 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge1st Place Solution to ECCV 2022 Challenge on Out of Vocabulary Scene Text Understanding: Cropped Word Recognition
Aug 04, 2022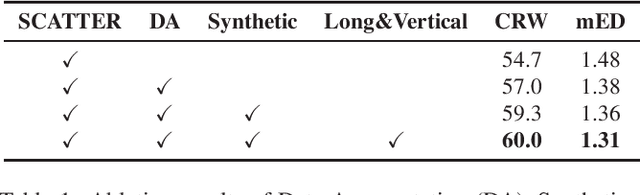


This report presents our winner solution to ECCV 2022 challenge on Out-of-Vocabulary Scene Text Understanding (OOV-ST) : Cropped Word Recognition. This challenge is held in the context of ECCV 2022 workshop on Text in Everything (TiE), which aims to extract out-of-vocabulary words from natural scene images. In the competition, we first pre-train SCATTER on the synthetic datasets, then fine-tune the model on the training set with data augmentations. Meanwhile, two additional models are trained specifically for long and vertical texts. Finally, we combine the output from different models with different layers, different backbones, and different seeds as the final results. Our solution achieves an overall word accuracy of 69.73% when considering both in-vocabulary and out-of-vocabulary words.
Language Matters: A Weakly Supervised Pre-training Approach for Scene Text Detection and Spotting
Mar 08, 2022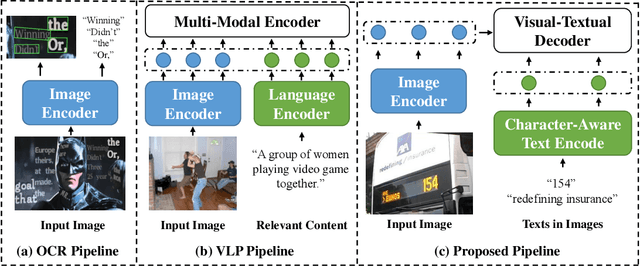
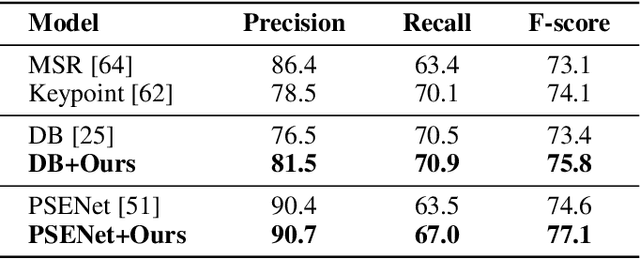
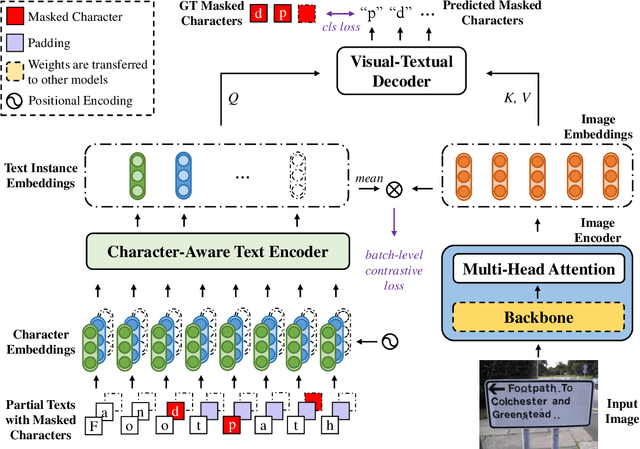

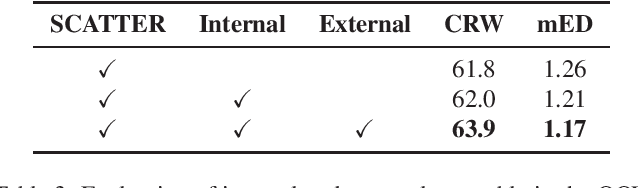
Recently, Vision-Language Pre-training (VLP) techniques have greatly benefited various vision-language tasks by jointly learning visual and textual representations, which intuitively helps in Optical Character Recognition (OCR) tasks due to the rich visual and textual information in scene text images. However, these methods cannot well cope with OCR tasks because of the difficulty in both instance-level text encoding and image-text pair acquisition (i.e. images and captured texts in them). This paper presents a weakly supervised pre-training method that can acquire effective scene text representations by jointly learning and aligning visual and textual information. Our network consists of an image encoder and a character-aware text encoder that extract visual and textual features, respectively, as well as a visual-textual decoder that models the interaction among textual and visual features for learning effective scene text representations. With the learning of textual features, the pre-trained model can attend texts in images well with character awareness. Besides, these designs enable the learning from weakly annotated texts (i.e. partial texts in images without text bounding boxes) which mitigates the data annotation constraint greatly. Experiments over the weakly annotated images in ICDAR2019-LSVT show that our pre-trained model improves F-score by +2.5% and +4.8% while transferring its weights to other text detection and spotting networks, respectively. In addition, the proposed method outperforms existing pre-training techniques consistently across multiple public datasets (e.g., +3.2% and +1.3% for Total-Text and CTW1500).
Network-Aware 5G Edge Computing for Object Detection: Augmenting Wearables to "See'' More, Farther and Faster
Dec 25, 2021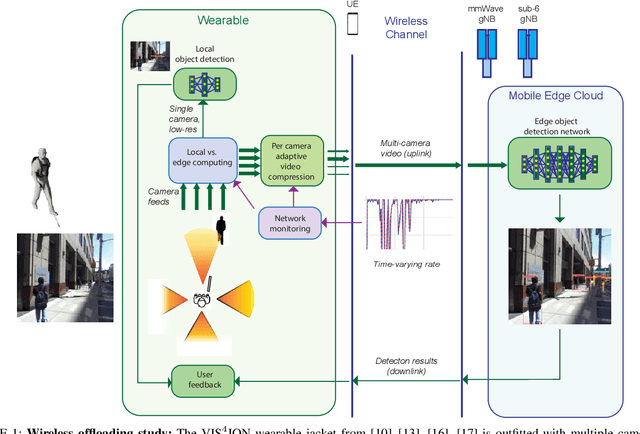
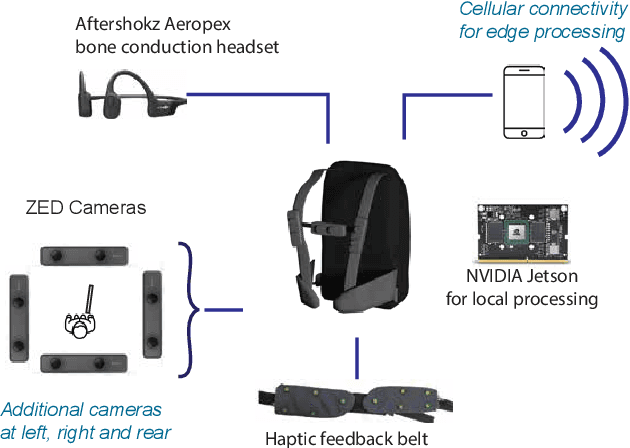
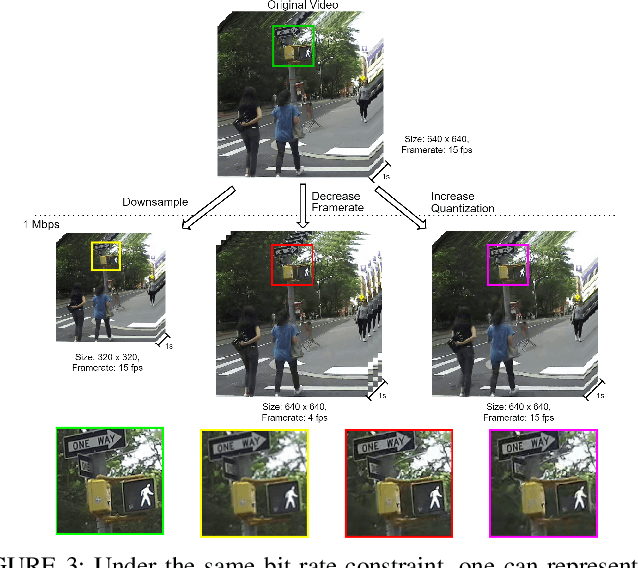
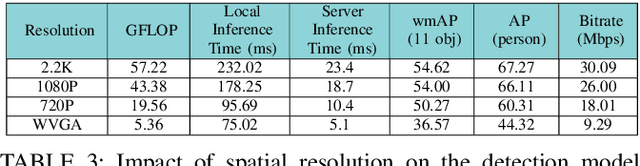
Advanced wearable devices are increasingly incorporating high-resolution multi-camera systems. As state-of-the-art neural networks for processing the resulting image data are computationally demanding, there has been growing interest in leveraging fifth generation (5G) wireless connectivity and mobile edge computing for offloading this processing to the cloud. To assess this possibility, this paper presents a detailed simulation and evaluation of 5G wireless offloading for object detection within a powerful, new smart wearable called VIS4ION, for the Blind-and-Visually Impaired (BVI). The current VIS4ION system is an instrumented book-bag with high-resolution cameras, vision processing and haptic and audio feedback. The paper considers uploading the camera data to a mobile edge cloud to perform real-time object detection and transmitting the detection results back to the wearable. To determine the video requirements, the paper evaluates the impact of video bit rate and resolution on object detection accuracy and range. A new street scene dataset with labeled objects relevant to BVI navigation is leveraged for analysis. The vision evaluation is combined with a detailed full-stack wireless network simulation to determine the distribution of throughputs and delays with real navigation paths and ray-tracing from new high-resolution 3D models in an urban environment. For comparison, the wireless simulation considers both a standard 4G-Long Term Evolution (LTE) carrier and high-rate 5G millimeter-wave (mmWave) carrier. The work thus provides a thorough and realistic assessment of edge computing with mmWave connectivity in an application with both high bandwidth and low latency requirements.
Meta-Learning 3D Shape Segmentation Functions
Oct 08, 2021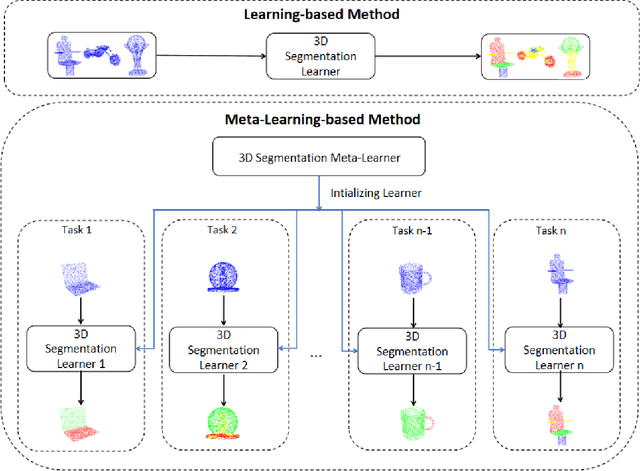

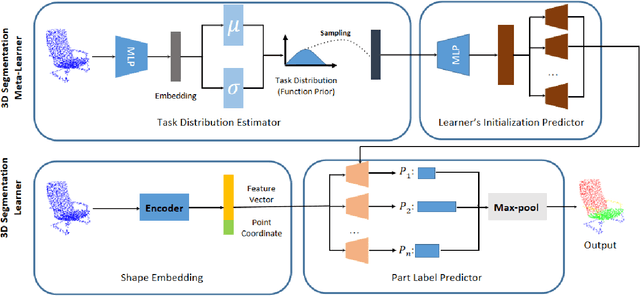
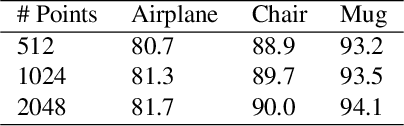
Learning robust 3D shape segmentation functions with deep neural networks has emerged as a powerful paradigm, offering promising performance in producing a consistent part segmentation of each 3D shape. Generalizing across 3D shape segmentation functions requires robust learning of priors over the respective function space and enables consistent part segmentation of shapes in presence of significant 3D structure variations. Existing generalization methods rely on extensive training of 3D shape segmentation functions on large-scale labeled datasets. In this paper, we proposed to formalize the learning of a 3D shape segmentation function space as a meta-learning problem, aiming to predict a 3D segmentation model that can be quickly adapted to new shapes with no or limited training data. More specifically, we define each task as unsupervised learning of shape-conditioned 3D segmentation function which takes as input points in 3D space and predicts the part-segment labels. The 3D segmentation function is trained by a self-supervised 3D shape reconstruction loss without the need for part labels. Also, we introduce an auxiliary deep neural network as a meta-learner which takes as input a 3D shape and predicts the prior over the respective 3D segmentation function space. We show in experiments that our meta-learning approach, denoted as Meta-3DSeg, leads to improvements on unsupervised 3D shape segmentation over the conventional designs of deep neural networks for 3D shape segmentation functions.
3D Meta-Segmentation Neural Network
Oct 08, 2021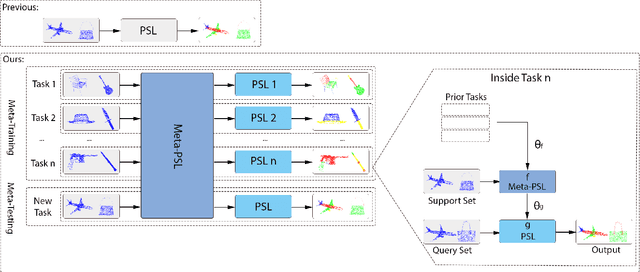

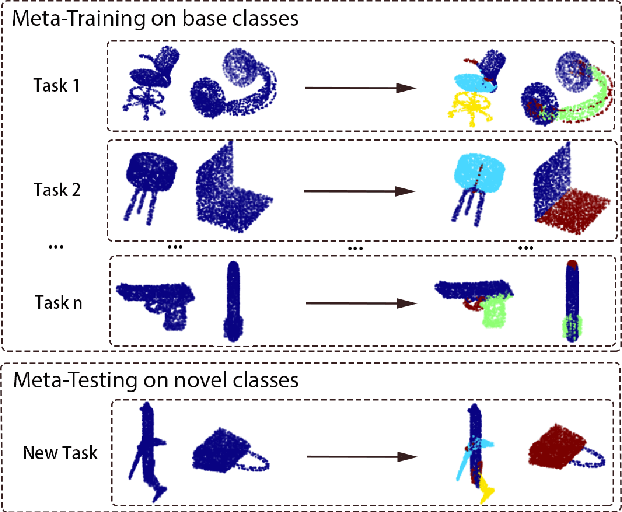
Though deep learning methods have shown great success in 3D point cloud part segmentation, they generally rely on a large volume of labeled training data, which makes the model suffer from unsatisfied generalization abilities to unseen classes with limited data. To address this problem, we present a novel meta-learning strategy that regards the 3D shape segmentation function as a task. By training over a number of 3D part segmentation tasks, our method is capable to learn the prior over the respective 3D segmentation function space which leads to an optimal model that is rapidly adapting to new part segmentation tasks. To implement our meta-learning strategy, we propose two novel modules: meta part segmentation learner and part segmentation learner. During the training process, the part segmentation learner is trained to complete a specific part segmentation task in the few-shot scenario. In the meantime, the meta part segmentation learner is trained to capture the prior from multiple similar part segmentation tasks. Based on the learned information of task distribution, our meta part segmentation learner is able to dynamically update the part segmentation learner with optimal parameters which enable our part segmentation learner to rapidly adapt and have great generalization ability on new part segmentation tasks. We demonstrate that our model achieves superior part segmentation performance with the few-shot setting on the widely used dataset: ShapeNet.
RAR: Region-Aware Point Cloud Registration
Oct 07, 2021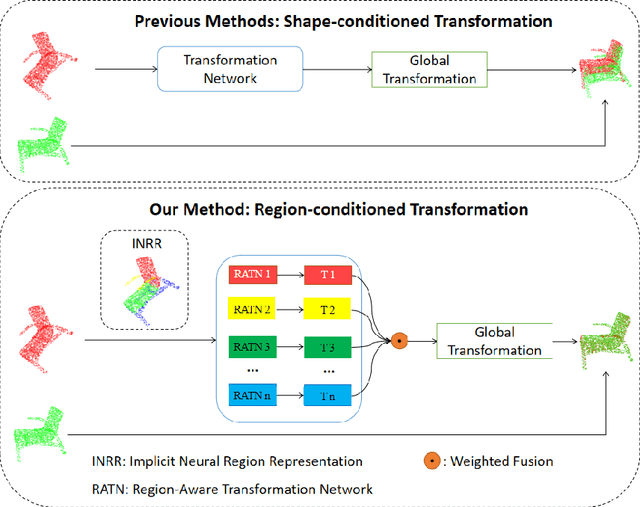

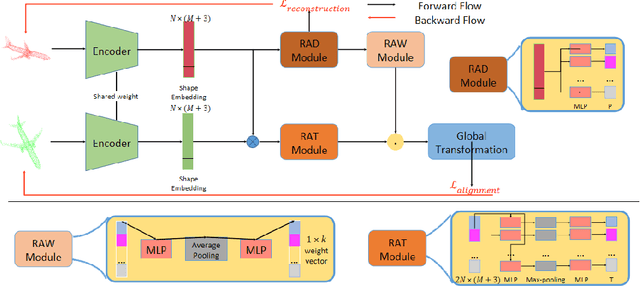
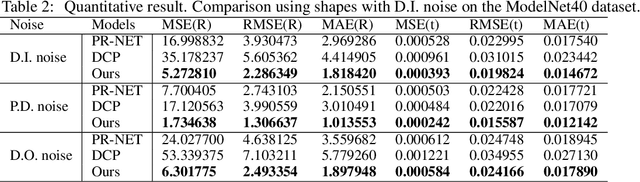
This paper concerns the research problem of point cloud registration to find the rigid transformation to optimally align the source point set with the target one. Learning robust point cloud registration models with deep neural networks has emerged as a powerful paradigm, offering promising performance in predicting the global geometric transformation for a pair of point sets. Existing methods firstly leverage an encoder to regress a latent shape embedding, which is then decoded into a shape-conditioned transformation via concatenation-based conditioning. However, different regions of a 3D shape vary in their geometric structures which makes it more sense that we have a region-conditioned transformation instead of the shape-conditioned one. In this paper we present a \underline{R}egion-\underline{A}ware point cloud \underline{R}egistration, denoted as RAR, to predict transformation for pairwise point sets in the self-supervised learning fashion. More specifically, we develop a novel region-aware decoder (RAD) module that is formed with an implicit neural region representation parameterized by neural networks. The implicit neural region representation is learned with a self-supervised 3D shape reconstruction loss without the need for region labels. Consequently, the region-aware decoder (RAD) module guides the training of the region-aware transformation (RAT) module and region-aware weight (RAW) module, which predict the transforms and weights for different regions respectively. The global geometric transformation from source point set to target one is then formed by the weighted fusion of region-aware transforms. Compared to the state-of-the-art approaches, our experiments show that our RAR achieves superior registration performance over various benchmark datasets (e.g. ModelNet40).
3D Meta-Registration: Learning to Learn Registration of 3D Point Clouds
Oct 22, 2020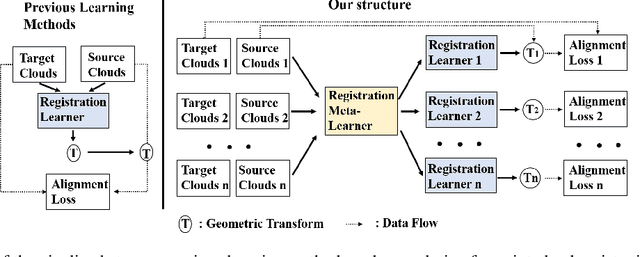
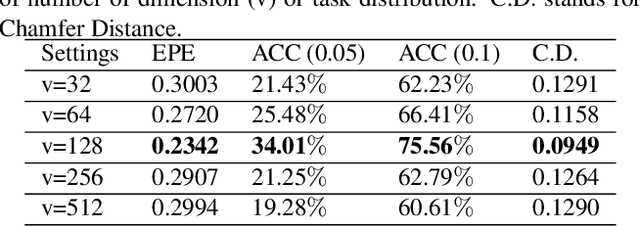
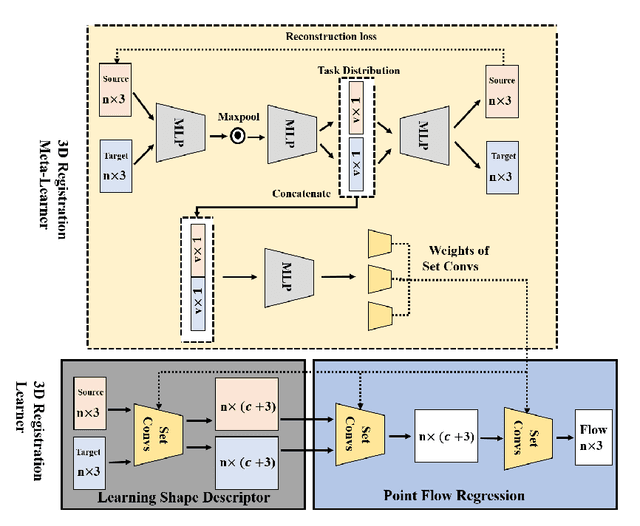
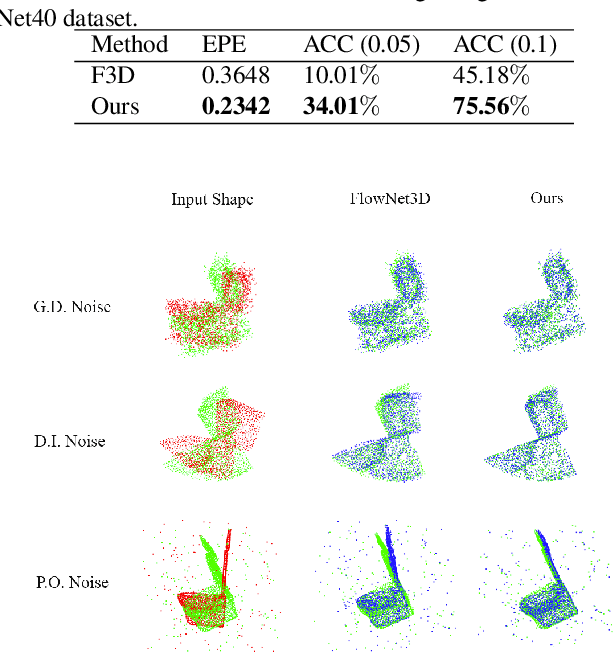
Deep learning-based point cloud registration models are often generalized from extensive training over a large volume of data to learn the ability to predict the desired geometric transformation to register 3D point clouds. In this paper, we propose a meta-learning based 3D registration model, named 3D Meta-Registration, that is capable of rapidly adapting and well generalizing to new 3D registration tasks for unseen 3D point clouds. Our 3D Meta-Registration gains a competitive advantage by training over a variety of 3D registration tasks, which leads to an optimized model for the best performance on the distribution of registration tasks including potentially unseen tasks. Specifically, the proposed 3D Meta-Registration model consists of two modules: 3D registration learner and 3D registration meta-learner. During the training, the 3D registration learner is trained to complete a specific registration task aiming to determine the desired geometric transformation that aligns the source point cloud with the target one. In the meantime, the 3D registration meta-learner is trained to provide the optimal parameters to update the 3D registration learner based on the learned task distribution. After training, the 3D registration meta-learner, which is learned with the optimized coverage of distribution of 3D registration tasks, is able to dynamically update 3D registration learners with desired parameters to rapidly adapt to new registration tasks. We tested our model on synthesized dataset ModelNet and FlyingThings3D, as well as real-world dataset KITTI. Experimental results demonstrate that 3D Meta-Registration achieves superior performance over other previous techniques (e.g. FlowNet3D).
Inductive Link Prediction for Nodes Having Only Attribute Information
Jul 16, 2020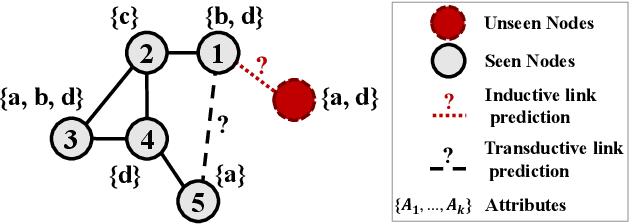
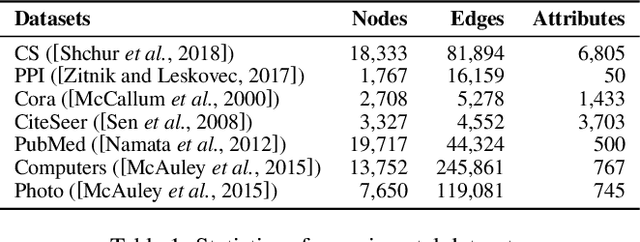
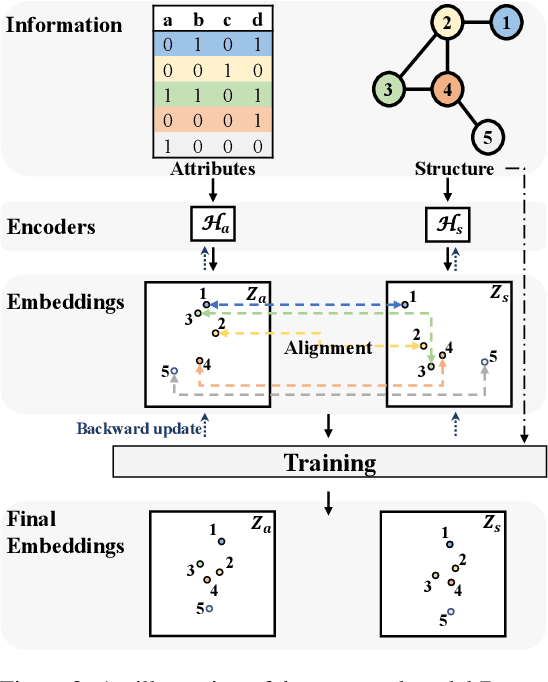
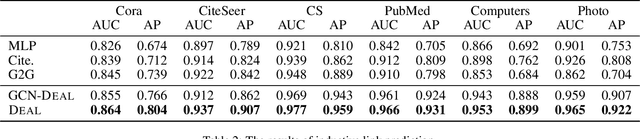
Predicting the link between two nodes is a fundamental problem for graph data analytics. In attributed graphs, both the structure and attribute information can be utilized for link prediction. Most existing studies focus on transductive link prediction where both nodes are already in the graph. However, many real-world applications require inductive prediction for new nodes having only attribute information. It is more challenging since the new nodes do not have structure information and cannot be seen during the model training. To solve this problem, we propose a model called DEAL, which consists of three components: two node embedding encoders and one alignment mechanism. The two encoders aim to output the attribute-oriented node embedding and the structure-oriented node embedding, and the alignment mechanism aligns the two types of embeddings to build the connections between the attributes and links. Our model DEAL is versatile in the sense that it works for both inductive and transductive link prediction. Extensive experiments on several benchmark datasets show that our proposed model significantly outperforms existing inductive link prediction methods, and also outperforms the state-of-the-art methods on transductive link prediction.
Explainable Unsupervised Change-point Detection via Graph Neural Networks
Apr 24, 2020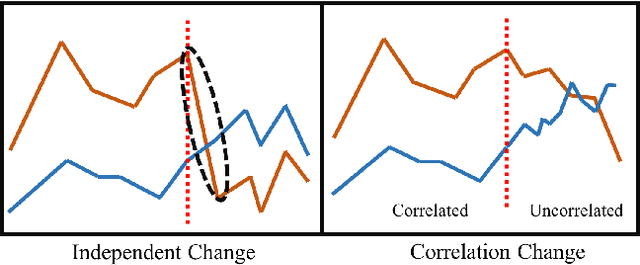
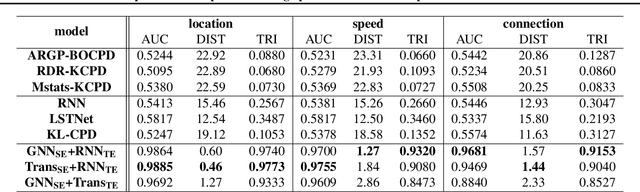
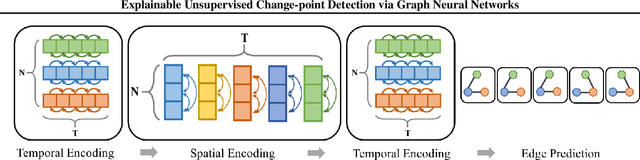
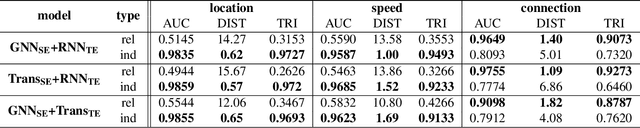
Change-point detection (CPD) aims at detecting the abrupt property changes lying behind time series data. The property changes in a multivariate time series often result from highly entangled reasons, ranging from independent changes of variables to correlation changes between variables. Learning to uncover the reasons behind the changes in an unsupervised setting is a new and challenging task. Previous CPD methods usually detect change-points by a divergence estimation of statistical features, without delving into the reasons behind the detected changes. In this paper, we propose a correlation-aware dynamics model which separately predicts the correlation change and independent change by incorporating graph neural networks into the encoder-decoder framework. Through experiments on synthetic and real-world datasets, we demonstrate the enhanced performance of our model on the CPD tasks as well as its ability to interpret the nature and degree of the predicted changes.
Exploiting Sentence Embedding for Medical Question Answering
Nov 15, 2018
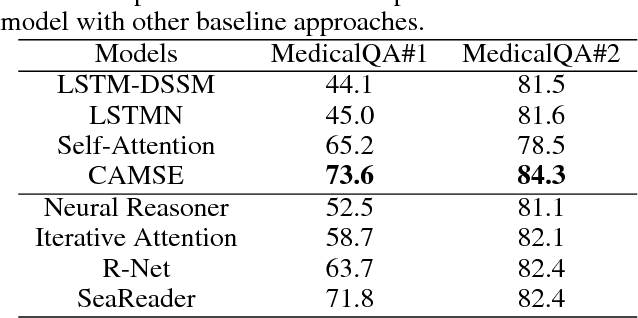


Despite the great success of word embedding, sentence embedding remains a not-well-solved problem. In this paper, we present a supervised learning framework to exploit sentence embedding for the medical question answering task. The learning framework consists of two main parts: 1) a sentence embedding producing module, and 2) a scoring module. The former is developed with contextual self-attention and multi-scale techniques to encode a sentence into an embedding tensor. This module is shortly called Contextual self-Attention Multi-scale Sentence Embedding (CAMSE). The latter employs two scoring strategies: Semantic Matching Scoring (SMS) and Semantic Association Scoring (SAS). SMS measures similarity while SAS captures association between sentence pairs: a medical question concatenated with a candidate choice, and a piece of corresponding supportive evidence. The proposed framework is examined by two Medical Question Answering(MedicalQA) datasets which are collected from real-world applications: medical exam and clinical diagnosis based on electronic medical records (EMR). The comparison results show that our proposed framework achieved significant improvements compared to competitive baseline approaches. Additionally, a series of controlled experiments are also conducted to illustrate that the multi-scale strategy and the contextual self-attention layer play important roles for producing effective sentence embedding, and the two kinds of scoring strategies are highly complementary to each other for question answering problems.