarks and super-resolve tiny faces. More specifically, a shared deep encoder is applied to extract features for both tasks by leveraging complementary information. To exploit the representative power of the hierarchical encoder, intermediate layers of a shared feature extraction module are fused to form efficient feature representations. The fused features are then fed to task-specific modules to detect landmarks and super-resolve face images in parallel. Extensive experiments demonstrate that the proposed model significantly outperforms the state-of-the-art in both landmark localization and SR of faces. We show a large improvement for landmark localization of tiny faces (i.e., 16*16). Furthermore, the proposed framework yields comparable results for landmark localization on low-resolution (LR) faces (i.e., 64*64) to existing methods on HR (i.e., 256*256). As for SR, the proposed method recovers sharper edges and more details from LR face images than other state-of-the-art methods, which we demonstrate qualitatively and quantitatively.
What Will Your Child Look Like? DNA-Net: Age and Gender Aware Kin Face Synthesizer
Nov 16, 2019
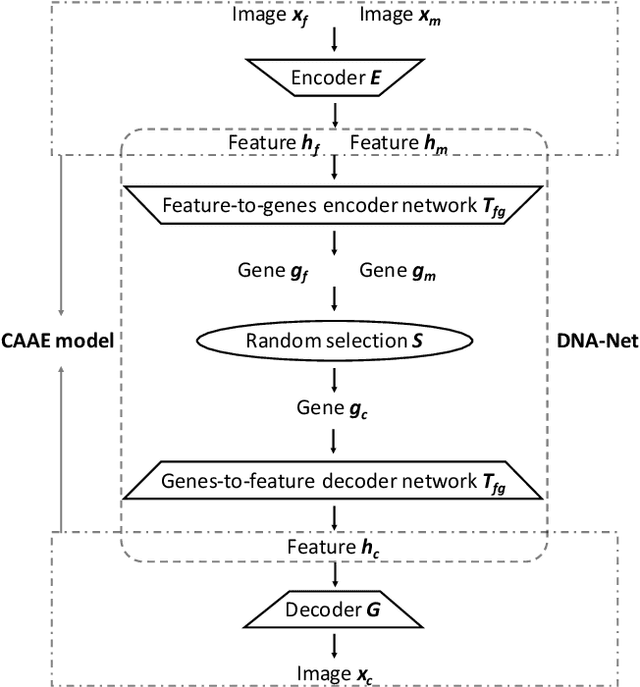
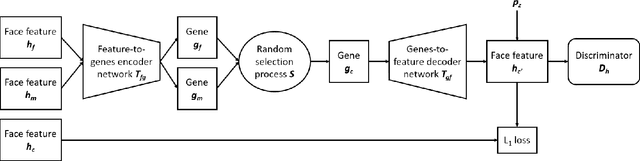

Visual kinship recognition aims to identify blood relatives from facial images. Its practical application-- like in law-enforcement, video surveillance, automatic family album management, and more-- has motivated many researchers to put forth effort on the topic as of recent. In this paper, we focus on a new view of visual kinship technology: kin-based face generation. Specifically, we propose a two-stage kin-face generation model to predict the appearance of a child given a pair of parents. The first stage includes a deep generative adversarial autoencoder conditioned on ages and genders to map between facial appearance and high-level features. The second stage is our proposed DNA-Net, which serves as a transformation between the deep and genetic features based on a random selection process to fuse genes of a parent pair to form the genes of a child. We demonstrate the effectiveness of the proposed method quantitatively and qualitatively: quantitatively, pre-trained models and human subjects perform kinship verification on the generated images of children; qualitatively, we show photo-realistic face images of children that closely resemble the given pair of parents. In the end, experiments validate that the proposed model synthesizes convincing kin-faces using both subjective and objective standards.
LPRNet: Lightweight Deep Network by Low-rank Pointwise Residual Convolution
Nov 14, 2019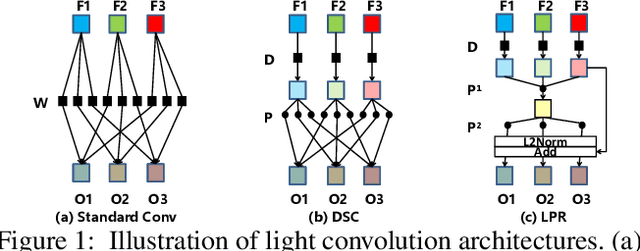

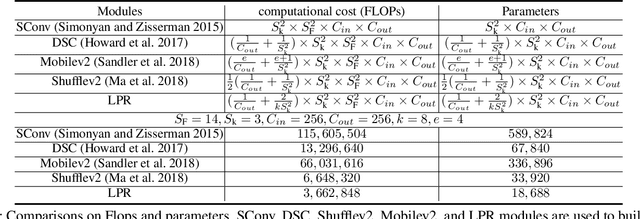
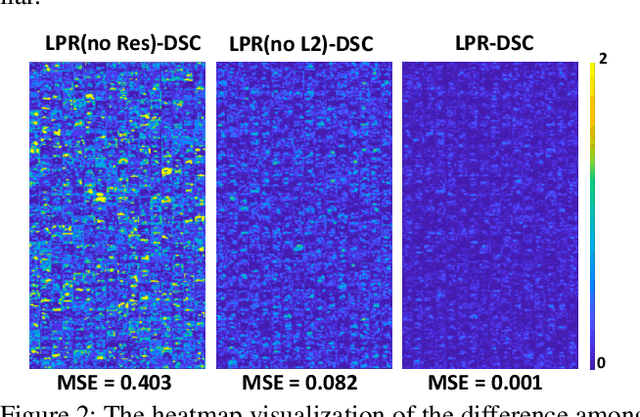
Deep learning has become popular in recent years primarily due to the powerful computing device such as GPUs. However, deploying these deep models to end-user devices, smart phones, or embedded systems with limited resources is challenging. To reduce the computation and memory costs, we propose a novel lightweight deep learning module by low-rank pointwise residual (LPR) convolution, called LPRNet. Essentially, LPR aims at using low-rank approximation in pointwise convolution to further reduce the module size, while keeping depthwise convolutions as the residual module to rectify the LPR module. This is critical when the low-rankness undermines the convolution process. We embody our design by replacing modules of identical input-output dimension in MobileNet and ShuffleNetv2. Experiments on visual recognition tasks including image classification and face alignment on popular benchmarks show that our LPRNet achieves competitive performance but with significant reduction of Flops and memory cost compared to the state-of-the-art deep models focusing on model compression.
PointDAN: A Multi-Scale 3D Domain Adaption Network for Point Cloud Representation
Nov 07, 2019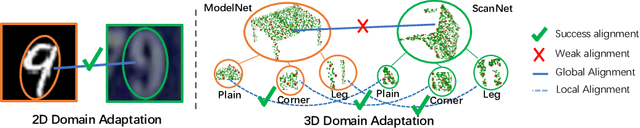
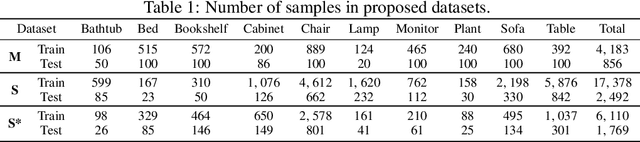
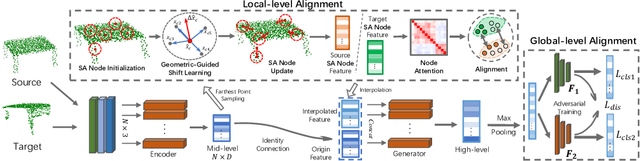
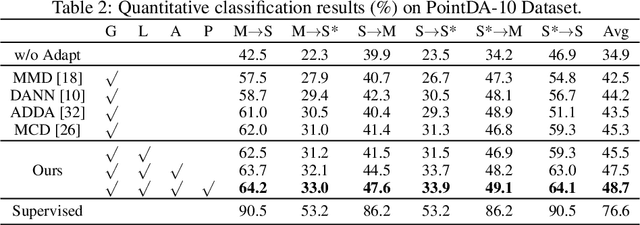
Domain Adaptation (DA) approaches achieved significant improvements in a wide range of machine learning and computer vision tasks (i.e., classification, detection, and segmentation). However, as far as we are aware, there are few methods yet to achieve domain adaptation directly on 3D point cloud data. The unique challenge of point cloud data lies in its abundant spatial geometric information, and the semantics of the whole object is contributed by including regional geometric structures. Specifically, most general-purpose DA methods that struggle for global feature alignment and ignore local geometric information are not suitable for 3D domain alignment. In this paper, we propose a novel 3D Domain Adaptation Network for point cloud data (PointDAN). PointDAN jointly aligns the global and local features in multi-level. For local alignment, we propose Self-Adaptive (SA) node module with an adjusted receptive field to model the discriminative local structures for aligning domains. To represent hierarchically scaled features, node-attention module is further introduced to weight the relationship of SA nodes across objects and domains. For global alignment, an adversarial-training strategy is employed to learn and align global features across domains. Since there is no common evaluation benchmark for 3D point cloud DA scenario, we build a general benchmark (i.e., PointDA-10) extracted from three popular 3D object/scene datasets (i.e., ModelNet, ShapeNet and ScanNet) for cross-domain 3D objects classification fashion. Extensive experiments on PointDA-10 illustrate the superiority of our model over the state-of-the-art general-purpose DA methods.