 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiologically Inspired Dynamic Thresholds for Spiking Neural Networks
Jun 09, 2022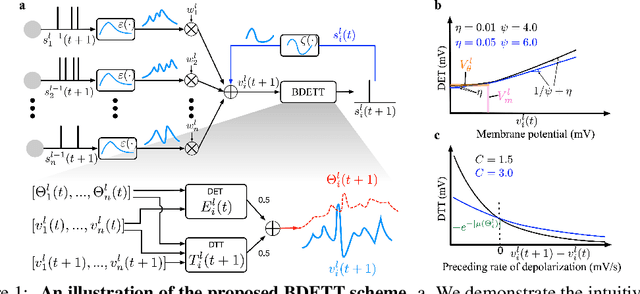
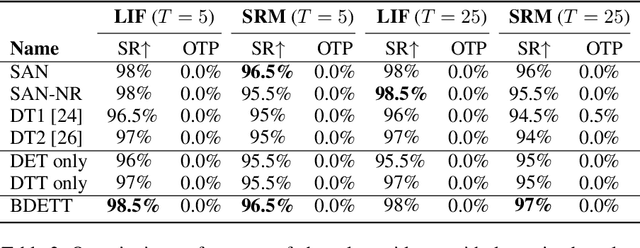
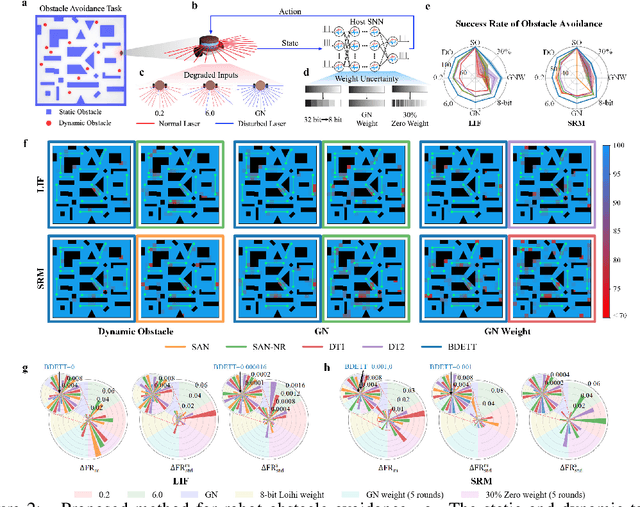
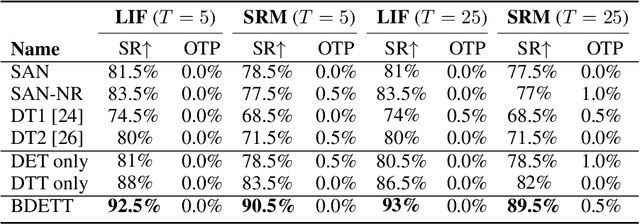
The dynamic membrane potential threshold, as one of the essential properties of a biological neuron, is a spontaneous regulation mechanism that maintains neuronal homeostasis, i.e., the constant overall spiking firing rate of a neuron. As such, the neuron firing rate is regulated by a dynamic spiking threshold, which has been extensively studied in biology. Existing work in the machine learning community does not employ bioplausible spiking threshold schemes. This work aims at bridging this gap by introducing a novel bioinspired dynamic energy-temporal threshold (BDETT) scheme for spiking neural networks (SNNs). The proposed BDETT scheme mirrors two bioplausible observations: a dynamic threshold has 1) a positive correlation with the average membrane potential and 2) a negative correlation with the preceding rate of depolarization. We validate the effectiveness of the proposed BDETT on robot obstacle avoidance and continuous control tasks under both normal conditions and various degraded conditions, including noisy observations, weights, and dynamic environments. We find that the BDETT outperforms existing static and heuristic threshold approaches by significant margins in all tested conditions, and we confirm that the proposed bioinspired dynamic threshold scheme offers bioplausible homeostasis to SNNs in complex real-world tasks.
Dynamic N:M Fine-grained Structured Sparse Attention Mechanism
Feb 28, 2022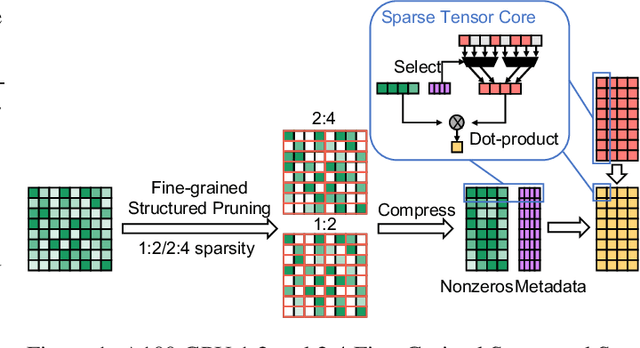
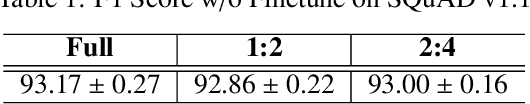
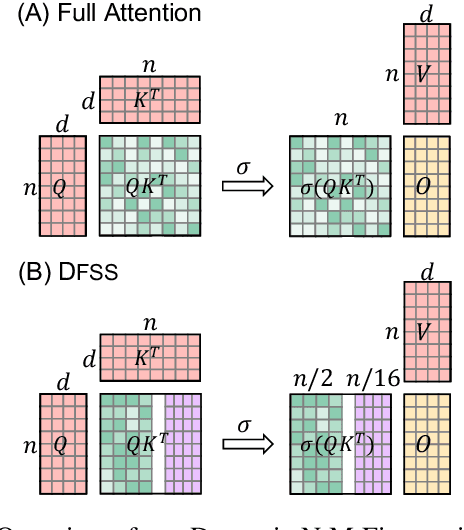
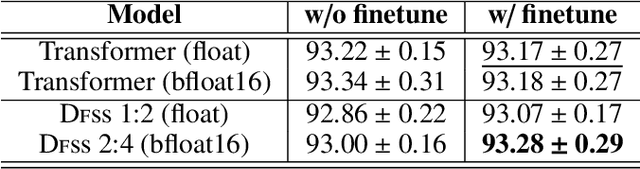
Transformers are becoming the mainstream solutions for various tasks like NLP and Computer vision. Despite their success, the high complexity of the attention mechanism hinders them from being applied to latency-sensitive tasks. Tremendous efforts have been made to alleviate this problem, and many of them successfully reduce the asymptotic complexity to linear. Nevertheless, most of them fail to achieve practical speedup over the original full attention under moderate sequence lengths and are unfriendly to finetuning. In this paper, we present DFSS, an attention mechanism that dynamically prunes the full attention weight matrix to N:M fine-grained structured sparse pattern. We provide both theoretical and empirical evidence that demonstrates DFSS is a good approximation of the full attention mechanism. We propose a dedicated CUDA kernel design that completely eliminates the dynamic pruning overhead and achieves speedups under arbitrary sequence length. We evaluate the 1:2 and 2:4 sparsity under different configurations and achieve 1.27~ 1.89x speedups over the full-attention mechanism. It only takes a couple of finetuning epochs from the pretrained model to achieve on par accuracy with full attention mechanism on tasks from various domains under different sequence lengths from 384 to 4096.
Attacking Point Cloud Segmentation with Color-only Perturbation
Dec 18, 2021
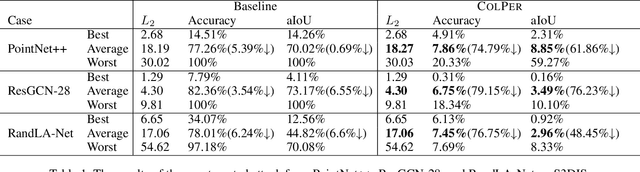


Recent research efforts on 3D point-cloud semantic segmentation have achieved outstanding performance by adopting deep CNN (convolutional neural networks) and GCN (graph convolutional networks). However, the robustness of these complex models has not been systematically analyzed. Given that semantic segmentation has been applied in many safety-critical applications (e.g., autonomous driving, geological sensing), it is important to fill this knowledge gap, in particular, how these models are affected under adversarial samples. While adversarial attacks against point cloud have been studied, we found all of them were targeting single-object recognition, and the perturbation is done on the point coordinates. We argue that the coordinate-based perturbation is unlikely to realize under the physical-world constraints. Hence, we propose a new color-only perturbation method named COLPER, and tailor it to semantic segmentation. By evaluating COLPER on an indoor dataset (S3DIS) and an outdoor dataset (Semantic3D) against three point cloud segmentation models (PointNet++, DeepGCNs, and RandLA-Net), we found color-only perturbation is sufficient to significantly drop the segmentation accuracy and aIoU, under both targeted and non-targeted attack settings.
TC-GNN: Accelerating Sparse Graph Neural Network Computation Via Dense Tensor Core on GPUs
Dec 03, 2021
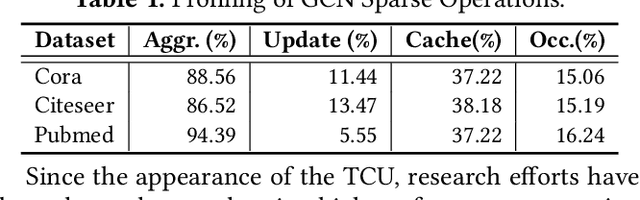
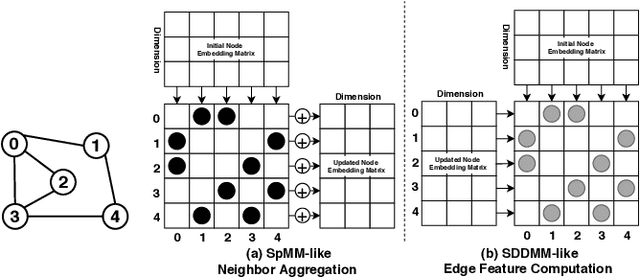

Recently, graph neural networks (GNNs), as the backbone of graph-based machine learning, demonstrate great success in various domains (e.g., e-commerce). However, the performance of GNNs is usually unsatisfactory due to the highly sparse and irregular graph-based operations. To this end, we propose, TC-GNN, the first GPU Tensor Core Unit (TCU) based GNN acceleration framework. The core idea is to reconcile the "Sparse" GNN computation with "Dense" TCU. Specifically, we conduct an in-depth analysis of the sparse operations in mainstream GNN computing frameworks. We introduce a novel sparse graph translation technique to facilitate TCU processing of sparse GNN workload. We also implement an effective CUDA core and TCU collaboration design to fully utilize GPU resources. We fully integrate TC-GNN with the Pytorch framework for ease of programming. Rigorous experiments show an average of 1.70X speedup over the state-of-the-art Deep Graph Library framework across various GNN models and dataset settings.
Towards Efficient Ansatz Architecture for Variational Quantum Algorithms
Nov 26, 2021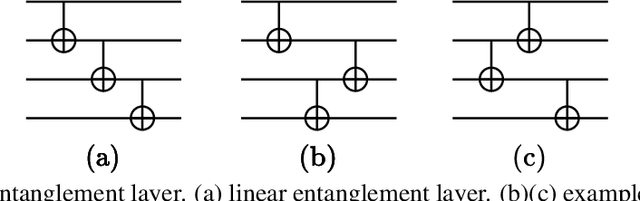
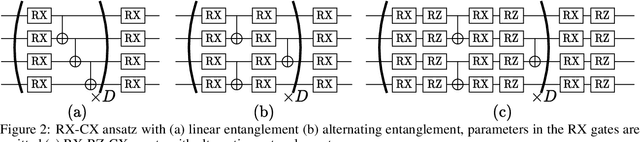
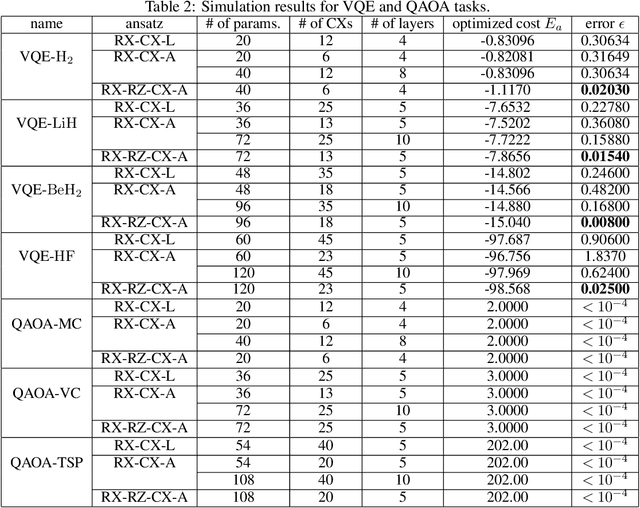
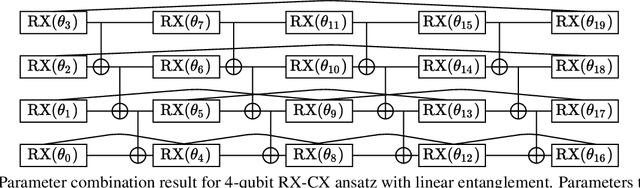
Variational quantum algorithms are expected to demonstrate the advantage of quantum computing on near-term noisy quantum computers. However, training such variational quantum algorithms suffers from gradient vanishing as the size of the algorithm increases. Previous work cannot handle the gradient vanishing induced by the inevitable noise effects on realistic quantum hardware. In this paper, we propose a novel training scheme to mitigate such noise-induced gradient vanishing. We first introduce a new cost function of which the gradients are significantly augmented by employing traceless observables in truncated subspace. We then prove that the same minimum can be reached by optimizing the original cost function with the gradients from the new cost function. Experiments show that our new training scheme is highly effective for major variational quantum algorithms of various tasks.
Mitigating Noise-Induced Gradient Vanishing in Variational Quantum Algorithm Training
Nov 25, 2021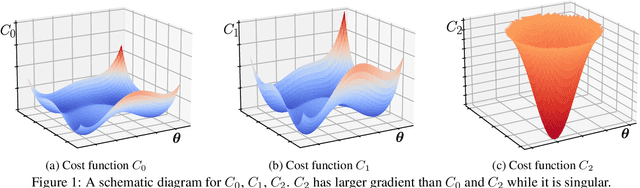
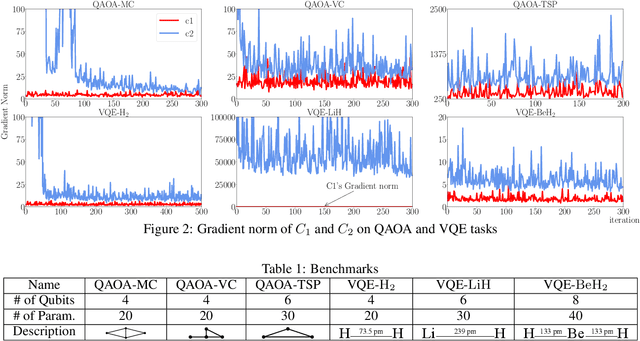
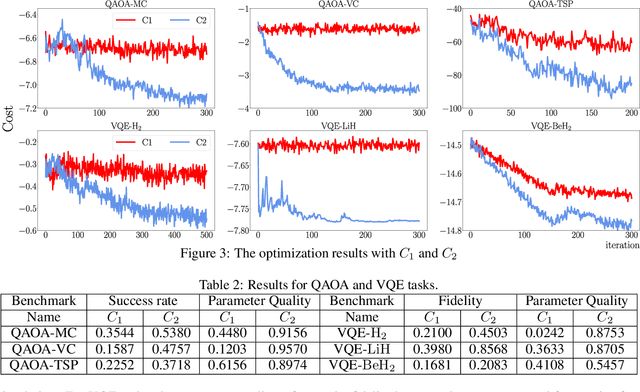
Variational quantum algorithms are expected to demonstrate the advantage of quantum computing on near-term noisy quantum computers. However, training such variational quantum algorithms suffers from gradient vanishing as the size of the algorithm increases. Previous work cannot handle the gradient vanishing induced by the inevitable noise effects on realistic quantum hardware. In this paper, we propose a novel training scheme to mitigate such noise-induced gradient vanishing. We first introduce a new cost function of which the gradients are significantly augmented by employing traceless observables in truncated subspace. We then prove that the same minimum can be reached by optimizing the original cost function with the gradients from the new cost function. Experiments show that our new training scheme is highly effective for major variational quantum algorithms of various tasks.
Transformer Acceleration with Dynamic Sparse Attention
Oct 21, 2021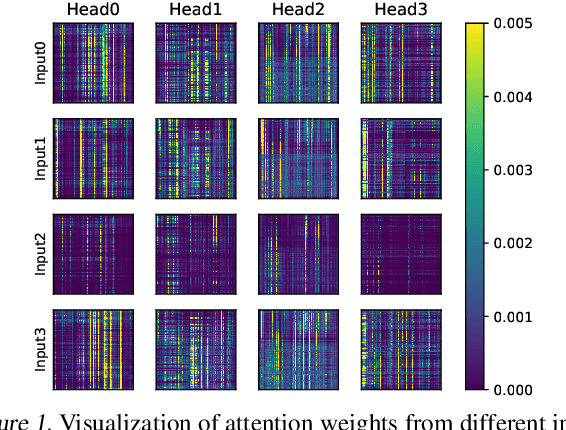
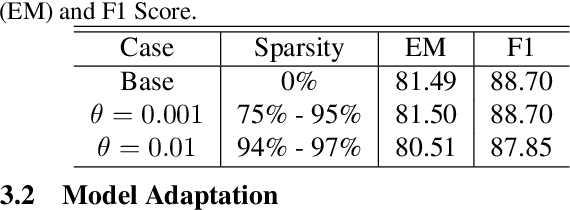
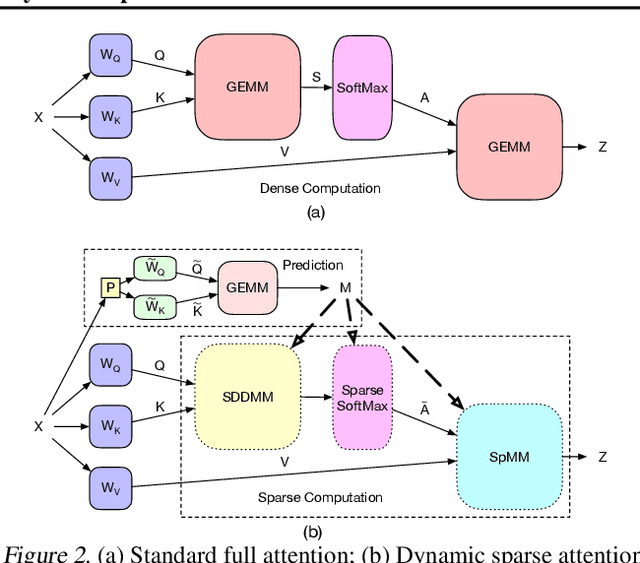
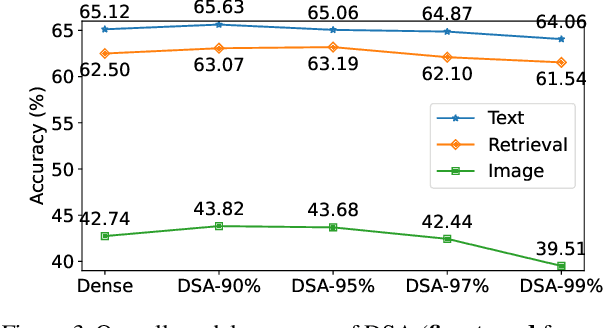
Transformers are the mainstream of NLP applications and are becoming increasingly popular in other domains such as Computer Vision. Despite the improvements in model quality, the enormous computation costs make Transformers difficult at deployment, especially when the sequence length is large in emerging applications. Processing attention mechanism as the essential component of Transformer is the bottleneck of execution due to the quadratic complexity. Prior art explores sparse patterns in attention to support long sequence modeling, but those pieces of work are on static or fixed patterns. We demonstrate that the sparse patterns are dynamic, depending on input sequences. Thus, we propose the Dynamic Sparse Attention (DSA) that can efficiently exploit the dynamic sparsity in the attention of Transformers. Compared with other methods, our approach can achieve better trade-offs between accuracy and model complexity. Moving forward, we identify challenges and provide solutions to implement DSA on existing hardware (GPUs) and specialized hardware in order to achieve practical speedup and efficiency improvements for Transformer execution.
Understanding GNN Computational Graph: A Coordinated Computation, IO, and Memory Perspective
Oct 18, 2021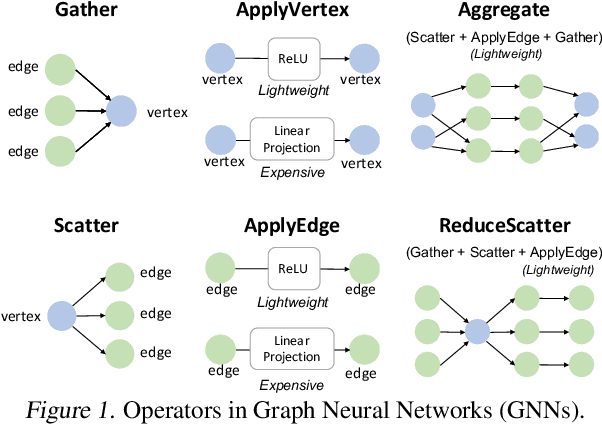
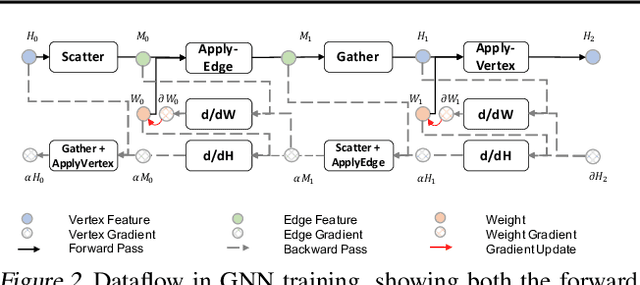
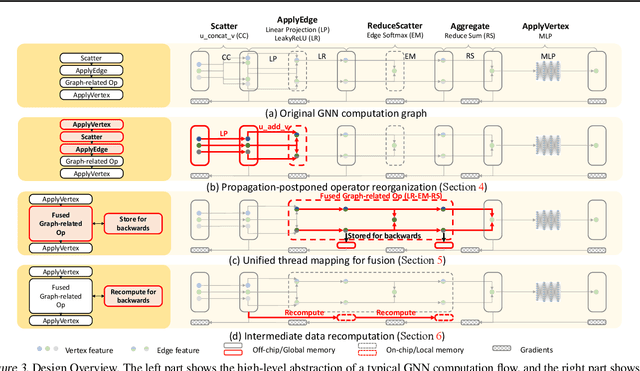
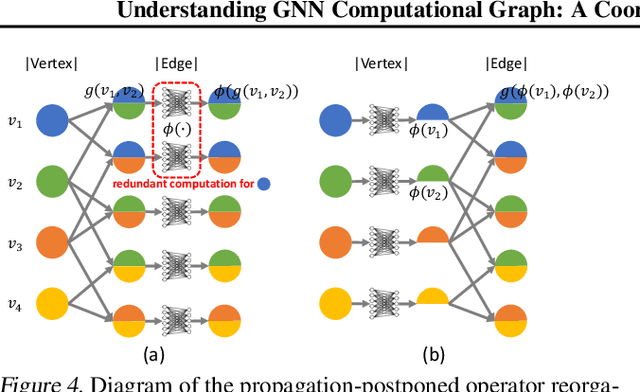
Graph Neural Networks (GNNs) have been widely used in various domains, and GNNs with sophisticated computational graph lead to higher latency and larger memory consumption. Optimizing the GNN computational graph suffers from: (1) Redundant neural operator computation. The same data are propagated through the graph structure to perform the same neural operation multiple times in GNNs, leading to redundant computation which accounts for 92.4% of total operators. (2) Inconsistent thread mapping. Efficient thread mapping schemes for vertex-centric and edge-centric operators are different. This inconsistency prohibits operator fusion to reduce memory IO. (3) Excessive intermediate data. For GNN training which is usually performed concurrently with inference, intermediate data must be stored for the backward pass, consuming 91.9% of the total memory requirement. To tackle these challenges, we propose following designs to optimize the GNN computational graph from a novel coordinated computation, IO, and memory perspective: (1) Propagation-postponed operator reorganization. We reorganize operators to perform neural operations before the propagation, thus the redundant computation is eliminated. (2) Unified thread mapping for fusion. We propose a unified thread mapping scheme for both vertex- and edge-centric operators to enable fusion and reduce IO. (3) Intermediate data recomputation. Intermediate data are recomputed during the backward pass to reduce the total memory consumption. Extensive experimental results on three typical GNN models show that, we achieve up to 2.75x end-to-end speedup, 6.89x less memory IO, and 7.73x less memory consumption over state-of-the-art frameworks.
APNN-TC: Accelerating Arbitrary Precision Neural Networks on Ampere GPU Tensor Cores
Jun 23, 2021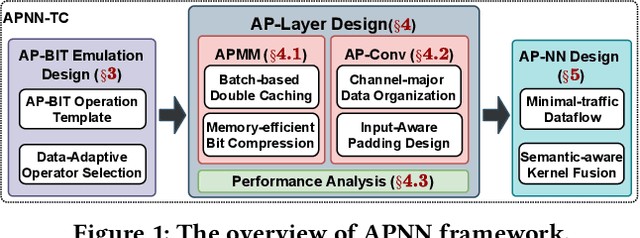

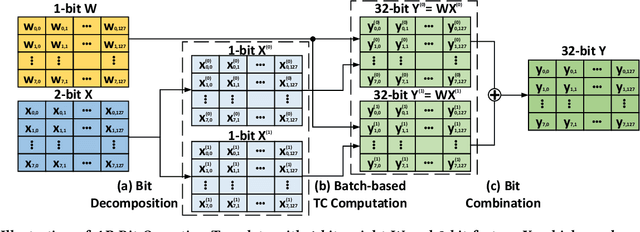

Over the years, accelerating neural networks with quantization has been widely studied. Unfortunately, prior efforts with diverse precisions (e.g., 1-bit weights and 2-bit activations) are usually restricted by limited precision support on GPUs (e.g., int1 and int4). To break such restrictions, we introduce the first Arbitrary Precision Neural Network framework (APNN-TC) to fully exploit quantization benefits on Ampere GPU Tensor Cores. Specifically, APNN-TC first incorporates a novel emulation algorithm to support arbitrary short bit-width computation with int1 compute primitives and XOR/AND Boolean operations. Second, APNN-TC integrates arbitrary precision layer designs to efficiently map our emulation algorithm to Tensor Cores with novel batching strategies and specialized memory organization. Third, APNN-TC embodies a novel arbitrary precision NN design to minimize memory access across layers and further improve performance. Extensive evaluations show that APNN-TC can achieve significant speedup over CUTLASS kernels and various NN models, such as ResNet and VGG.
DSXplore: Optimizing Convolutional Neural Networks via Sliding-Channel Convolutions
Jan 04, 2021
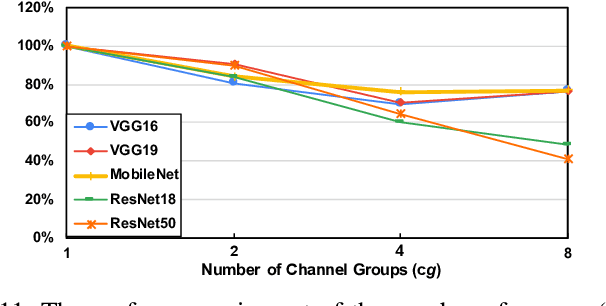
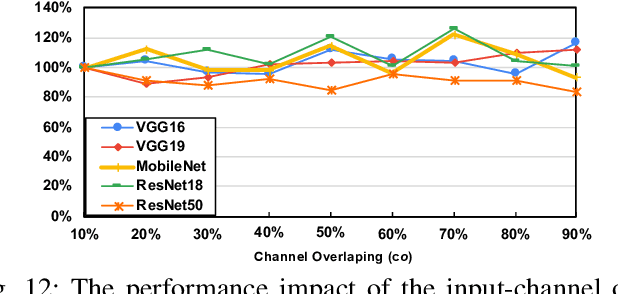
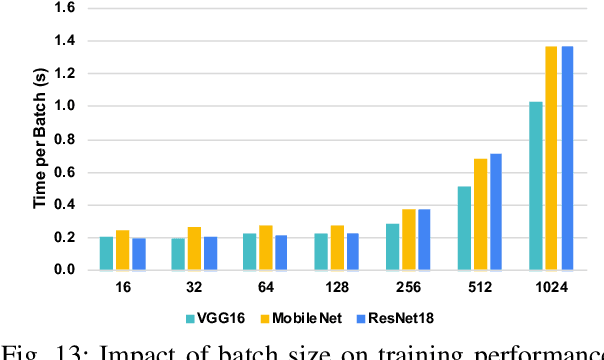
As the key advancement of the convolutional neural networks (CNNs), depthwise separable convolutions (DSCs) are becoming one of the most popular techniques to reduce the computations and parameters size of CNNs meanwhile maintaining the model accuracy. It also brings profound impact to improve the applicability of the compute- and memory-intensive CNNs to a broad range of applications, such as mobile devices, which are generally short of computation power and memory. However, previous research in DSCs are largely focusing on compositing the limited existing DSC designs, thus, missing the opportunities to explore more potential designs that can achieve better accuracy and higher computation/parameter reduction. Besides, the off-the-shelf convolution implementations offer limited computing schemes, therefore, lacking support for DSCs with different convolution patterns. To this end, we introduce, DSXplore, the first optimized design for exploring DSCs on CNNs. Specifically, at the algorithm level, DSXplore incorporates a novel factorized kernel -- sliding-channel convolution (SCC), featured with input-channel overlapping to balance the accuracy performance and the reduction of computation and memory cost. SCC also offers enormous space for design exploration by introducing adjustable kernel parameters. Further, at the implementation level, we carry out an optimized GPU-implementation tailored for SCC by leveraging several key techniques, such as the input-centric backward design and the channel-cyclic optimization. Intensive experiments on different datasets across mainstream CNNs show the advantages of DSXplore in balancing accuracy and computation/parameter reduction over the standard convolution and the existing DSCs.