 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSNRi Target Training for Joint Speech Enhancement and Recognition
Nov 01, 2021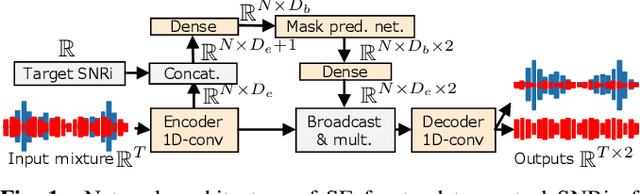

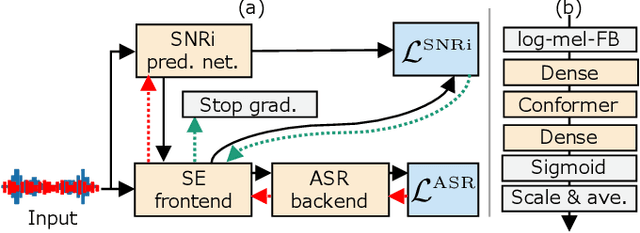
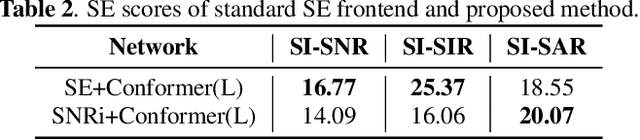
This study aims to improve the performance of automatic speech recognition (ASR) under noisy conditions. The use of a speech enhancement (SE) frontend has been widely studied for noise robust ASR. However, most single-channel SE models introduce processing artifacts in the enhanced speech resulting in degraded ASR performance. To overcome this problem, we propose Signal-to-Noise Ratio improvement (SNRi) target training; the SE frontend automatically controls its noise reduction level to avoid degrading the ASR performance due to artifacts. The SE frontend uses an auxiliary scalar input which represents the target SNRi of the output signal. The target SNRi value is estimated by the SNRi prediction network, which is trained to minimize the ASR loss. Experiments using 55,027 hours of noisy speech training data show that SNRi target training enables control of the SNRi of the output signal, and the joint training reduces word error rate by 12% compared to a state-of-the-art Conformer-based ASR model.
DF-Conformer: Integrated architecture of Conv-TasNet and Conformer using linear complexity self-attention for speech enhancement
Jun 30, 2021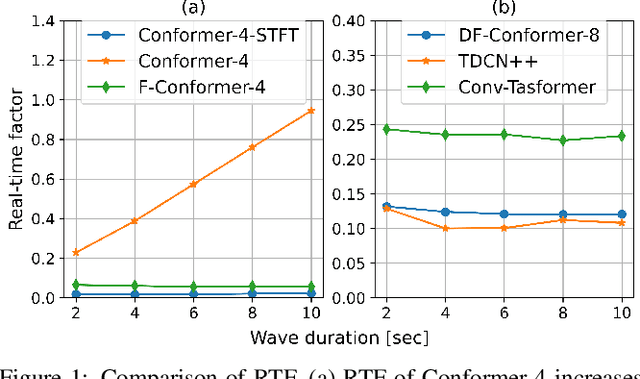
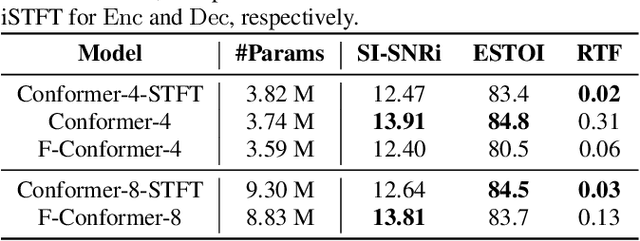
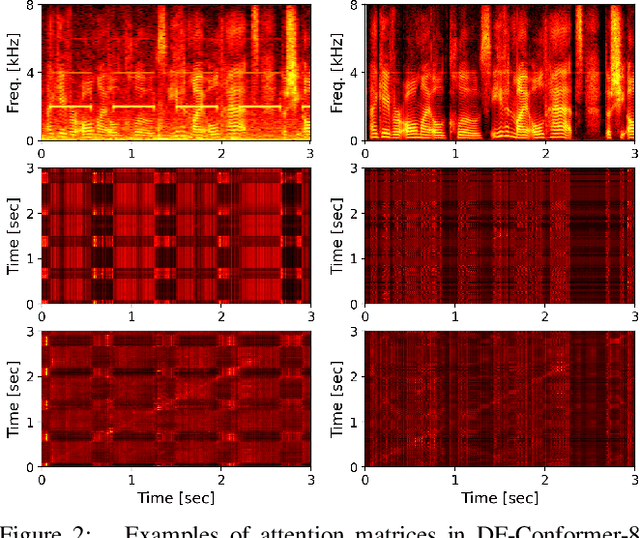
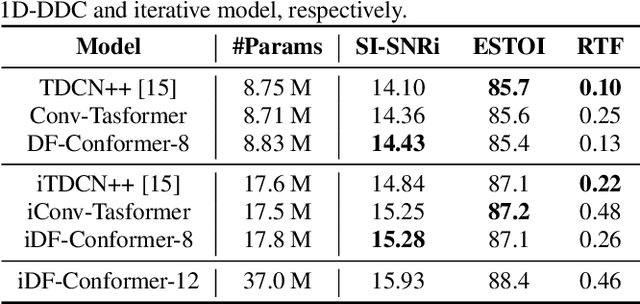
Single-channel speech enhancement (SE) is an important task in speech processing. A widely used framework combines an analysis/synthesis filterbank with a mask prediction network, such as the Conv-TasNet architecture. In such systems, the denoising performance and computational efficiency are mainly affected by the structure of the mask prediction network. In this study, we aim to improve the sequential modeling ability of Conv-TasNet architectures by integrating Conformer layers into a new mask prediction network. To make the model computationally feasible, we extend the Conformer using linear complexity attention and stacked 1-D dilated depthwise convolution layers. We trained the model on 3,396 hours of noisy speech data, and show that (i) the use of linear complexity attention avoids high computational complexity, and (ii) our model achieves higher scale-invariant signal-to-noise ratio than the improved time-dilated convolution network (TDCN++), an extended version of Conv-TasNet.
Description and Discussion on DCASE 2021 Challenge Task 2: Unsupervised Anomalous Sound Detection for Machine Condition Monitoring under Domain Shifted Conditions
Jun 08, 2021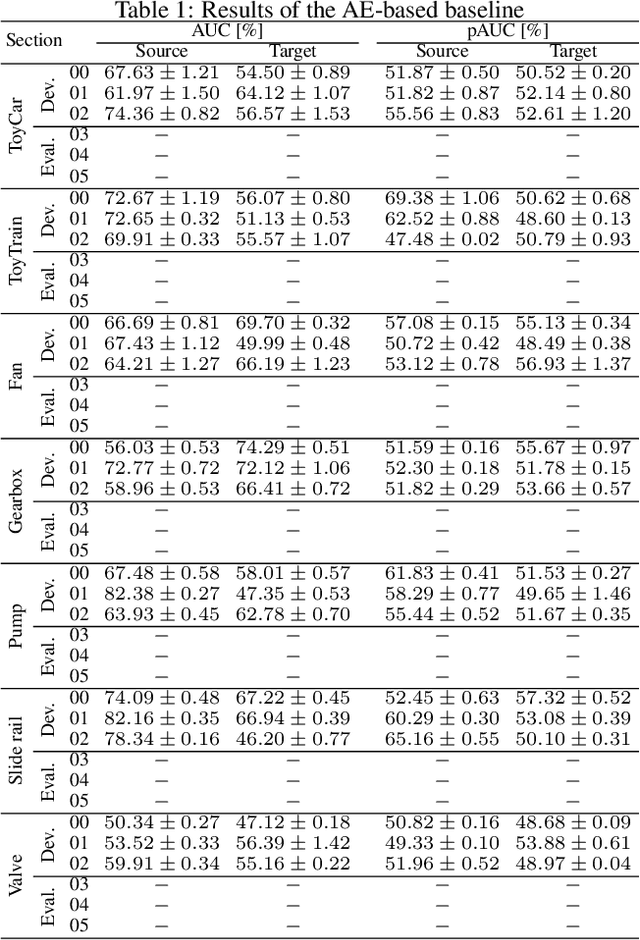
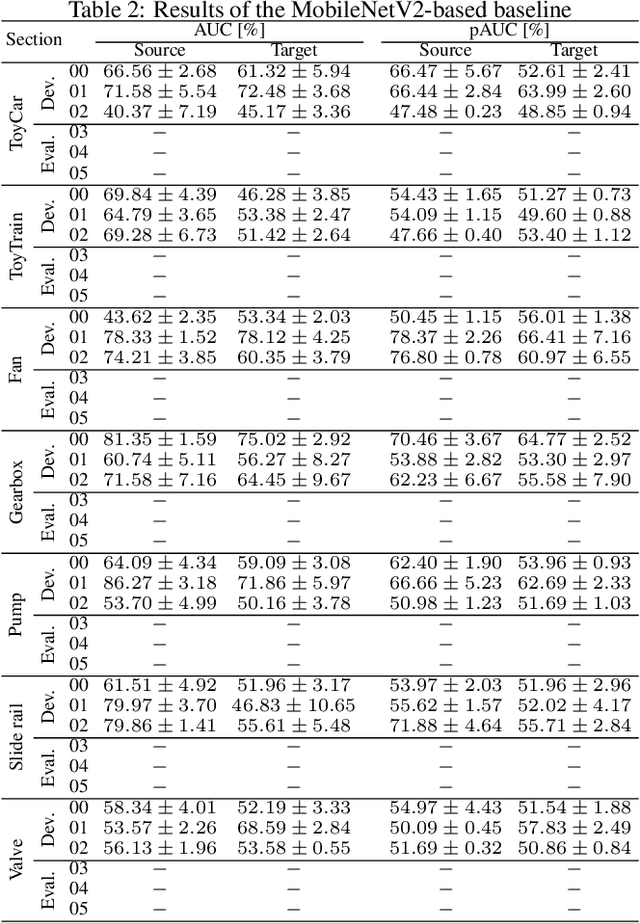
We present the task description and discussion on the results of the DCASE 2021 Challenge Task 2. Last year, we organized unsupervised anomalous sound detection (ASD) task; identifying whether the given sound is normal or anomalous without anomalous training data. In this year, we organize an advanced unsupervised ASD task under domain-shift conditions which focuses on the inevitable problem for the practical use of ASD systems. The main challenge of this task is to detect unknown anomalous sounds where the acoustic characteristics of the training and testing samples are different, i.e. domain-shifted. This problem is frequently occurs due to changes in seasons, manufactured products, and/or environmental noise. After the challenge submission deadline, we will add challenge results and analysis of the submissions.
Sampling-Frequency-Independent Audio Source Separation Using Convolution Layer Based on Impulse Invariant Method
May 10, 2021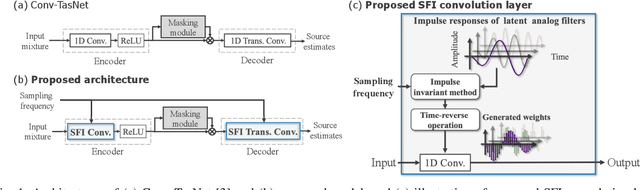

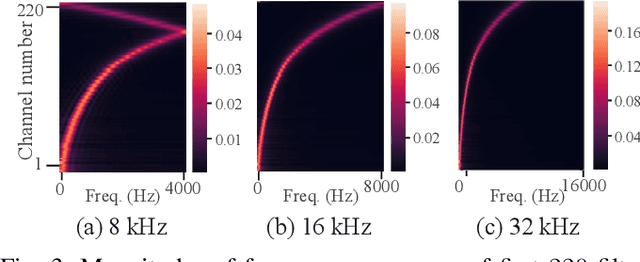
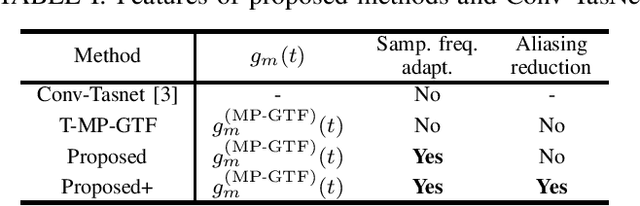
Audio source separation is often used as preprocessing of various applications, and one of its ultimate goals is to construct a single versatile model capable of dealing with the varieties of audio signals. Since sampling frequency, one of the audio signal varieties, is usually application specific, the preceding audio source separation model should be able to deal with audio signals of all sampling frequencies specified in the target applications. However, conventional models based on deep neural networks (DNNs) are trained only at the sampling frequency specified by the training data, and there are no guarantees that they work with unseen sampling frequencies. In this paper, we propose a convolution layer capable of handling arbitrary sampling frequencies by a single DNN. Through music source separation experiments, we show that the introduction of the proposed layer enables a conventional audio source separation model to consistently work with even unseen sampling frequencies.
Noisy-target Training: A Training Strategy for DNN-based Speech Enhancement without Clean Speech
Jan 21, 2021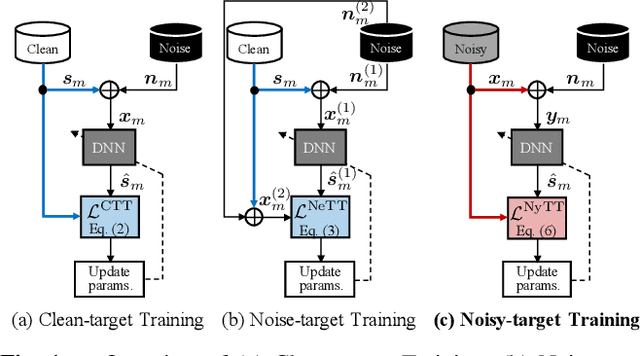

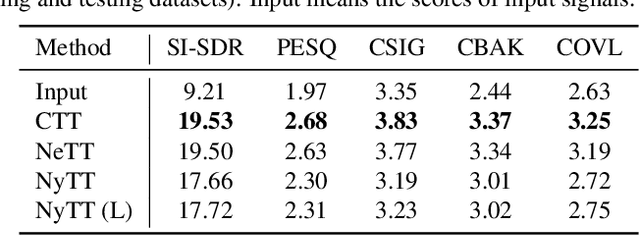
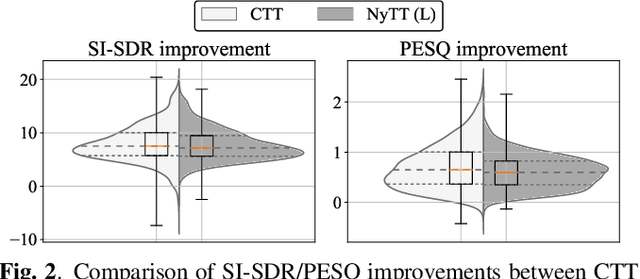
Deep neural network (DNN)-based speech enhancement ordinarily requires clean speech signals as the training target. However, collecting clean signals is very costly because they must be recorded in a studio. This requirement currently restricts the amount of training data for speech enhancement less than 1/1000 of that of speech recognition which does not need clean signals. Increasing the amount of training data is important for improving the performance, and hence the requirement of clean signals should be relaxed. In this paper, we propose a training strategy that does not require clean signals. The proposed method only utilizes noisy signals for training, which enables us to use a variety of speech signals in the wild. Our experimental results showed that the proposed method can achieve the performance similar to that of a DNN trained with clean signals.
Audio Captioning using Pre-Trained Large-Scale Language Model Guided by Audio-based Similar Caption Retrieval
Dec 14, 2020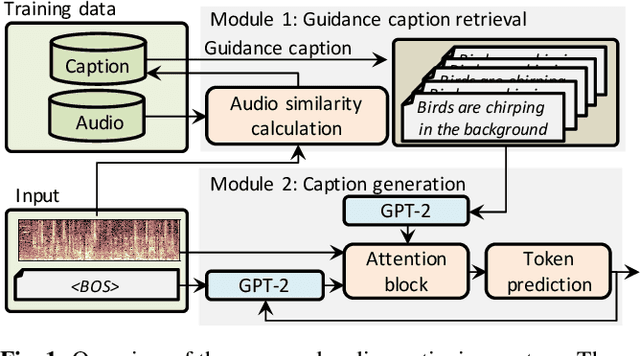
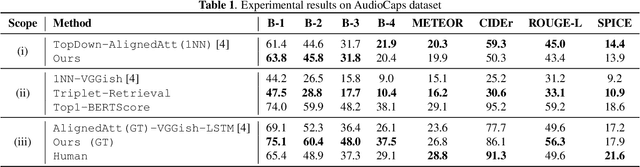
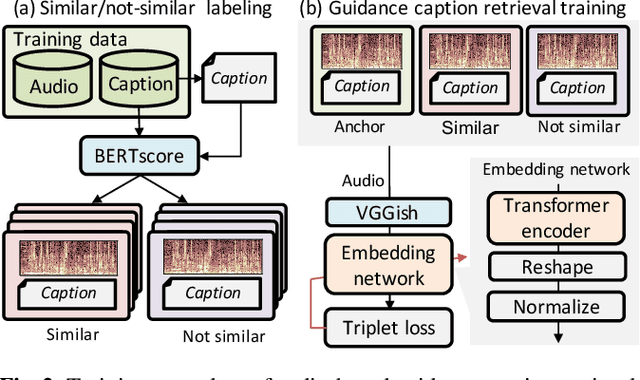
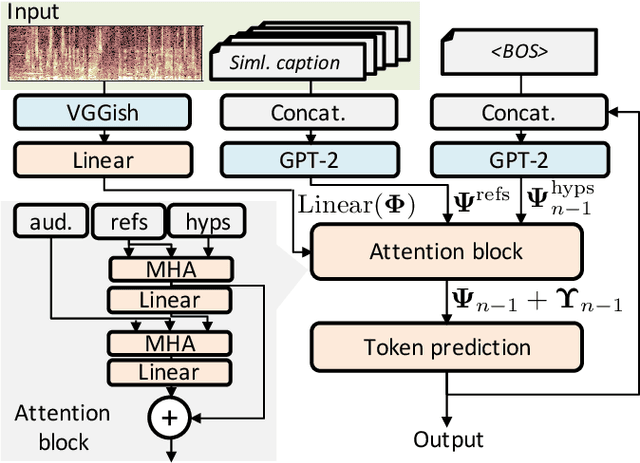
The goal of audio captioning is to translate input audio into its description using natural language. One of the problems in audio captioning is the lack of training data due to the difficulty in collecting audio-caption pairs by crawling the web. In this study, to overcome this problem, we propose to use a pre-trained large-scale language model. Since an audio input cannot be directly inputted into such a language model, we utilize guidance captions retrieved from a training dataset based on similarities that may exist in different audio. Then, the caption of the audio input is generated by using a pre-trained language model while referring to the guidance captions. Experimental results show that (i) the proposed method has succeeded to use a pre-trained language model for audio captioning, and (ii) the oracle performance of the pre-trained model-based caption generator was clearly better than that of the conventional method trained from scratch.
Effects of Word-frequency based Pre- and Post- Processings for Audio Captioning
Sep 24, 2020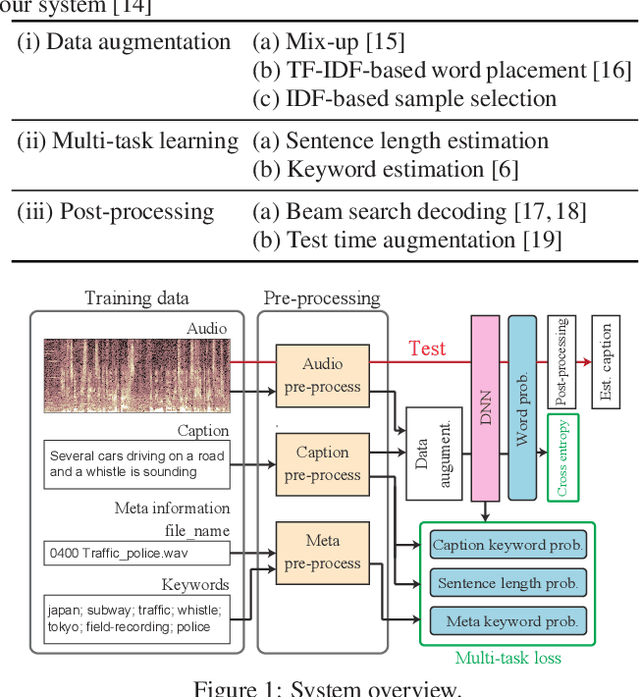
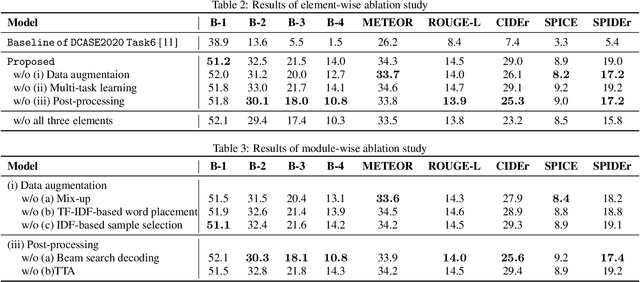
The system we used for Task 6 (Automated Audio Captioning)of the Detection and Classification of Acoustic Scenes and Events(DCASE) 2020 Challenge combines three elements, namely, dataaugmentation, multi-task learning, and post-processing, for audiocaptioning. The system received the highest evaluation scores, butwhich of the individual elements most fully contributed to its perfor-mance has not yet been clarified. Here, to asses their contributions,we first conducted an element-wise ablation study on our systemto estimate to what extent each element is effective. We then con-ducted a detailed module-wise ablation study to further clarify thekey processing modules for improving accuracy. The results showthat data augmentation and post-processing significantly improvethe score in our system. In particular, mix-up data augmentationand beam search in post-processing improve SPIDEr by 0.8 and 1.6points, respectively.
The NTT DCASE2020 Challenge Task 6 system: Automated Audio Captioning with Keywords and Sentence Length Estimation
Jul 01, 2020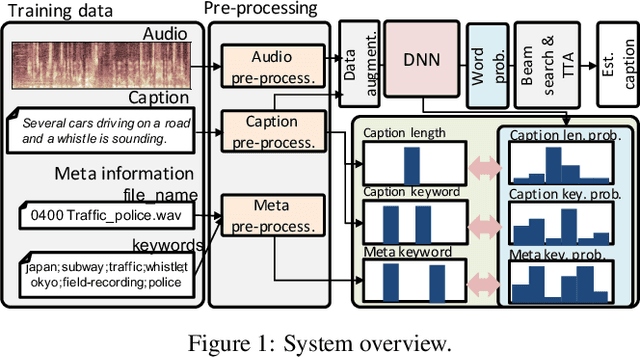
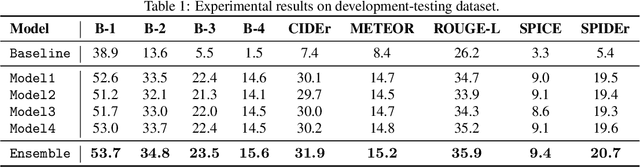
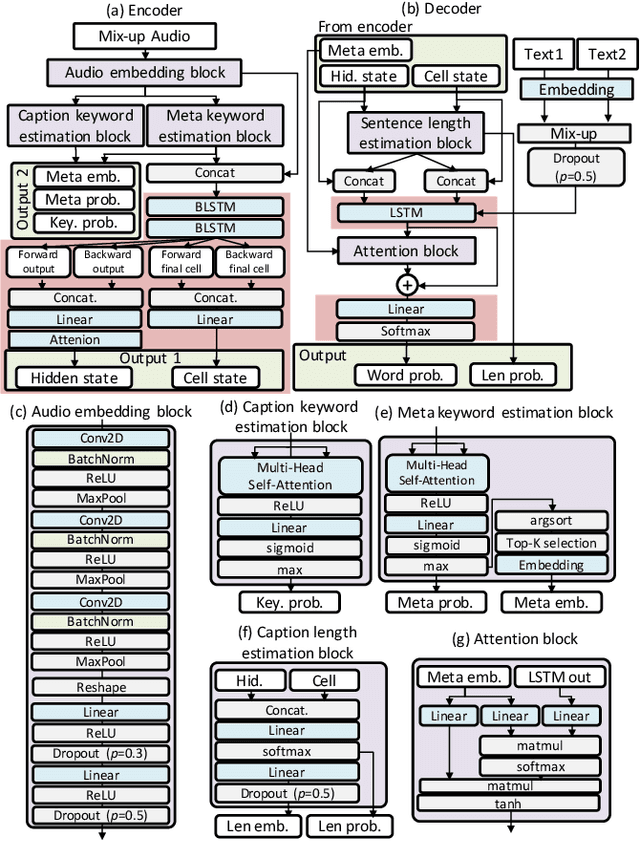
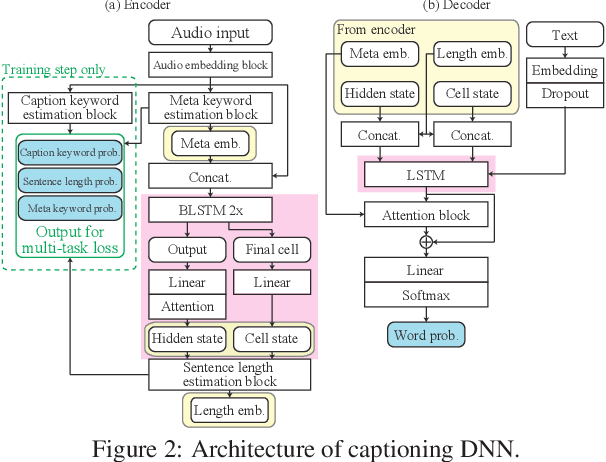
This technical report describes the system participating to the Detection and Classification of Acoustic Scenes and Events (DCASE) 2020 Challenge, Task 6: automated audio captioning. Our submission focuses on solving two indeterminacy problems in automated audio captioning: word selection indeterminacy and sentence length indeterminacy. We simultaneously solve the main caption generation and sub indeterminacy problems by estimating keywords and sentence length through multi-task learning. We tested a simplified model of our submission using the development-testing dataset. Our model achieved 20.7 SPIDEr score where that of the baseline system was 5.4.
A Transformer-based Audio Captioning Model with Keyword Estimation
Jul 01, 2020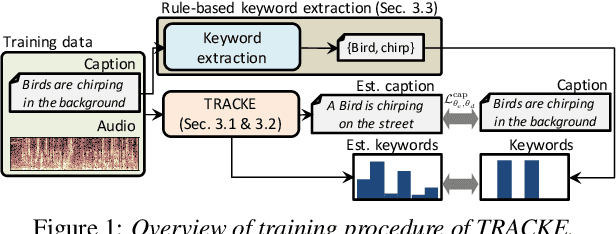
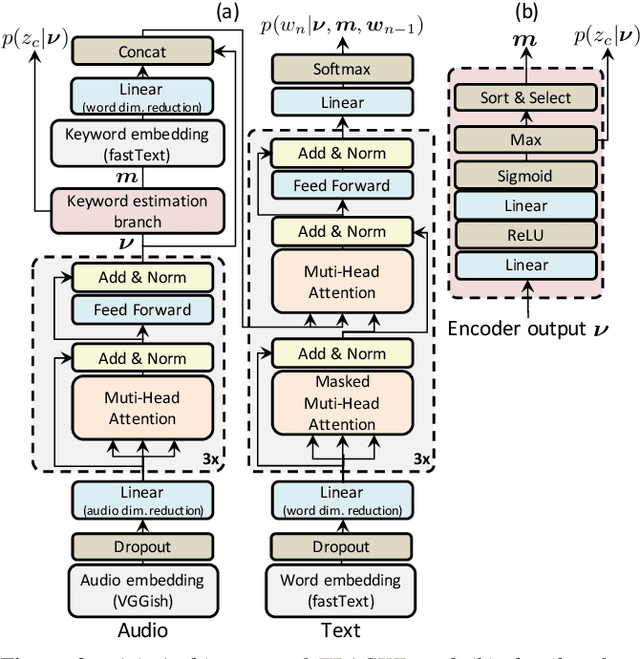
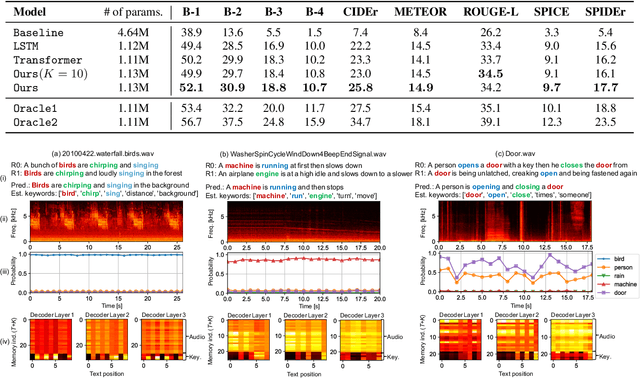
One of the problems with automated audio captioning (AAC) is the indeterminacy in word selection corresponding to the audio event/scene. Since one acoustic event/scene can be described with several words, it results in a combinatorial explosion of possible captions and difficulty in training. To solve this problem, we propose a Transformer-based audio-captioning model with keyword estimation called TRACKE. It simultaneously solves the word-selection indeterminacy problem with the main task of AAC while executing the sub-task of acoustic event detection/acoustic scene classification (i.e., keyword estimation). TRACKE estimates keywords, which comprise a word set corresponding to audio events/scenes in the input audio, and generates the caption while referring to the estimated keywords to reduce word-selection indeterminacy. Experimental results on a public AAC dataset indicate that TRACKE achieved state-of-the-art performance and successfully estimated both the caption and its keywords.
Description and Discussion on DCASE2020 Challenge Task2: Unsupervised Anomalous Sound Detection for Machine Condition Monitoring
Jun 10, 2020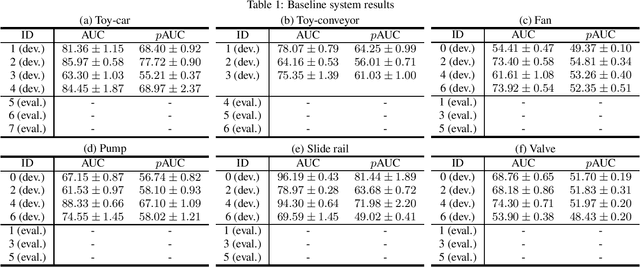
This paper presents the details of the DCASE 2020 Challenge Task 2; Unsupervised Detection of Anomalous Sounds for Machine Condition Monitoring. The goal of anomalous sound detection (ASD) is to identify whether the sound emitted from a target machine is normal or anomalous. The main challenge of this task is to detect unknown anomalous sounds under the condition that only normal sound samples have been provided as training data. We have designed a DCASE challenge task which contributes as a starting point and a benchmark of ASD research; the dataset, evaluation metrics, a simple baseline system, and other detailed rules. After the challenge submission deadline, challenge results and analysis of the submissions will be added.