 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAliMark: Enhancing Robustness of Sentence-Level Watermarking Against Text Paraphrasing
May 28, 2026Existing sentence-level watermarking methods enhance robustness to paraphrasing by anchoring watermarks in sentence semantics. However, their prefix-based designs remain vulnerable to structural perturbations, such as sentence splitting and merging, which commonly arise under strong paraphrasers like DIPPER and GPT-3.5. To mitigate this issue, we propose AliMark, a framework that reformulates sentence-level watermarking as a bit sequence encoding and alignment problem between a potentially watermarked text and a secret bit sequence. Notably, our approach adopts a two-stage detection strategy: we generate multiple restructured text variants and adaptively align their extracted bit sequences with the secret bit sequence to minimize alignment cost. This multi-candidate alignment design naturally improves robustness to sentence merges and splits. Extensive experiments demonstrate that AliMark substantially outperforms state-of-the-art baselines under diverse paraphrasing attacks.
WARD: Adversarially Robust Defense of Web Agents Against Prompt Injections
May 14, 2026Web agents can autonomously complete online tasks by interacting with websites, but their exposure to open web environments makes them vulnerable to prompt injection attacks embedded in HTML content or visual interfaces. Existing guard models still suffer from limited generalization to unseen domains and attack patterns, high false positive rates on benign content, reduced deployment efficiency due to added latency at each step, and vulnerability to adversarial attacks that evolve over time or directly target the guard itself. To address these limitations, we propose WARD (Web Agent Robust Defense against Prompt Injection), a practical guard model for secure and efficient web agents. WARD is built on WARD-Base, a large-scale dataset with around 177K samples collected from 719 high-traffic URLs and platforms, and WARD-PIG, a dedicated dataset designed for prompt injection attacks targeting the guard model. We further introduce A3T, an adaptive adversarial attack training framework that iteratively strengthens WARD through a memory-based attacker and guard co-evolution process. Extensive experiments show that WARD achieves nearly perfect recall on out-of-distribution benchmarks, maintains low false positive rates to preserve agent utility, remains robust against guard-targeted and adaptive attacks under substantial distribution shifts, and runs efficiently in parallel with the agent without introducing additional latency.
KnowPhish: Large Language Models Meet Multimodal Knowledge Graphs for Enhancing Reference-Based Phishing Detection
Mar 04, 2024



Phishing attacks have inflicted substantial losses on individuals and businesses alike, necessitating the development of robust and efficient automated phishing detection approaches. Reference-based phishing detectors (RBPDs), which compare the logos on a target webpage to a known set of logos, have emerged as the state-of-the-art approach. However, a major limitation of existing RBPDs is that they rely on a manually constructed brand knowledge base, making it infeasible to scale to a large number of brands, which results in false negative errors due to the insufficient brand coverage of the knowledge base. To address this issue, we propose an automated knowledge collection pipeline, using which we collect and release a large-scale multimodal brand knowledge base, KnowPhish, containing 20k brands with rich information about each brand. KnowPhish can be used to boost the performance of existing RBPDs in a plug-and-play manner. A second limitation of existing RBPDs is that they solely rely on the image modality, ignoring useful textual information present in the webpage HTML. To utilize this textual information, we propose a Large Language Model (LLM)-based approach to extract brand information of webpages from text. Our resulting multimodal phishing detection approach, KnowPhish Detector (KPD), can detect phishing webpages with or without logos. We evaluate KnowPhish and KPD on a manually validated dataset, and on a field study under Singapore's local context, showing substantial improvements in effectiveness and efficiency compared to state-of-the-art baselines.
Word-Free Spoken Language Understanding for Mandarin-Chinese
Jul 01, 2021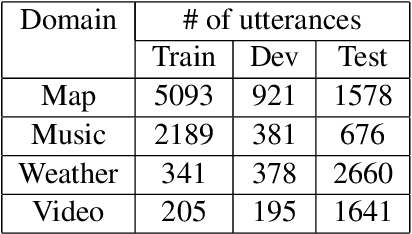
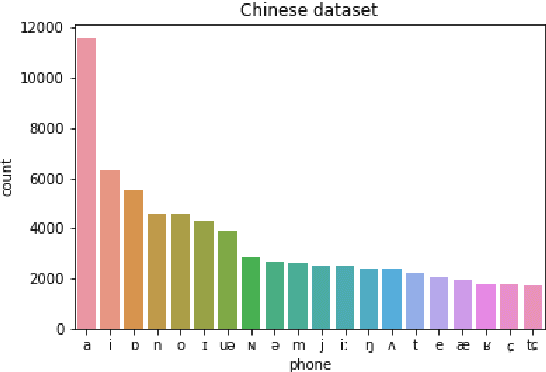
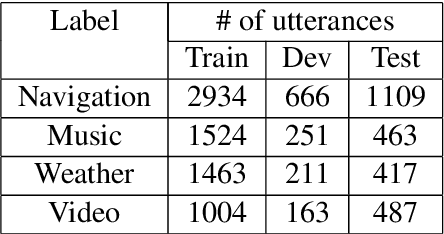
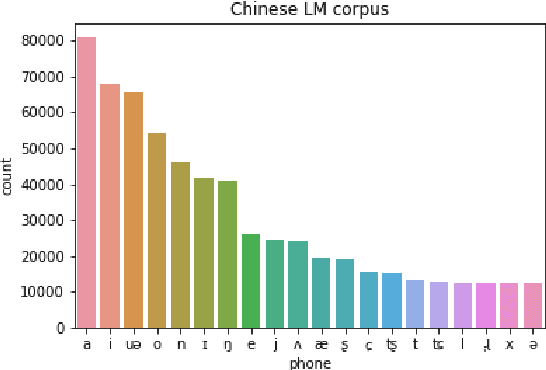
Spoken dialogue systems such as Siri and Alexa provide great convenience to people's everyday life. However, current spoken language understanding (SLU) pipelines largely depend on automatic speech recognition (ASR) modules, which require a large amount of language-specific training data. In this paper, we propose a Transformer-based SLU system that works directly on phones. This acoustic-based SLU system consists of only two blocks and does not require the presence of ASR module. The first block is a universal phone recognition system, and the second block is a Transformer-based language model for phones. We verify the effectiveness of the system on an intent classification dataset in Mandarin Chinese.