 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Spatial-Frequency Transformer for Visual Object Tracking
Aug 18, 2022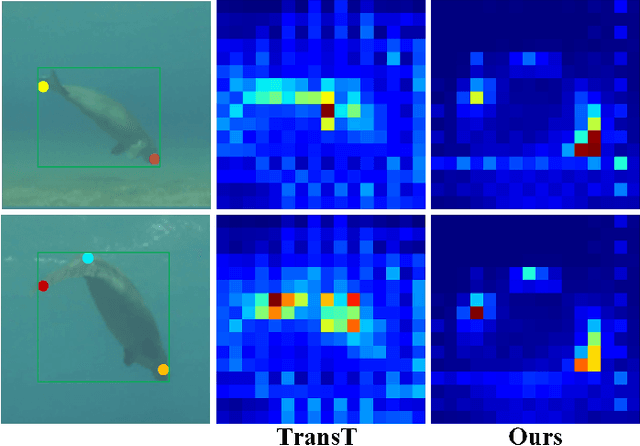
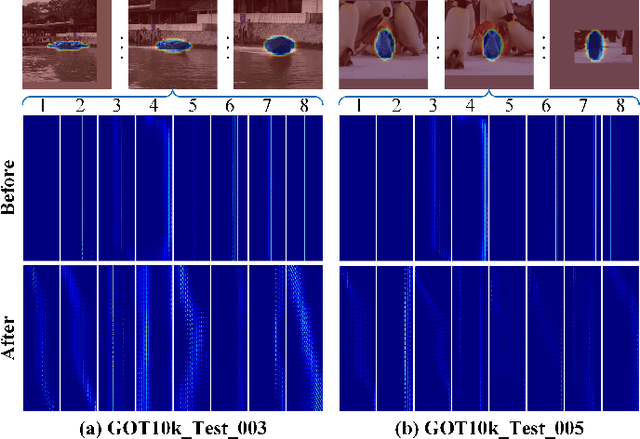

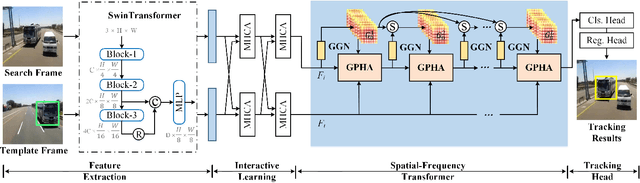
Recent trackers adopt the Transformer to combine or replace the widely used ResNet as their new backbone network. Although their trackers work well in regular scenarios, however, they simply flatten the 2D features into a sequence to better match the Transformer. We believe these operations ignore the spatial prior of the target object which may lead to sub-optimal results only. In addition, many works demonstrate that self-attention is actually a low-pass filter, which is independent of input features or key/queries. That is to say, it may suppress the high-frequency component of the input features and preserve or even amplify the low-frequency information. To handle these issues, in this paper, we propose a unified Spatial-Frequency Transformer that models the Gaussian spatial Prior and High-frequency emphasis Attention (GPHA) simultaneously. To be specific, Gaussian spatial prior is generated using dual Multi-Layer Perceptrons (MLPs) and injected into the similarity matrix produced by multiplying Query and Key features in self-attention. The output will be fed into a Softmax layer and then decomposed into two components, i.e., the direct signal and high-frequency signal. The low- and high-pass branches are rescaled and combined to achieve all-pass, therefore, the high-frequency features will be protected well in stacked self-attention layers. We further integrate the Spatial-Frequency Transformer into the Siamese tracking framework and propose a novel tracking algorithm, termed SFTransT. The cross-scale fusion based SwinTransformer is adopted as the backbone, and also a multi-head cross-attention module is used to boost the interaction between search and template features. The output will be fed into the tracking head for target localization. Extensive experiments on both short-term and long-term tracking benchmarks all demonstrate the effectiveness of our proposed framework.
Towards End-to-End Image Compression and Analysis with Transformers
Dec 17, 2021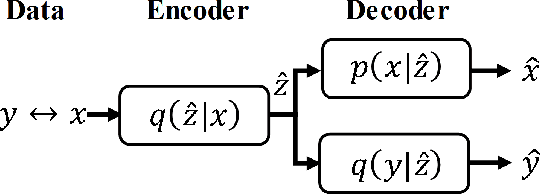
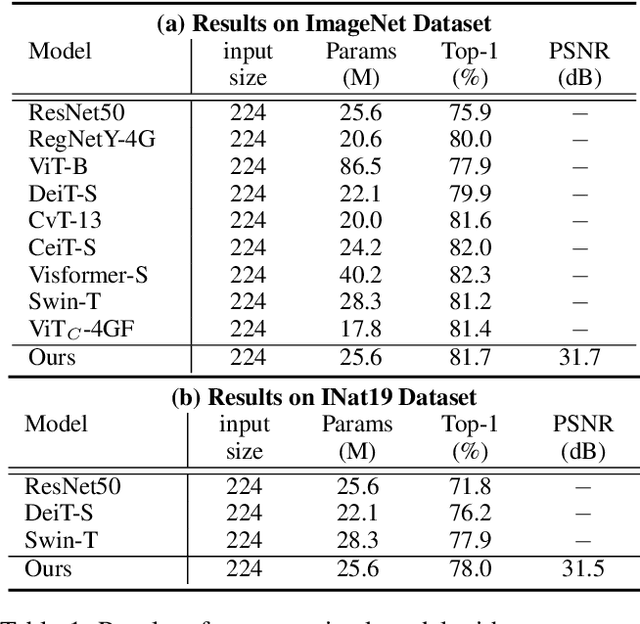
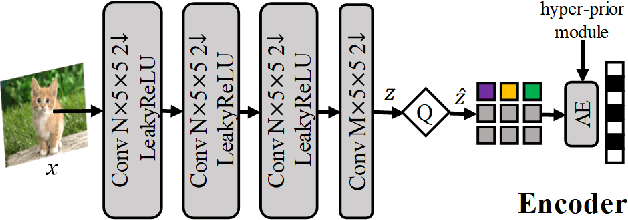
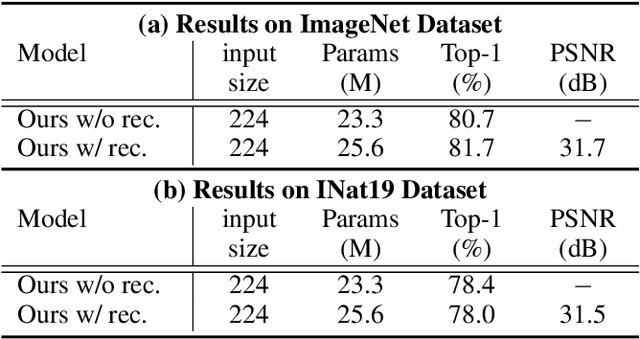
We propose an end-to-end image compression and analysis model with Transformers, targeting to the cloud-based image classification application. Instead of placing an existing Transformer-based image classification model directly after an image codec, we aim to redesign the Vision Transformer (ViT) model to perform image classification from the compressed features and facilitate image compression with the long-term information from the Transformer. Specifically, we first replace the patchify stem (i.e., image splitting and embedding) of the ViT model with a lightweight image encoder modelled by a convolutional neural network. The compressed features generated by the image encoder are injected convolutional inductive bias and are fed to the Transformer for image classification bypassing image reconstruction. Meanwhile, we propose a feature aggregation module to fuse the compressed features with the selected intermediate features of the Transformer, and feed the aggregated features to a deconvolutional neural network for image reconstruction. The aggregated features can obtain the long-term information from the self-attention mechanism of the Transformer and improve the compression performance. The rate-distortion-accuracy optimization problem is finally solved by a two-step training strategy. Experimental results demonstrate the effectiveness of the proposed model in both the image compression and the classification tasks.
Weakly-Supervised Monocular Depth Estimationwith Resolution-Mismatched Data
Sep 23, 2021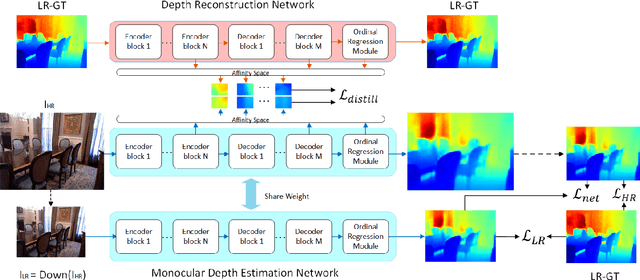
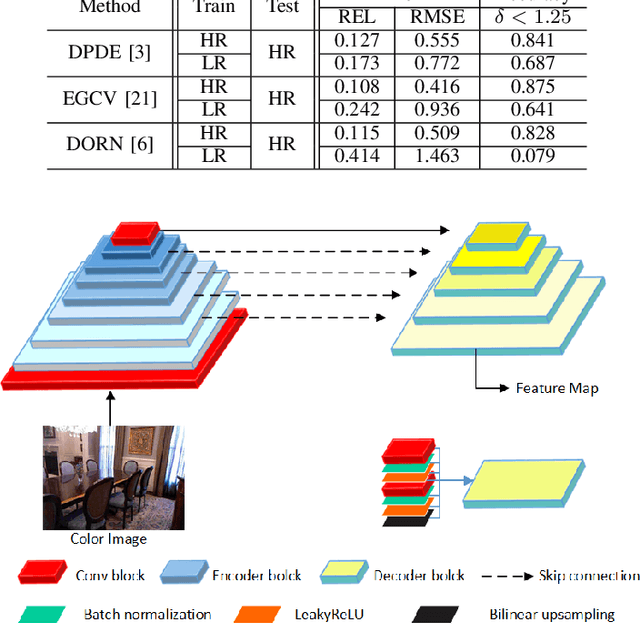
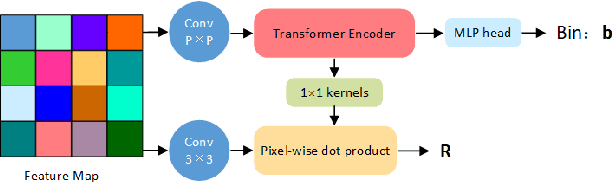
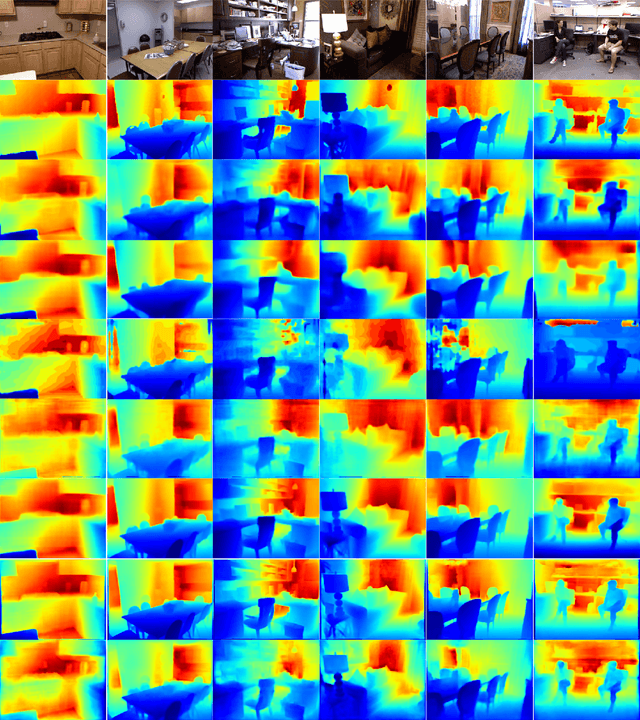
Depth estimation from a single image is an active research topic in computer vision. The most accurate approaches are based on fully supervised learning models, which rely on a large amount of dense and high-resolution (HR) ground-truth depth maps. However, in practice, color images are usually captured with much higher resolution than depth maps, leading to the resolution-mismatched effect. In this paper, we propose a novel weakly-supervised framework to train a monocular depth estimation network to generate HR depth maps with resolution-mismatched supervision, i.e., the inputs are HR color images and the ground-truth are low-resolution (LR) depth maps. The proposed weakly supervised framework is composed of a sharing weight monocular depth estimation network and a depth reconstruction network for distillation. Specifically, for the monocular depth estimation network the input color image is first downsampled to obtain its LR version with the same resolution as the ground-truth depth. Then, both HR and LR color images are fed into the proposed monocular depth estimation network to obtain the corresponding estimated depth maps. We introduce three losses to train the network: 1) reconstruction loss between the estimated LR depth and the ground-truth LR depth; 2) reconstruction loss between the downsampled estimated HR depth and the ground-truth LR depth; 3) consistency loss between the estimated LR depth and the downsampled estimated HR depth. In addition, we design a depth reconstruction network from depth to depth. Through distillation loss, features between two networks maintain the structural consistency in affinity space, and finally improving the estimation network performance. Experimental results demonstrate that our method achieves superior performance than unsupervised and semi-supervised learning based schemes, and is competitive or even better compared to supervised ones.
Learning Scalable $\ell_\infty$-constrained Near-lossless Image Compression via Joint Lossy Image and Residual Compression
Mar 31, 2021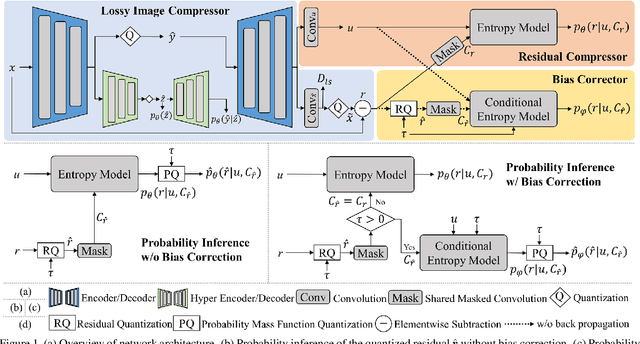
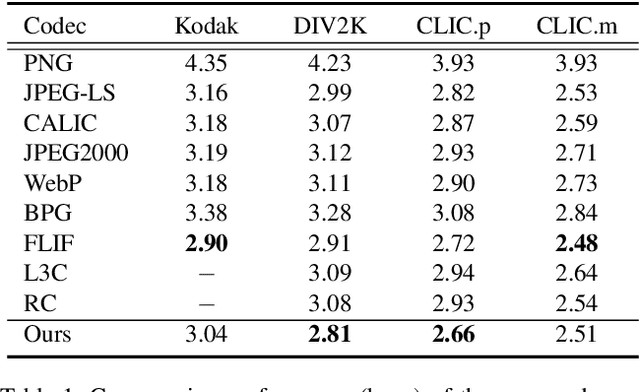
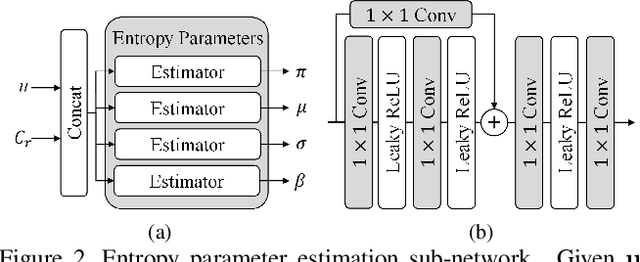
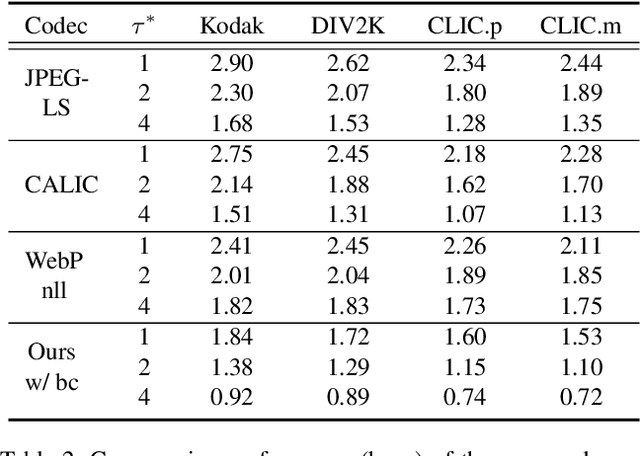
We propose a novel joint lossy image and residual compression framework for learning $\ell_\infty$-constrained near-lossless image compression. Specifically, we obtain a lossy reconstruction of the raw image through lossy image compression and uniformly quantize the corresponding residual to satisfy a given tight $\ell_\infty$ error bound. Suppose that the error bound is zero, i.e., lossless image compression, we formulate the joint optimization problem of compressing both the lossy image and the original residual in terms of variational auto-encoders and solve it with end-to-end training. To achieve scalable compression with the error bound larger than zero, we derive the probability model of the quantized residual by quantizing the learned probability model of the original residual, instead of training multiple networks. We further correct the bias of the derived probability model caused by the context mismatch between training and inference. Finally, the quantized residual is encoded according to the bias-corrected probability model and is concatenated with the bitstream of the compressed lossy image. Experimental results demonstrate that our near-lossless codec achieves the state-of-the-art performance for lossless and near-lossless image compression, and achieves competitive PSNR while much smaller $\ell_\infty$ error compared with lossy image codecs at high bit rates.
FFA-Net: Feature Fusion Attention Network for Single Image Dehazing
Dec 05, 2019
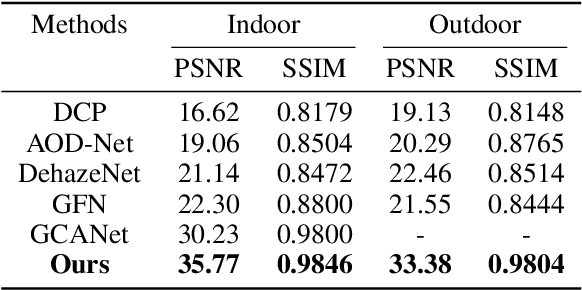
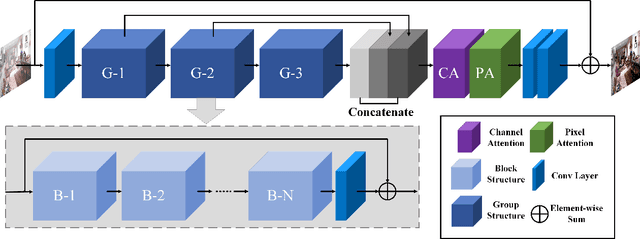
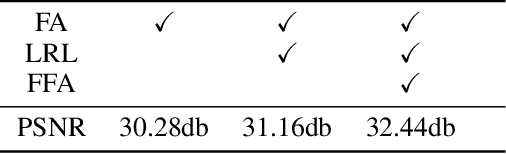
In this paper, we propose an end-to-end feature fusion at-tention network (FFA-Net) to directly restore the haze-free image. The FFA-Net architecture consists of three key components: 1) A novel Feature Attention (FA) module combines Channel Attention with Pixel Attention mechanism, considering that different channel-wise features contain totally different weighted information and haze distribution is uneven on the different image pixels. FA treats different features and pixels unequally, which provides additional flexibility in dealing with different types of information, expanding the representational ability of CNNs. 2) A basic block structure consists of Local Residual Learning and Feature Attention, Local Residual Learning allowing the less important information such as thin haze region or low-frequency to be bypassed through multiple local residual connections, let main network architecture focus on more effective information. 3) An Attention-based different levels Feature Fusion (FFA) structure, the feature weights are adaptively learned from the Feature Attention (FA) module, giving more weight to important features. This structure can also retain the information of shallow layers and pass it into deep layers. The experimental results demonstrate that our proposed FFA-Net surpasses previous state-of-the-art single image dehazing methods by a very large margin both quantitatively and qualitatively, boosting the best published PSNR metric from 30.23db to 36.39db on the SOTS indoor test dataset. Code has been made available at GitHub.
Single Image Blind Deblurring Using Multi-Scale Latent Structure Prior
Jun 11, 2019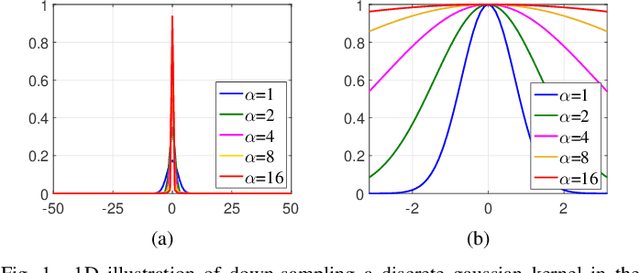


Blind image deblurring is a challenging problem in computer vision, which aims to restore both the blur kernel and the latent sharp image from only a blurry observation. Inspired by the prevalent self-example prior in image super-resolution, in this paper, we observe that a coarse enough image down-sampled from a blurry observation is approximately a low-resolution version of the latent sharp image. We prove this phenomenon theoretically and define the coarse enough image as a latent structure prior of the unknown sharp image. Starting from this prior, we propose to restore sharp images from the coarsest scale to the finest scale on a blurry image pyramid, and progressively update the prior image using the newly restored sharp image. These coarse-to-fine priors are referred to as \textit{Multi-Scale Latent Structures} (MSLS). Leveraging the MSLS prior, our algorithm comprises two phases: 1) we first preliminarily restore sharp images in the coarse scales; 2) we then apply a refinement process in the finest scale to obtain the final deblurred image. In each scale, to achieve lower computational complexity, we alternately perform a sharp image reconstruction with fast local self-example matching, an accelerated kernel estimation with error compensation, and a fast non-blind image deblurring, instead of computing any computationally expensive non-convex priors. We further extend the proposed algorithm to solve more challenging non-uniform blind image deblurring problem. Extensive experiments demonstrate that our algorithm achieves competitive results against the state-of-the-art methods with much faster running speed.
Graph-Based Blind Image Deblurring From a Single Photograph
Feb 22, 2018



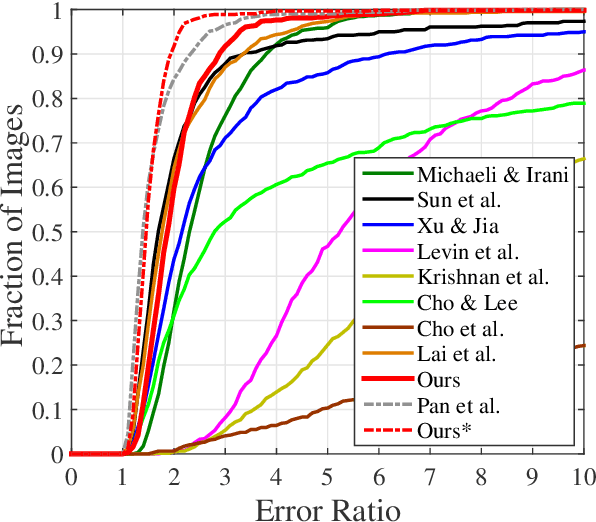
Blind image deblurring, i.e., deblurring without knowledge of the blur kernel, is a highly ill-posed problem. The problem can be solved in two parts: i) estimate a blur kernel from the blurry image, and ii) given estimated blur kernel, de-convolve blurry input to restore the target image. In this paper, we propose a graph-based blind image deblurring algorithm by interpreting an image patch as a signal on a weighted graph. Specifically, we first argue that a skeleton image---a proxy that retains the strong gradients of the target but smooths out the details---can be used to accurately estimate the blur kernel and has a unique bi-modal edge weight distribution. Then, we design a reweighted graph total variation (RGTV) prior that can efficiently promote a bi-modal edge weight distribution given a blurry patch. Further, to analyze RGTV in the graph frequency domain, we introduce a new weight function to represent RGTV as a graph $l_1$-Laplacian regularizer. This leads to a graph spectral filtering interpretation of the prior with desirable properties, including robustness to noise and blur, strong piecewise smooth (PWS) filtering and sharpness promotion. Minimizing a blind image deblurring objective with RGTV results in a non-convex non-differentiable optimization problem. We leverage the new graph spectral interpretation for RGTV to design an efficient algorithm that solves for the skeleton image and the blur kernel alternately. Specifically for Gaussian blur, we propose a further speedup strategy for blind Gaussian deblurring using accelerated graph spectral filtering. Finally, with the computed blur kernel, recent non-blind image deblurring algorithms can be applied to restore the target image. Experimental results demonstrate that our algorithm successfully restores latent sharp images and outperforms state-of-the-art methods quantitatively and qualitatively.
Blind Image Deblurring via Reweighted Graph Total Variation
Dec 24, 2017
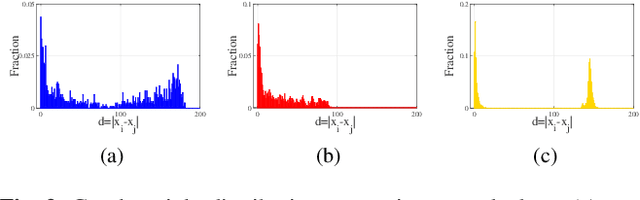
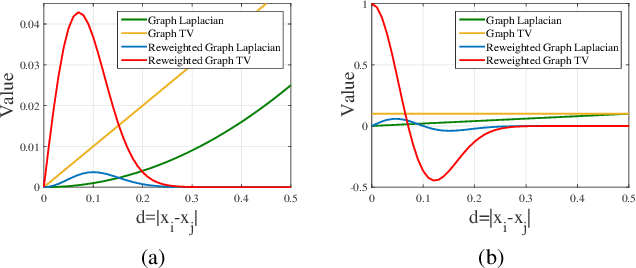

Blind image deblurring, i.e., deblurring without knowledge of the blur kernel, is a highly ill-posed problem. The problem can be solved in two parts: i) estimate a blur kernel from the blurry image, and ii) given estimated blur kernel, de-convolve blurry input to restore the target image. In this paper, by interpreting an image patch as a signal on a weighted graph, we first argue that a skeleton image---a proxy that retains the strong gradients of the target but smooths out the details---can be used to accurately estimate the blur kernel and has a unique bi-modal edge weight distribution. We then design a reweighted graph total variation (RGTV) prior that can efficiently promote bi-modal edge weight distribution given a blurry patch. However, minimizing a blind image deblurring objective with RGTV results in a non-convex non-differentiable optimization problem. We propose a fast algorithm that solves for the skeleton image and the blur kernel alternately. Finally with the computed blur kernel, recent non-blind image deblurring algorithms can be applied to restore the target image. Experimental results show that our algorithm can robustly estimate the blur kernel with large kernel size, and the reconstructed sharp image is competitive against the state-of-the-art methods.