 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDGS-LRM: Real-Time Deformable 3D Gaussian Reconstruction From Monocular Videos
Jun 11, 2025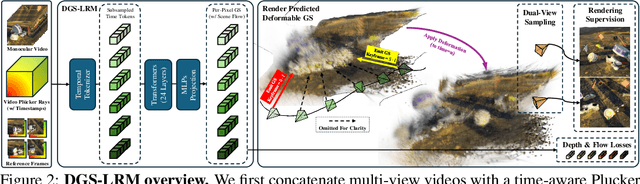
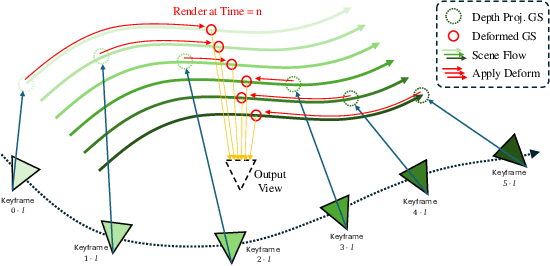
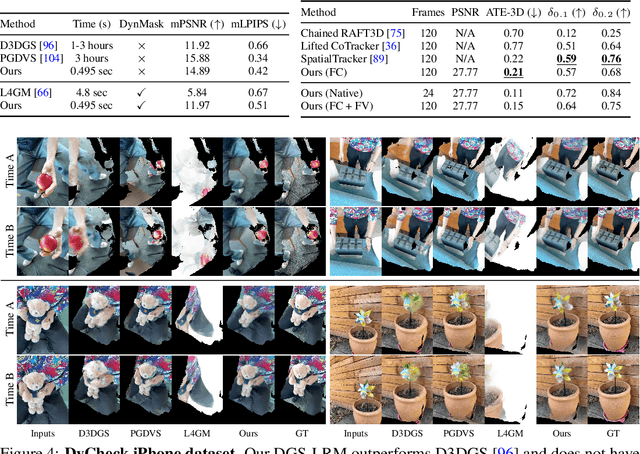

We introduce the Deformable Gaussian Splats Large Reconstruction Model (DGS-LRM), the first feed-forward method predicting deformable 3D Gaussian splats from a monocular posed video of any dynamic scene. Feed-forward scene reconstruction has gained significant attention for its ability to rapidly create digital replicas of real-world environments. However, most existing models are limited to static scenes and fail to reconstruct the motion of moving objects. Developing a feed-forward model for dynamic scene reconstruction poses significant challenges, including the scarcity of training data and the need for appropriate 3D representations and training paradigms. To address these challenges, we introduce several key technical contributions: an enhanced large-scale synthetic dataset with ground-truth multi-view videos and dense 3D scene flow supervision; a per-pixel deformable 3D Gaussian representation that is easy to learn, supports high-quality dynamic view synthesis, and enables long-range 3D tracking; and a large transformer network that achieves real-time, generalizable dynamic scene reconstruction. Extensive qualitative and quantitative experiments demonstrate that DGS-LRM achieves dynamic scene reconstruction quality comparable to optimization-based methods, while significantly outperforming the state-of-the-art predictive dynamic reconstruction method on real-world examples. Its predicted physically grounded 3D deformation is accurate and can readily adapt for long-range 3D tracking tasks, achieving performance on par with state-of-the-art monocular video 3D tracking methods.
CrossScore: Towards Multi-View Image Evaluation and Scoring
Apr 22, 2024We introduce a novel cross-reference image quality assessment method that effectively fills the gap in the image assessment landscape, complementing the array of established evaluation schemes -- ranging from full-reference metrics like SSIM, no-reference metrics such as NIQE, to general-reference metrics including FID, and Multi-modal-reference metrics, e.g., CLIPScore. Utilising a neural network with the cross-attention mechanism and a unique data collection pipeline from NVS optimisation, our method enables accurate image quality assessment without requiring ground truth references. By comparing a query image against multiple views of the same scene, our method addresses the limitations of existing metrics in novel view synthesis (NVS) and similar tasks where direct reference images are unavailable. Experimental results show that our method is closely correlated to the full-reference metric SSIM, while not requiring ground truth references.