 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvergence Analysis of the Deep Galerkin Method for Weak Solutions
Feb 05, 2023This paper analyzes the convergence rate of a deep Galerkin method for the weak solution (DGMW) of second-order elliptic partial differential equations on $\mathbb{R}^d$ with Dirichlet, Neumann, and Robin boundary conditions, respectively. In DGMW, a deep neural network is applied to parametrize the PDE solution, and a second neural network is adopted to parametrize the test function in the traditional Galerkin formulation. By properly choosing the depth and width of these two networks in terms of the number of training samples $n$, it is shown that the convergence rate of DGMW is $\mathcal{O}(n^{-1/d})$, which is the first convergence result for weak solutions. The main idea of the proof is to divide the error of the DGMW into an approximation error and a statistical error. We derive an upper bound on the approximation error in the $H^{1}$ norm and bound the statistical error via Rademacher complexity.
Estimation of Non-Crossing Quantile Regression Process with Deep ReQU Neural Networks
Jul 21, 2022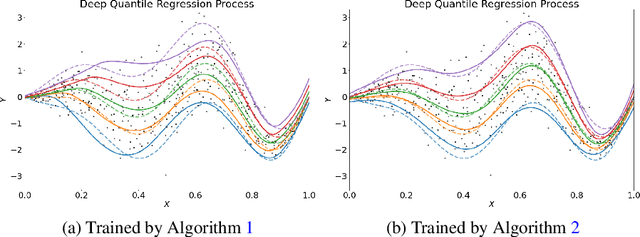
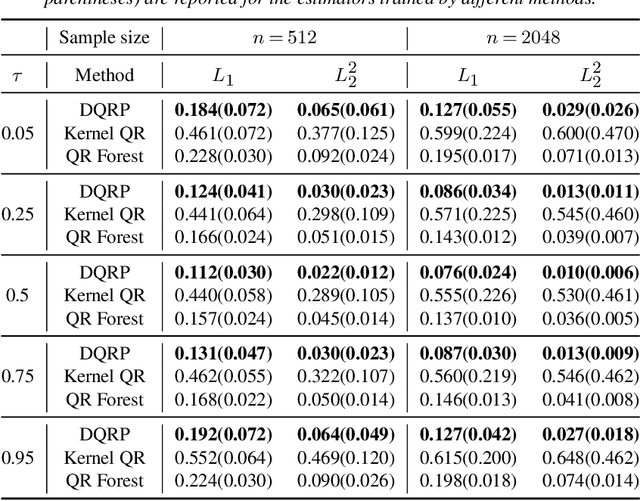
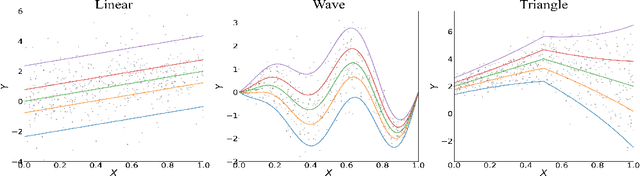
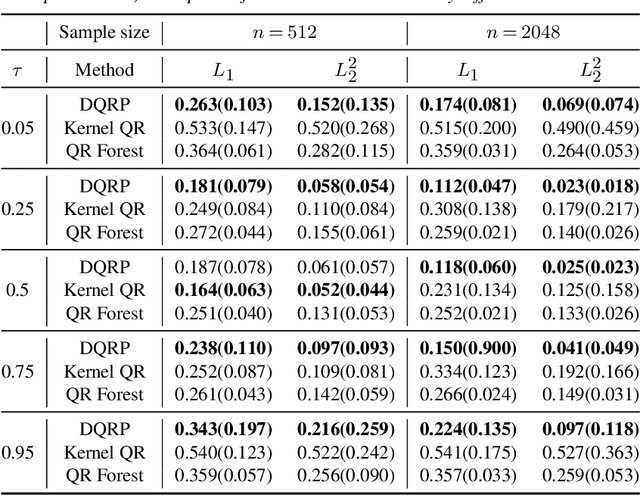
We propose a penalized nonparametric approach to estimating the quantile regression process (QRP) in a nonseparable model using rectifier quadratic unit (ReQU) activated deep neural networks and introduce a novel penalty function to enforce non-crossing of quantile regression curves. We establish the non-asymptotic excess risk bounds for the estimated QRP and derive the mean integrated squared error for the estimated QRP under mild smoothness and regularity conditions. To establish these non-asymptotic risk and estimation error bounds, we also develop a new error bound for approximating $C^s$ smooth functions with $s >0$ and their derivatives using ReQU activated neural networks. This is a new approximation result for ReQU networks and is of independent interest and may be useful in other problems. Our numerical experiments demonstrate that the proposed method is competitive with or outperforms two existing methods, including methods using reproducing kernels and random forests, for nonparametric quantile regression.
Efficient and practical quantum compiler towards multi-qubit systems with deep reinforcement learning
Apr 14, 2022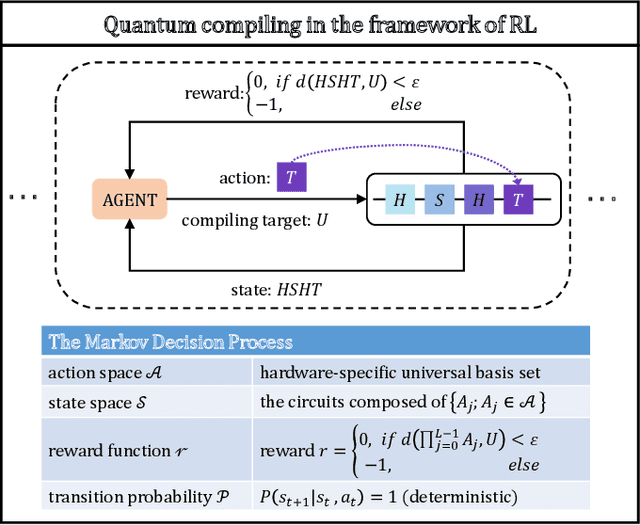
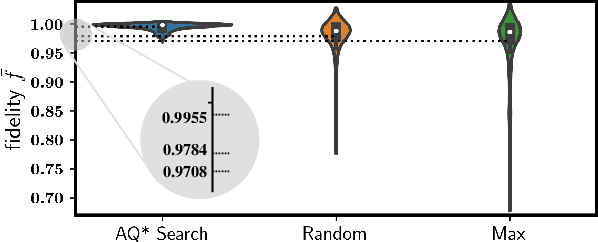
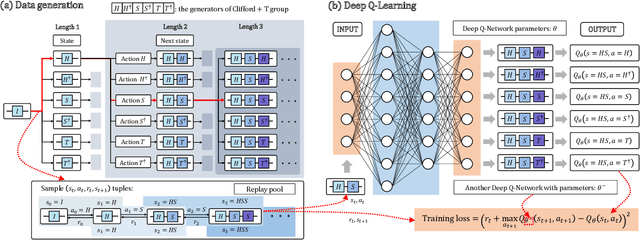
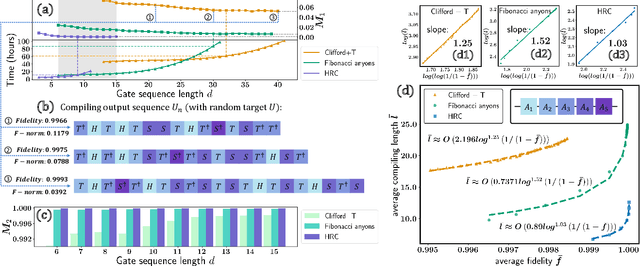
Efficient quantum compiling tactics greatly enhance the capability of quantum computers to execute complicated quantum algorithms. Due to its fundamental importance, a plethora of quantum compilers has been designed in past years. However, there are several caveats to current protocols, which are low optimality, high inference time, limited scalability, and lack of universality. To compensate for these defects, here we devise an efficient and practical quantum compiler assisted by advanced deep reinforcement learning (RL) techniques, i.e., data generation, deep Q-learning, and AQ* search. In this way, our protocol is compatible with various quantum machines and can be used to compile multi-qubit operators. We systematically evaluate the performance of our proposal in compiling quantum operators with both inverse-closed and inverse-free universal basis sets. In the task of single-qubit operator compiling, our proposal outperforms other RL-based quantum compilers in the measure of compiling sequence length and inference time. Meanwhile, the output solution is near-optimal, guaranteed by the Solovay-Kitaev theorem. Notably, for the inverse-free universal basis set, the achieved sequence length complexity is comparable with the inverse-based setting and dramatically advances previous methods. These empirical results contribute to improving the inverse-free Solovay-Kitaev theorem. In addition, for the first time, we demonstrate how to leverage RL-based quantum compilers to accomplish two-qubit operator compiling. The achieved results open an avenue for integrating RL with quantum compiling to unify efficiency and practicality and thus facilitate the exploration of quantum advantages.
Approximation bounds for norm constrained neural networks with applications to regression and GANs
Jan 24, 2022This paper studies the approximation capacity of ReLU neural networks with norm constraint on the weights. We prove upper and lower bounds on the approximation error of these networks for smooth function classes. The lower bound is derived through the Rademacher complexity of neural networks, which may be of independent interest. We apply these approximation bounds to analyze the convergence of regression using norm constrained neural networks and distribution estimation by GANs. In particular, we obtain convergence rates for over-parameterized neural networks. It is also shown that GANs can achieve optimal rate of learning probability distributions, when the discriminator is a properly chosen norm constrained neural network.
Wasserstein Generative Learning of Conditional Distribution
Dec 19, 2021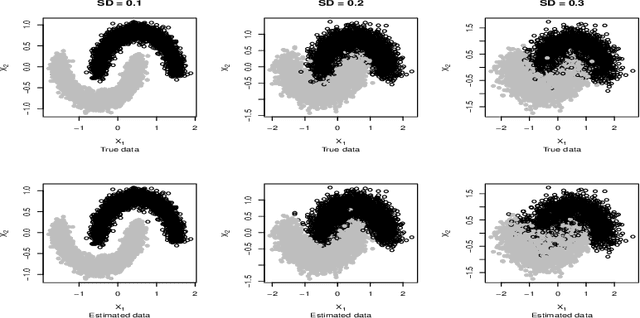
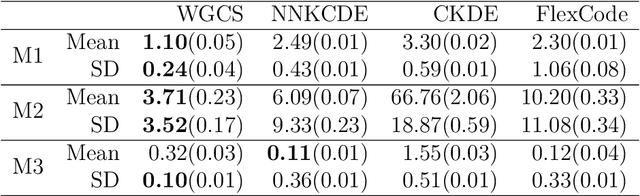
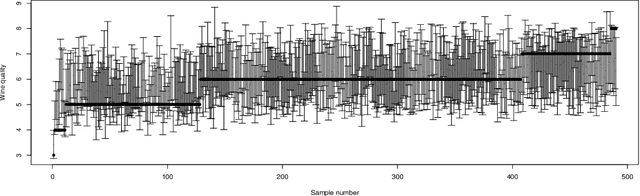
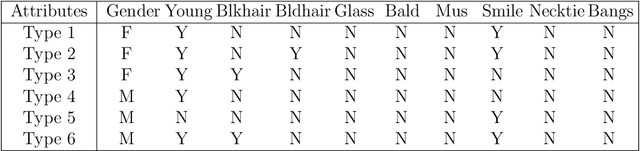
Conditional distribution is a fundamental quantity for describing the relationship between a response and a predictor. We propose a Wasserstein generative approach to learning a conditional distribution. The proposed approach uses a conditional generator to transform a known distribution to the target conditional distribution. The conditional generator is estimated by matching a joint distribution involving the conditional generator and the target joint distribution, using the Wasserstein distance as the discrepancy measure for these joint distributions. We establish non-asymptotic error bound of the conditional sampling distribution generated by the proposed method and show that it is able to mitigate the curse of dimensionality, assuming that the data distribution is supported on a lower-dimensional set. We conduct numerical experiments to validate proposed method and illustrate its applications to conditional sample generation, nonparametric conditional density estimation, prediction uncertainty quantification, bivariate response data, image reconstruction and image generation.
Just Least Squares: Binary Compressive Sampling with Low Generative Intrinsic Dimension
Nov 29, 2021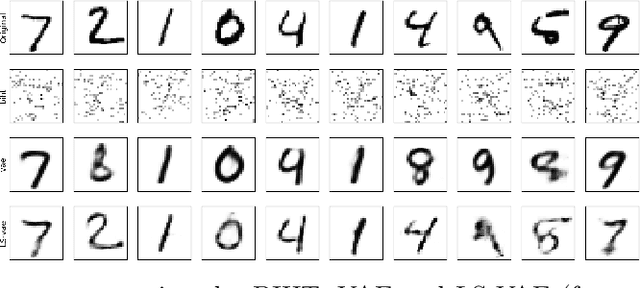



In this paper, we consider recovering $n$ dimensional signals from $m$ binary measurements corrupted by noises and sign flips under the assumption that the target signals have low generative intrinsic dimension, i.e., the target signals can be approximately generated via an $L$-Lipschitz generator $G: \mathbb{R}^k\rightarrow\mathbb{R}^{n}, k\ll n$. Although the binary measurements model is highly nonlinear, we propose a least square decoder and prove that, up to a constant $c$, with high probability, the least square decoder achieves a sharp estimation error $\mathcal{O} (\sqrt{\frac{k\log (Ln)}{m}})$ as long as $m\geq \mathcal{O}( k\log (Ln))$. Extensive numerical simulations and comparisons with state-of-the-art methods demonstrated the least square decoder is robust to noise and sign flips, as indicated by our theory. By constructing a ReLU network with properly chosen depth and width, we verify the (approximately) deep generative prior, which is of independent interest.
A Data-Driven Line Search Rule for Support Recovery in High-dimensional Data Analysis
Nov 21, 2021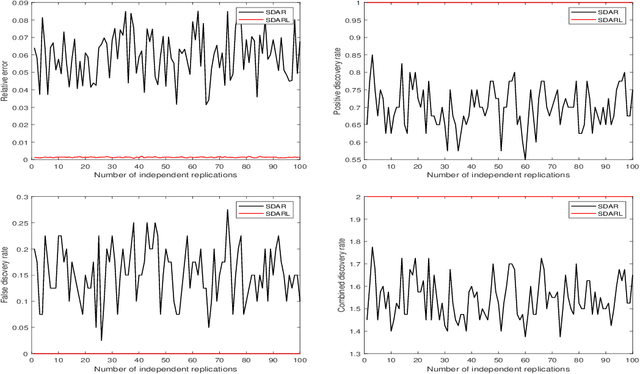
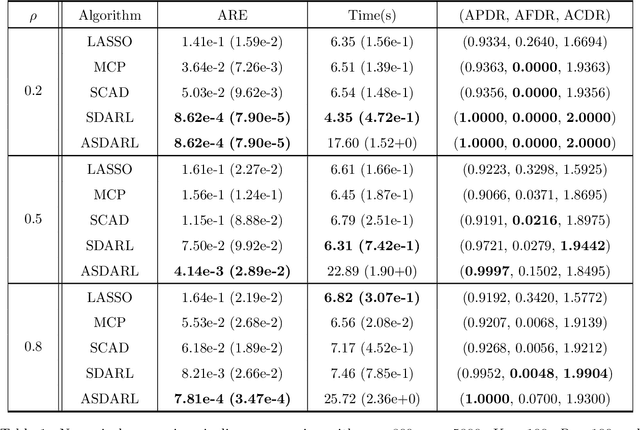
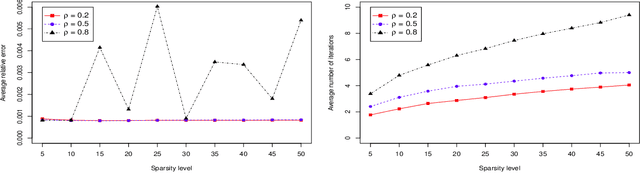
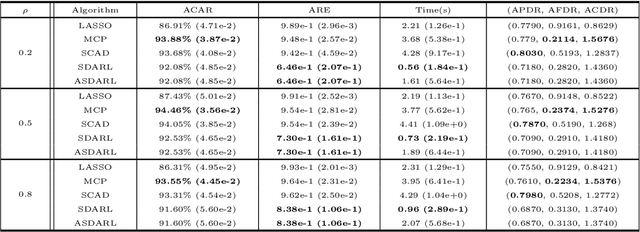
In this work, we consider the algorithm to the (nonlinear) regression problems with $\ell_0$ penalty. The existing algorithms for $\ell_0$ based optimization problem are often carried out with a fixed step size, and the selection of an appropriate step size depends on the restricted strong convexity and smoothness for the loss function, hence it is difficult to compute in practical calculation. In sprite of the ideas of support detection and root finding \cite{HJK2020}, we proposes a novel and efficient data-driven line search rule to adaptively determine the appropriate step size. We prove the $\ell_2$ error bound to the proposed algorithm without much restrictions for the cost functional. A large number of numerical comparisons with state-of-the-art algorithms in linear and logistic regression problems show the stability, effectiveness and superiority of the proposed algorithms.
Non-Asymptotic Error Bounds for Bidirectional GANs
Oct 24, 2021We derive nearly sharp bounds for the bidirectional GAN (BiGAN) estimation error under the Dudley distance between the latent joint distribution and the data joint distribution with appropriately specified architecture of the neural networks used in the model. To the best of our knowledge, this is the first theoretical guarantee for the bidirectional GAN learning approach. An appealing feature of our results is that they do not assume the reference and the data distributions to have the same dimensions or these distributions to have bounded support. These assumptions are commonly assumed in the existing convergence analysis of the unidirectional GANs but may not be satisfied in practice. Our results are also applicable to the Wasserstein bidirectional GAN if the target distribution is assumed to have a bounded support. To prove these results, we construct neural network functions that push forward an empirical distribution to another arbitrary empirical distribution on a possibly different-dimensional space. We also develop a novel decomposition of the integral probability metric for the error analysis of bidirectional GANs. These basic theoretical results are of independent interest and can be applied to other related learning problems.
Relative Entropy Gradient Sampler for Unnormalized Distributions
Oct 06, 2021
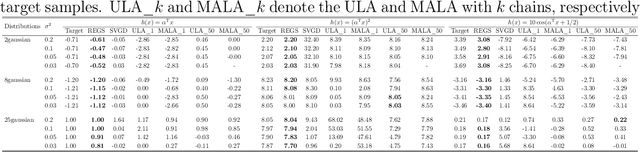
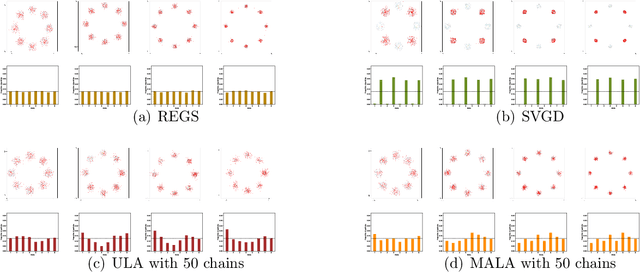
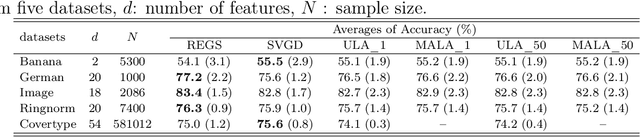
We propose a relative entropy gradient sampler (REGS) for sampling from unnormalized distributions. REGS is a particle method that seeks a sequence of simple nonlinear transforms iteratively pushing the initial samples from a reference distribution into the samples from an unnormalized target distribution. To determine the nonlinear transforms at each iteration, we consider the Wasserstein gradient flow of relative entropy. This gradient flow determines a path of probability distributions that interpolates the reference distribution and the target distribution. It is characterized by an ODE system with velocity fields depending on the density ratios of the density of evolving particles and the unnormalized target density. To sample with REGS, we need to estimate the density ratios and simulate the ODE system with particle evolution. We propose a novel nonparametric approach to estimating the logarithmic density ratio using neural networks. Extensive simulation studies on challenging multimodal 1D and 2D mixture distributions and Bayesian logistic regression on real datasets demonstrate that the REGS outperforms the state-of-the-art sampling methods included in the comparison.
Coordinate Descent for MCP/SCAD Penalized Least Squares Converges Linearly
Sep 18, 2021
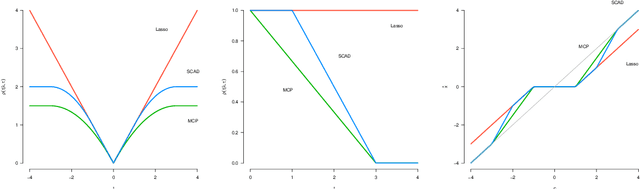
Recovering sparse signals from observed data is an important topic in signal/imaging processing, statistics and machine learning. Nonconvex penalized least squares have been attracted a lot of attentions since they enjoy nice statistical properties. Computationally, coordinate descent (CD) is a workhorse for minimizing the nonconvex penalized least squares criterion due to its simplicity and scalability. In this work, we prove the linear convergence rate to CD for solving MCP/SCAD penalized least squares problems.