 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrior Policy Guided Dual-Agent Coordinated Manipulation Planning of Spacecraft-Manipulator System
May 25, 2026The strong dynamic coupling between the manipulator and the base poses a significant challenge to maintaining spacecraft attitude stability, potentially compromising mission safety. In this paper, we propose a Dual-Agent Coordinated Manipulation Planning (DACMP) framework that simultaneously achieves high-precision end-effector pose reaching for a 6-DoF space manipulator and attitude stabilization of the base spacecraft. To enhance learning efficiency, we present a prior policy-guided Deep Reinforcement Learning algorithm incorporating the Timestep-level Expert Switching Guidance (TESG) mechanism, thereby promoting global convergence and improving task success rates. Extensive experiments demonstrate that DACMP significantly outperforms baseline DRL algorithms in terms of task success rate and control precision. Furthermore, the robustness of DACMP is validated under various challenging scenarios, including system constraints, environmental disturbances, and perception uncertainties. The code and simulation configurations are available on GitHub: https://github.com/HIT-YuhuiHu/DACMP.
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
SupportNet: solving catastrophic forgetting in class incremental learning with support data
Sep 01, 2018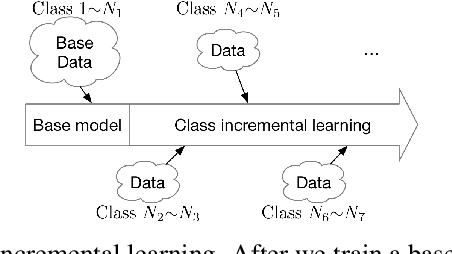
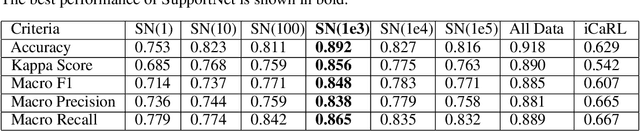
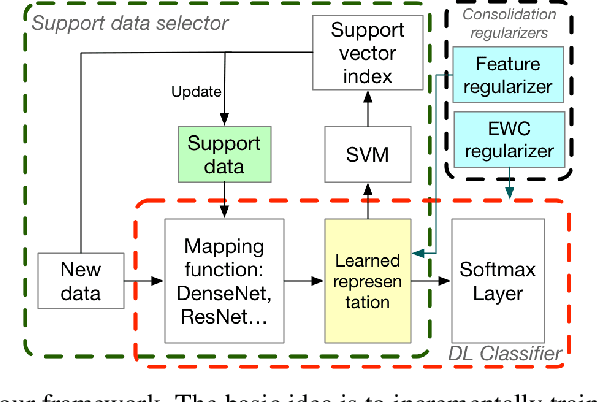
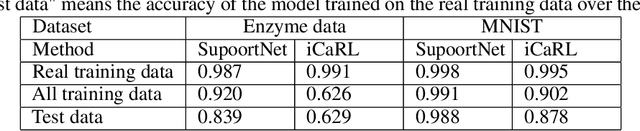
A plain well-trained deep learning model often does not have the ability to learn new knowledge without forgetting the previously learned knowledge, which is known as the catastrophic forgetting. Here we propose a novel method, SupportNet, to solve the catastrophic forgetting problem in class incremental learning scenario efficiently and effectively. SupportNet combines the strength of deep learning and support vector machine (SVM), where SVM is used to identify the support data from the old data, which are fed to the deep learning model together with the new data for further training so that the model can review the essential information of the old data when learning the new information. Two powerful consolidation regularizers are applied to ensure the robustness of the learned model. Comprehensive experiments on various tasks, including enzyme function prediction, subcellular structure classification and breast tumor classification, show that SupportNet drastically outperforms the state-of-the-art incremental learning methods and even reaches similar performance as the deep learning model trained from scratch on both old and new data. Our program is accessible at: https://github.com/lykaust15/SupportNet