 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised speech enhancement with spectral kurtosis and double deep priors
Jul 04, 2024This paper proposes an unsupervised DNN-based speech enhancement approach founded on deep priors (DPs). Here, DP signifies that DNNs are more inclined to produce clean speech signals than noises. Conventional methods based on DP typically involve training on a noisy speech signal using a random noise feature as input, stopping training only a clean speech signal is generated. However, such conventional approaches encounter challenges in determining the optimal stop timing, experience performance degradation due to environmental background noise, and suffer a trade-off between distortion of the clean speech signal and noise reduction performance. To address these challenges, we utilize two DNNs: one to generate a clean speech signal and the other to generate noise. The combined output of these networks closely approximates the noisy speech signal, with a loss term based on spectral kurtosis utilized to separate the noisy speech signal into a clean speech signal and noise. The key advantage of this method lies in its ability to circumvent trade-offs and early stopping problems, as the signal is decomposed by enough steps. Through evaluation experiments, we demonstrate that the proposed method outperforms conventional methods in the case of white Gaussian and environmental noise while effectively mitigating early stopping problems.
Noisy-target Training: A Training Strategy for DNN-based Speech Enhancement without Clean Speech
Jan 21, 2021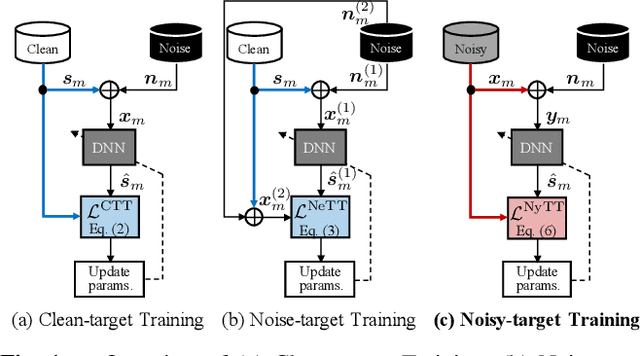

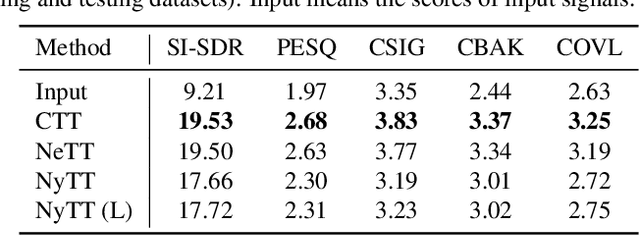
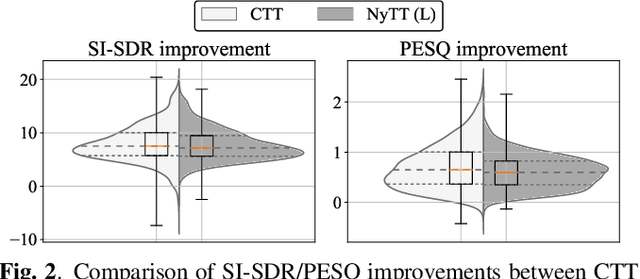
Deep neural network (DNN)-based speech enhancement ordinarily requires clean speech signals as the training target. However, collecting clean signals is very costly because they must be recorded in a studio. This requirement currently restricts the amount of training data for speech enhancement less than 1/1000 of that of speech recognition which does not need clean signals. Increasing the amount of training data is important for improving the performance, and hence the requirement of clean signals should be relaxed. In this paper, we propose a training strategy that does not require clean signals. The proposed method only utilizes noisy signals for training, which enables us to use a variety of speech signals in the wild. Our experimental results showed that the proposed method can achieve the performance similar to that of a DNN trained with clean signals.
Stable Training of DNN for Speech Enhancement based on Perceptually-Motivated Black-Box Cost Function
Feb 14, 2020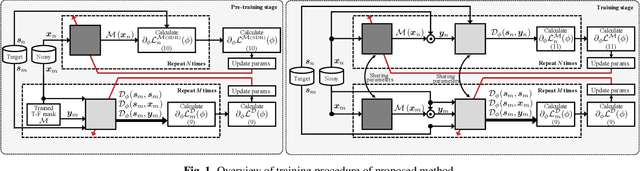
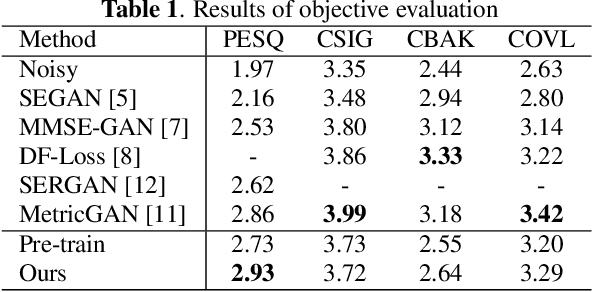
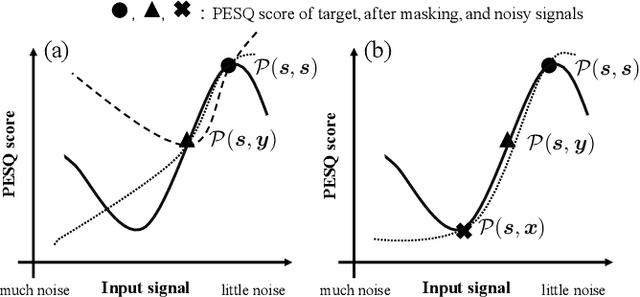
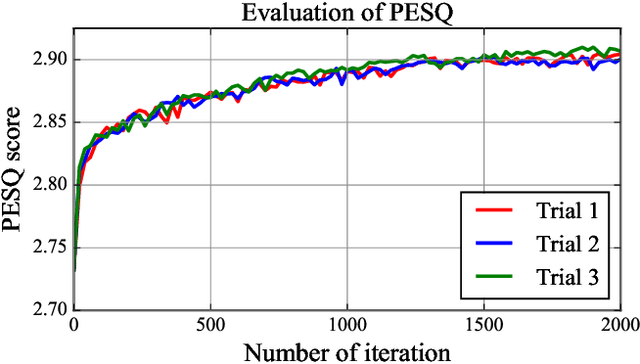
Improving subjective sound quality of enhanced signals is one of the most important missions in speech enhancement. For evaluating the subjective quality, several methods related to perceptually-motivated objective sound quality assessment (OSQA) have been proposed such as PESQ (perceptual evaluation of speech quality). However, direct use of such measures for training deep neural network (DNN) is not allowed in most cases because popular OSQAs are non-differentiable with respect to DNN parameters. Therefore, the previous study has proposed to approximate the score of OSQAs by an auxiliary DNN so that its gradient can be used for training the primary DNN. One problem with this approach is instability of the training caused by the approximation error of the score. To overcome this problem, we propose to use stabilization techniques borrowed from reinforcement learning. The experiments, aimed to increase the score of PESQ as an example, show that the proposed method (i) can stably train a DNN to increase PESQ, (ii) achieved the state-of-the-art PESQ score on a public dataset, and (iii) resulted in better sound quality than conventional methods based on subjective evaluation.