 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAST: Audio Spectrogram Transformer
Apr 06, 2021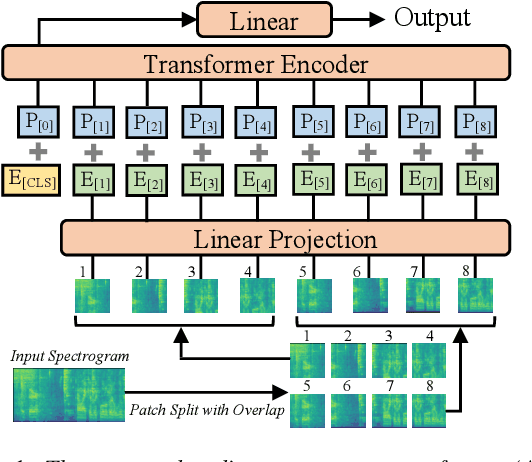
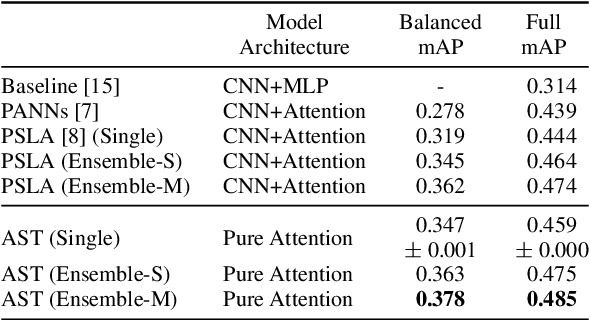
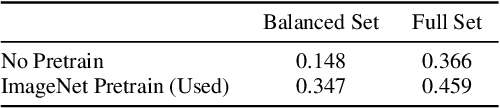
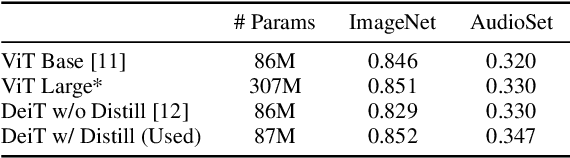
In the past decade, convolutional neural networks (CNNs) have been widely adopted as the main building block for end-to-end audio classification models, which aim to learn a direct mapping from audio spectrograms to corresponding labels. To better capture long-range global context, a recent trend is to add a self-attention mechanism on top of the CNN, forming a CNN-attention hybrid model. However, it is unclear whether the reliance on a CNN is necessary, and if neural networks purely based on attention are sufficient to obtain good performance in audio classification. In this paper, we answer the question by introducing the Audio Spectrogram Transformer (AST), the first convolution-free, purely attention-based model for audio classification. We evaluate AST on various audio classification benchmarks, where it achieves new state-of-the-art results of 0.485 mAP on AudioSet, 95.6% accuracy on ESC-50, and 98.1% accuracy on Speech Commands V2.
PSLA: Improving Audio Event Classification with Pretraining, Sampling, Labeling, and Aggregation
Feb 02, 2021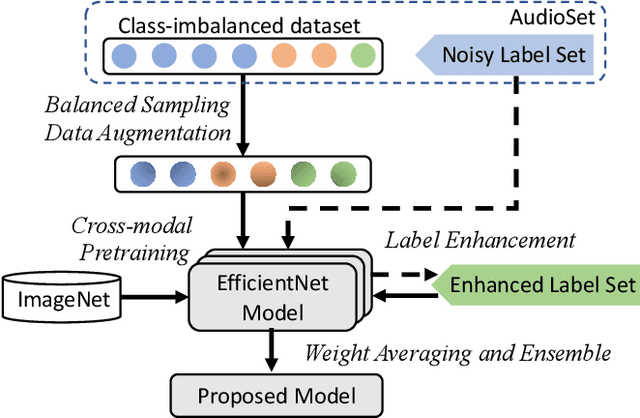
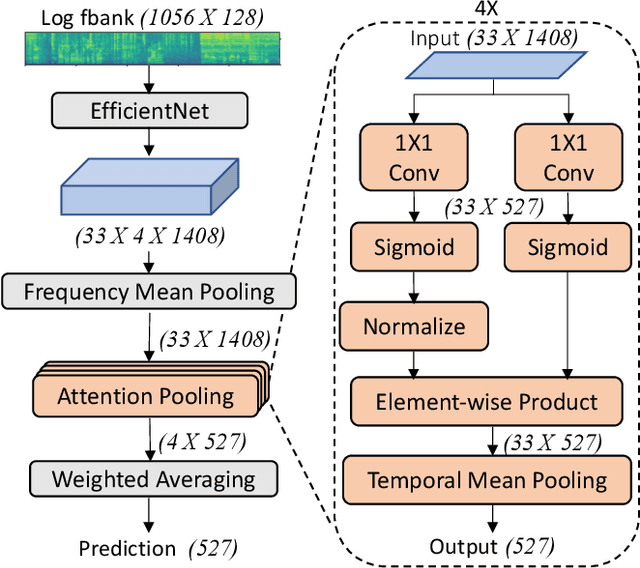
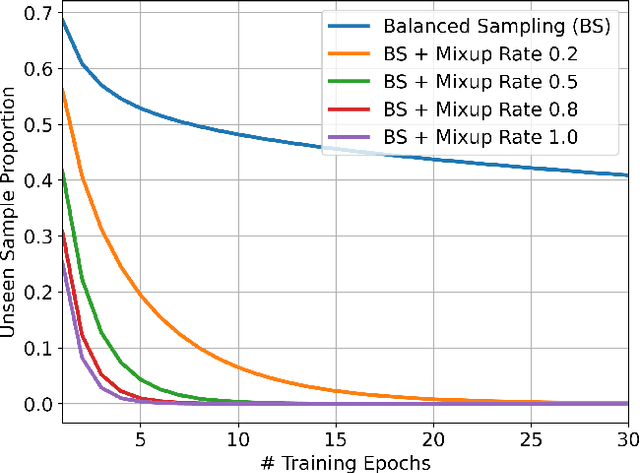
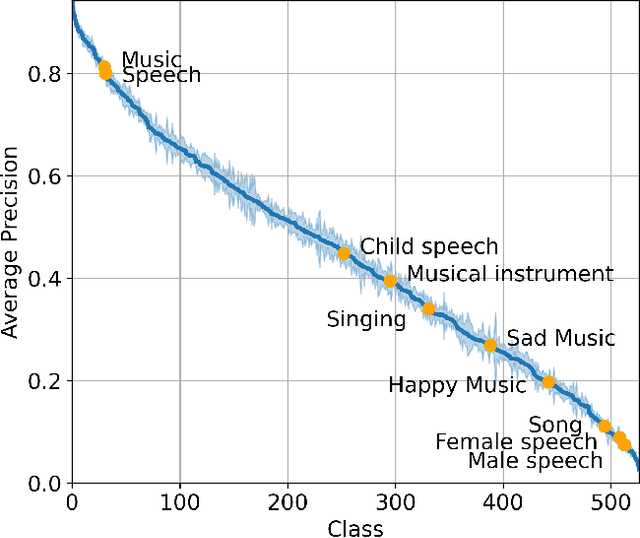
Audio event classification is an active research area and has a wide range of applications. Since the release of AudioSet, great progress has been made in advancing the classification accuracy, which mostly comes from the development of novel model architectures and attention modules. However, we find that appropriate training techniques are equally important for building audio event classification models with AudioSet, but have not received the attention they deserve. To fill the gap, in this work, we present PSLA, a collection of training techniques that can noticeably boost the model accuracy including ImageNet pretraining, balanced sampling, data augmentation, label enhancement, model aggregation and their design choices. By training an EfficientNet with these techniques, we obtain a model that achieves a new state-of-the-art mean average precision (mAP) of 0.474 on AudioSet, outperforming the previous best system of 0.439.
Non-Autoregressive Predictive Coding for Learning Speech Representations from Local Dependencies
Nov 01, 2020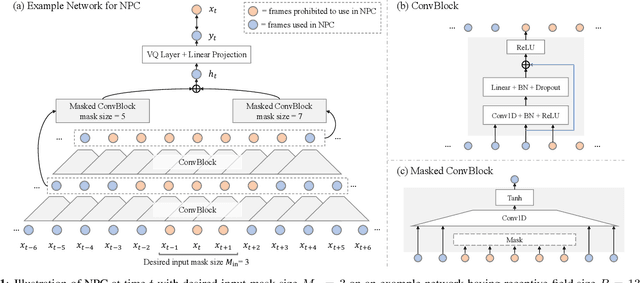
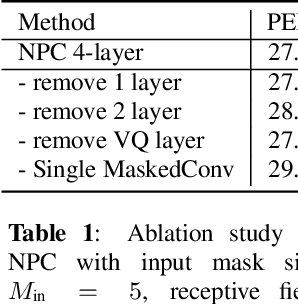
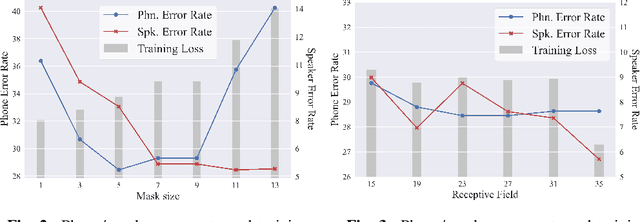
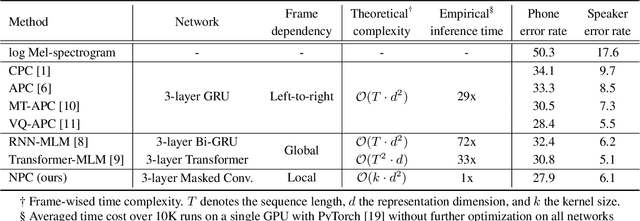
Self-supervised speech representations have been shown to be effective in a variety of speech applications. However, existing representation learning methods generally rely on the autoregressive model and/or observed global dependencies while generating the representation. In this work, we propose Non-Autoregressive Predictive Coding (NPC), a self-supervised method, to learn a speech representation in a non-autoregressive manner by relying only on local dependencies of speech. NPC has a conceptually simple objective and can be implemented easily with the introduced Masked Convolution Blocks. NPC offers a significant speedup for inference since it is parallelizable in time and has a fixed inference time for each time step regardless of the input sequence length. We discuss and verify the effectiveness of NPC by theoretically and empirically comparing it with other methods. We show that the NPC representation is comparable to other methods in speech experiments on phonetic and speaker classification while being more efficient.
Similarity Analysis of Self-Supervised Speech Representations
Oct 22, 2020
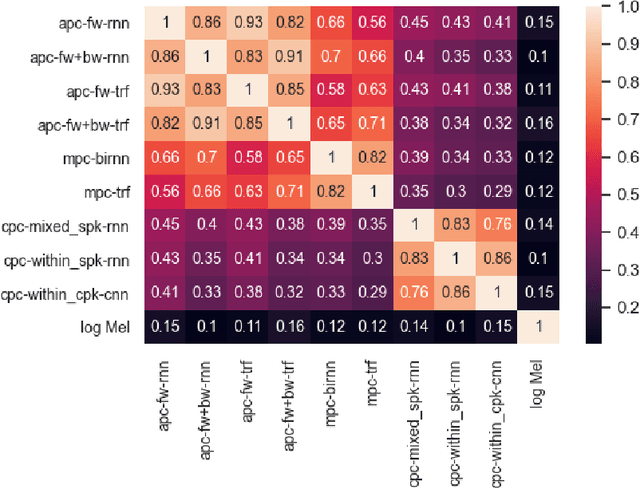
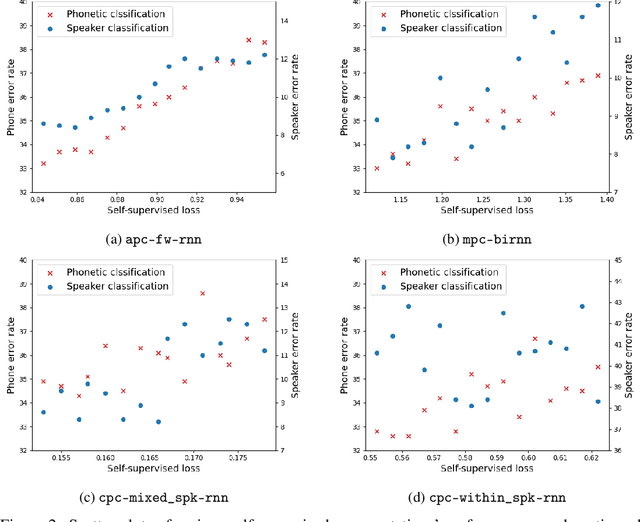
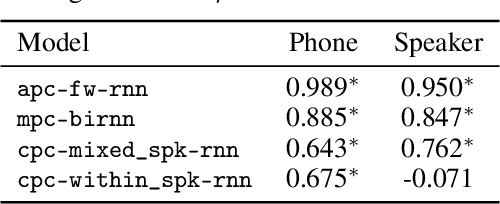
Self-supervised speech representation learning has recently been a prosperous research topic. Many algorithms have been proposed for learning useful representations from large-scale unlabeled data, and their applications to a wide range of speech tasks have also been investigated. However, there has been little research focusing on understanding the properties of existing approaches. In this work, we aim to provide a comparative study of some of the most representative self-supervised algorithms. Specifically, we quantify the similarities between different self-supervised representations using existing similarity measures. We also design probing tasks to study the correlation between the models' pre-training loss and the amount of specific speech information contained in their learned representations. In addition to showing how various self-supervised models behave differently given the same input, our study also finds that the training objective has a higher impact on representation similarity than architectural choices such as building blocks (RNN/Transformer/CNN) and directionality (uni/bidirectional). Our results also suggest that there exists a strong correlation between pre-training loss and downstream performance for some self-supervised algorithms.
Semi-Supervised Speech-Language Joint Pre-Training for Spoken Language Understanding
Oct 05, 2020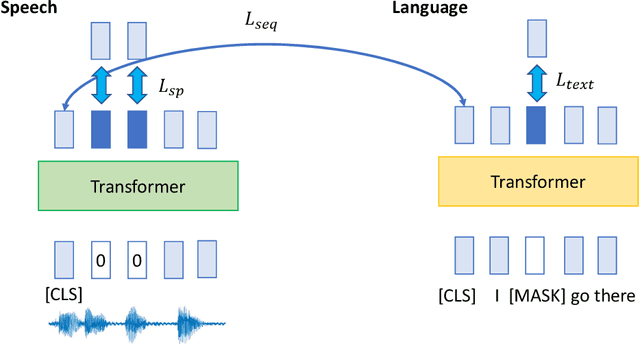
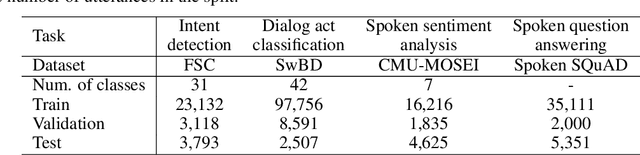

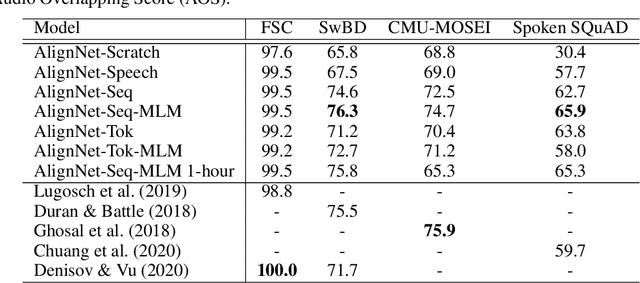
Spoken language understanding (SLU) requires a model to analyze input acoustic signals to understand its linguistic content and make predictions. To boost the models' performance, various pre-training methods have been proposed to utilize large-scale unlabeled text and speech data. However, the inherent disparities between the two modalities necessitate a mutual analysis. In this paper, we propose a novel semi-supervised learning method, AlignNet, to jointly pre-train the speech and language modules. Besides a self-supervised masked language modeling of the two individual modules, AlignNet aligns representations from paired speech and transcripts in a shared latent semantic space. Thus, during fine-tuning, the speech module alone can produce representations carrying both acoustic information and contextual semantic knowledge. Experimental results verify the effectiveness of our approach on various SLU tasks. For example, AlignNet improves the previous state-of-the-art accuracy on the Spoken SQuAD dataset by 6.2%.
Vector-Quantized Autoregressive Predictive Coding
May 17, 2020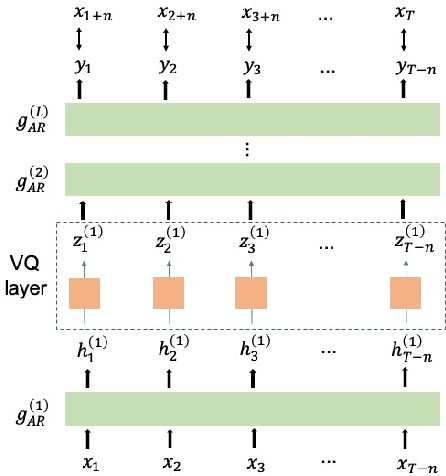
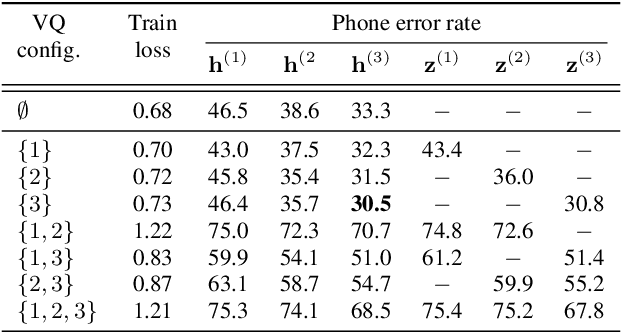
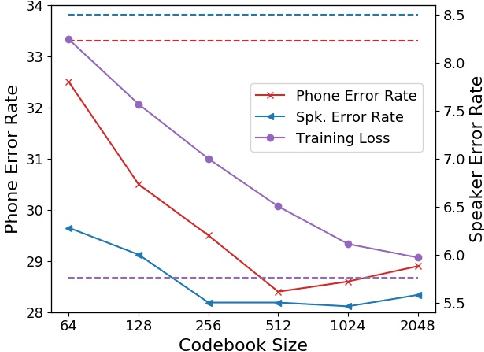
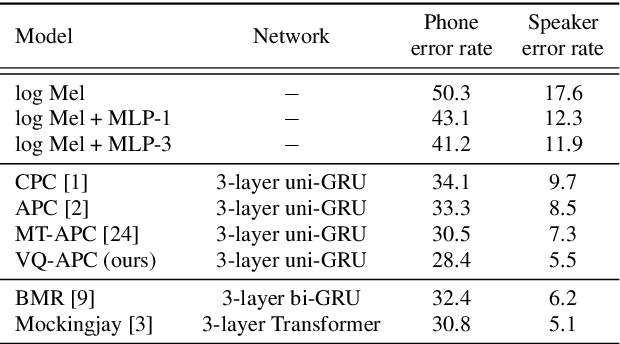
Autoregressive Predictive Coding (APC), as a self-supervised objective, has enjoyed success in learning representations from large amounts of unlabeled data, and the learned representations are rich for many downstream tasks. However, the connection between low self-supervised loss and strong performance in downstream tasks remains unclear. In this work, we propose Vector-Quantized Autoregressive Predictive Coding (VQ-APC), a novel model that produces quantized representations, allowing us to explicitly control the amount of information encoded in the representations. By studying a sequence of increasingly limited models, we reveal the constituents of the learned representations. In particular, we confirm the presence of information with probing tasks, while showing the absence of information with mutual information, uncovering the model's preference in preserving speech information as its capacity becomes constrained. We find that there exists a point where phonetic and speaker information are amplified to maximize a self-supervised objective. As a byproduct, the learned codes for a particular model capacity correspond well to English phones.
Improved Speech Representations with Multi-Target Autoregressive Predictive Coding
Apr 11, 2020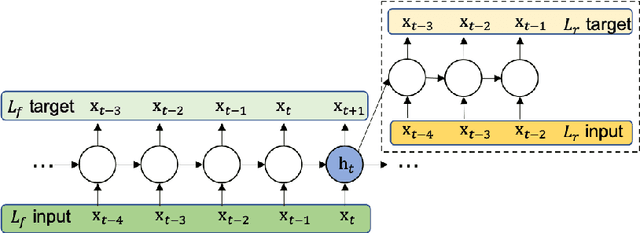
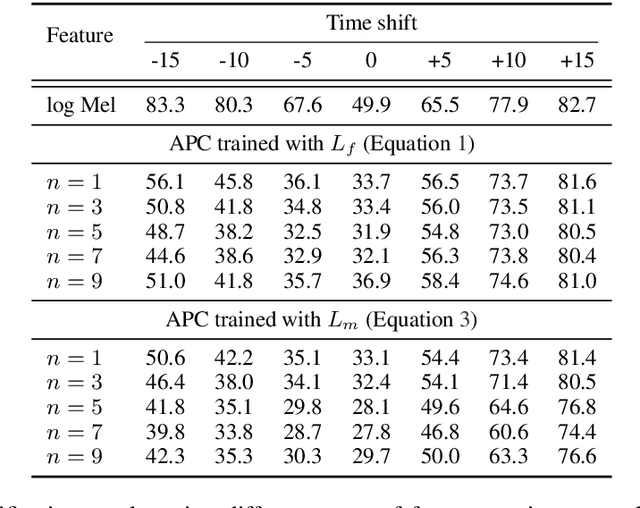
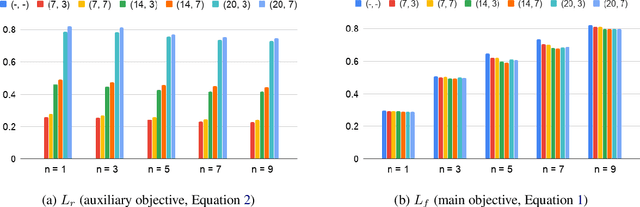

Training objectives based on predictive coding have recently been shown to be very effective at learning meaningful representations from unlabeled speech. One example is Autoregressive Predictive Coding (Chung et al., 2019), which trains an autoregressive RNN to generate an unseen future frame given a context such as recent past frames. The basic hypothesis of these approaches is that hidden states that can accurately predict future frames are a useful representation for many downstream tasks. In this paper we extend this hypothesis and aim to enrich the information encoded in the hidden states by training the model to make more accurate future predictions. We propose an auxiliary objective that serves as a regularization to improve generalization of the future frame prediction task. Experimental results on phonetic classification, speech recognition, and speech translation not only support the hypothesis, but also demonstrate the effectiveness of our approach in learning representations that contain richer phonetic content.
Clinical Text Summarization with Syntax-Based Negation and Semantic Concept Identification
Feb 29, 2020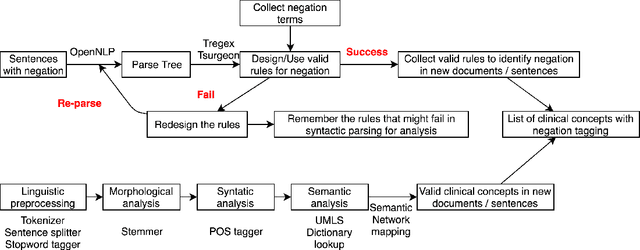


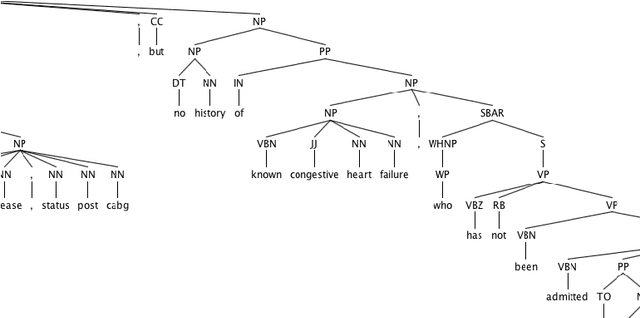
In the era of clinical information explosion, a good strategy for clinical text summarization is helpful to improve the clinical workflow. The ideal summarization strategy can preserve important information in the informative but less organized, ill-structured clinical narrative texts. Instead of using pure statistical learning approaches, which are difficult to interpret and explain, we utilized knowledge of computational linguistics with human experts-curated biomedical knowledge base to achieve the interpretable and meaningful clinical text summarization. Our research objective is to use the biomedical ontology with semantic information, and take the advantage from the language hierarchical structure, the constituency tree, in order to identify the correct clinical concepts and the corresponding negation information, which is critical for summarizing clinical concepts from narrative text. We achieved the clinically acceptable performance for both negation detection and concept identification, and the clinical concepts with common negated patterns can be identified and negated by the proposed method.
Generative Pre-Training for Speech with Autoregressive Predictive Coding
Oct 23, 2019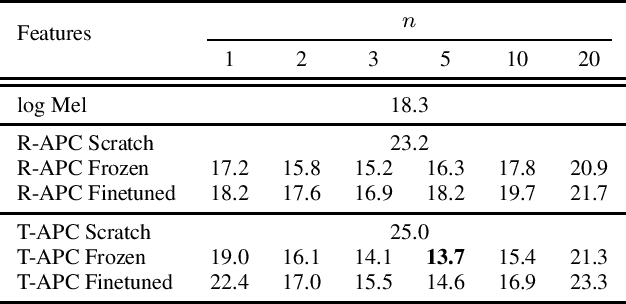
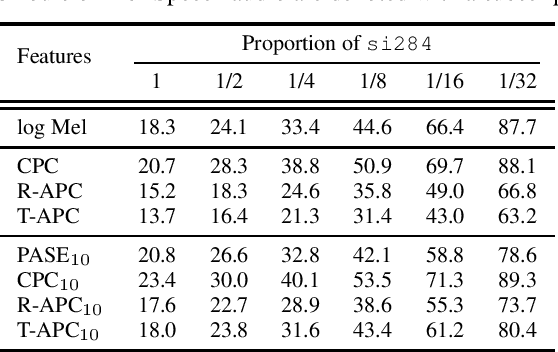
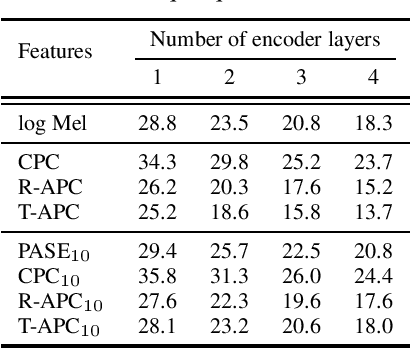
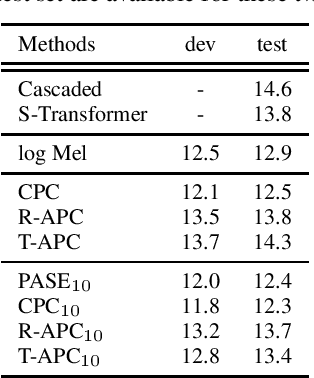
Learning meaningful and general representations from unannotated speech that are applicable to a wide range of tasks remains challenging. In this paper we propose to use autoregressive predictive coding (APC), a recently proposed self-supervised objective, as a generative pre-training approach for learning meaningful, non-specific, and transferable speech representations. We pre-train APC on large-scale unlabeled data and conduct transfer learning experiments on three speech applications that require different information about speech characteristics to perform well: speech recognition, speech translation, and speaker identification. Extensive experiments show that APC not only outperforms surface features (e.g., log Mel spectrograms) and other popular representation learning methods on all three tasks, but is also effective at reducing downstream labeled data size and model parameters. We also investigate the use of Transformers for modeling APC and find it superior to RNNs.
SummAE: Zero-Shot Abstractive Text Summarization using Length-Agnostic Auto-Encoders
Oct 02, 2019
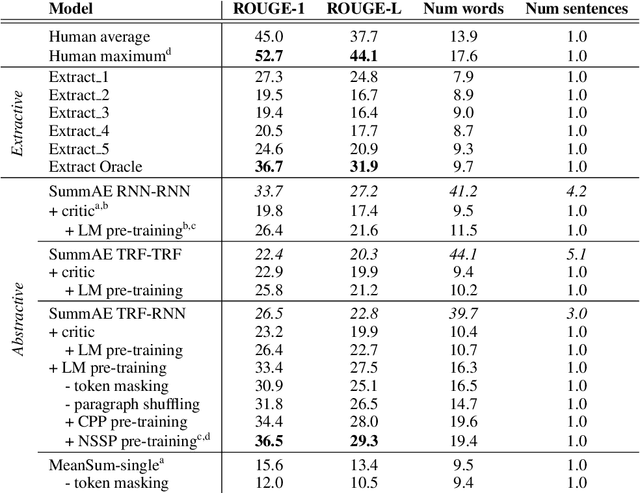
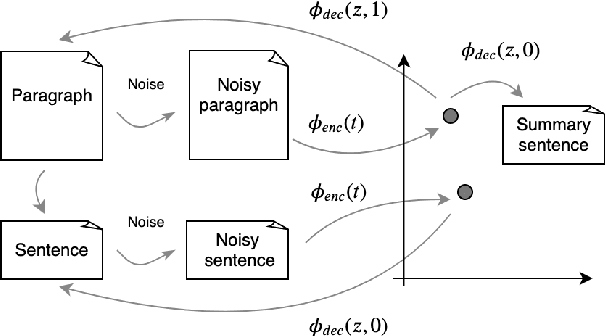
We propose an end-to-end neural model for zero-shot abstractive text summarization of paragraphs, and introduce a benchmark task, ROCSumm, based on ROCStories, a subset for which we collected human summaries. In this task, five-sentence stories (paragraphs) are summarized with one sentence, using human summaries only for evaluation. We show results for extractive and human baselines to demonstrate a large abstractive gap in performance. Our model, SummAE, consists of a denoising auto-encoder that embeds sentences and paragraphs in a common space, from which either can be decoded. Summaries for paragraphs are generated by decoding a sentence from the paragraph representations. We find that traditional sequence-to-sequence auto-encoders fail to produce good summaries and describe how specific architectural choices and pre-training techniques can significantly improve performance, outperforming extractive baselines. The data, training, evaluation code, and best model weights are open-sourced.