 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbedded Feature Similarity Optimization with Specific Parameter Initialization for 2D/3D Registration
May 11, 2023



We present a novel deep learning-based framework: Embedded Feature Similarity Optimization with Specific Parameter Initialization (SOPI) for 2D/3D registration which is a most challenging problem due to the difficulty such as dimensional mismatch, heavy computation load and lack of golden evaluating standard. The framework we designed includes a parameter specification module to efficiently choose initialization pose parameter and a fine-registration network to align images. The proposed framework takes extracting multi-scale features into consideration using a novel composite connection encoder with special training techniques. The method is compared with both learning-based methods and optimization-based methods to further evaluate the performance. Our experiments demonstrate that the method in this paper has improved the registration performance, and thereby outperforms the existing methods in terms of accuracy and running time. We also show the potential of the proposed method as an initial pose estimator.
XMorpher: Full Transformer for Deformable Medical Image Registration via Cross Attention
Jun 15, 2022
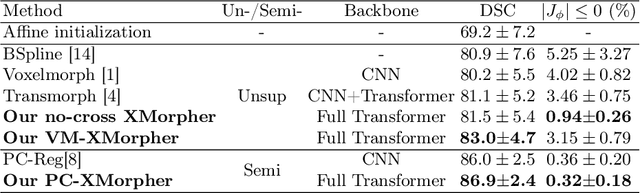
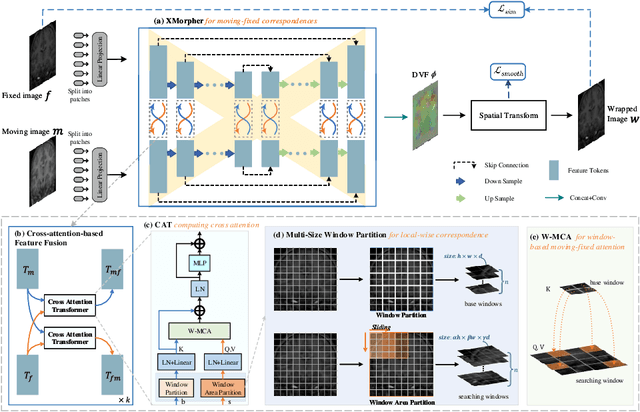
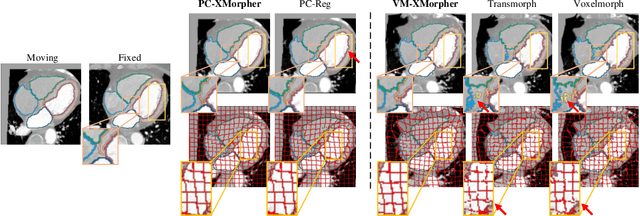
An effective backbone network is important to deep learning-based Deformable Medical Image Registration (DMIR), because it extracts and matches the features between two images to discover the mutual correspondence for fine registration. However, the existing deep networks focus on single image situation and are limited in registration task which is performed on paired images. Therefore, we advance a novel backbone network, XMorpher, for the effective corresponding feature representation in DMIR. 1) It proposes a novel full transformer architecture including dual parallel feature extraction networks which exchange information through cross attention, thus discovering multi-level semantic correspondence while extracting respective features gradually for final effective registration. 2) It advances the Cross Attention Transformer (CAT) blocks to establish the attention mechanism between images which is able to find the correspondence automatically and prompts the features to fuse efficiently in the network. 3) It constrains the attention computation between base windows and searching windows with different sizes, and thus focuses on the local transformation of deformable registration and enhances the computing efficiency at the same time. Without any bells and whistles, our XMorpher gives Voxelmorph 2.8% improvement on DSC , demonstrating its effective representation of the features from the paired images in DMIR. We believe that our XMorpher has great application potential in more paired medical images. Our XMorpher is open on https://github.com/Solemoon/XMorpher
Speech Denoising Using Only Single Noisy Audio Samples
Oct 30, 2021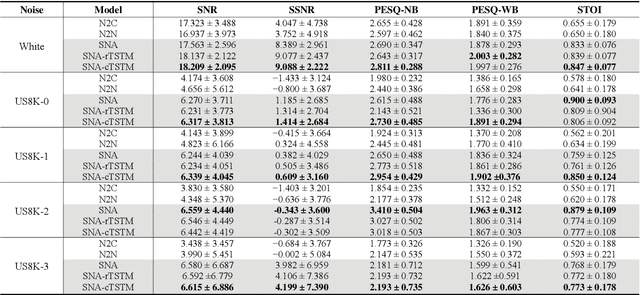
In this paper, we propose a novel Single Noisy Audio De-noising Framework (SNA-DF) for speech denoising using only single noisy audio samples, which overcomes the limi-tation of constructing either noisy-clean training pairs or multiple independent noisy audio samples. The proposed SNA-DF contains two modules: training audio pairs gener-ated module and audio denoising module. The first module adopts a random audio sub-sampler on single noisy audio samples for the generation of training audio pairs. The sub-sampled training audio pairs are then fed into the audio denoising module, which employs a deep complex U-Net incorporating a complex two-stage transformer (cTSTM) to extract both magnitude and phase information for taking full advantage of the complex features of single noisy au-dios. Experimental results show that the proposed SNA-DF not only eliminates the high dependence on clean targets of traditional audio denoising methods, but also outperforms the methods using multiple noisy audio samples.
CPNet: Cycle Prototype Network for Weakly-supervised 3D Renal Compartments Segmentation on CT Images
Aug 15, 2021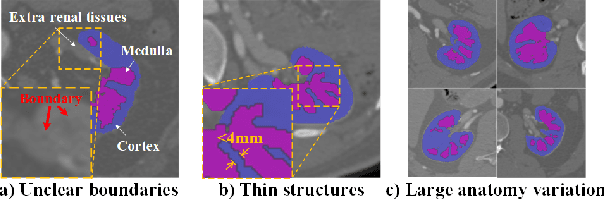
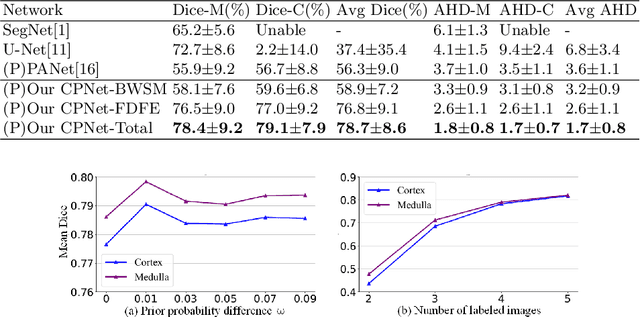
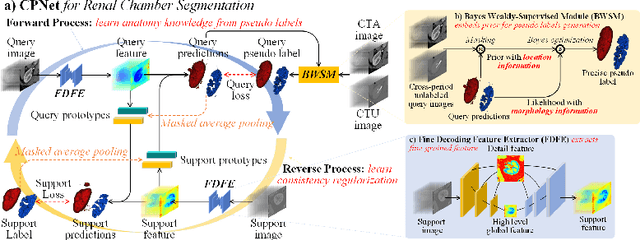
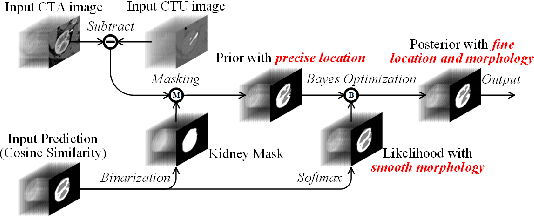
Renal compartment segmentation on CT images targets on extracting the 3D structure of renal compartments from abdominal CTA images and is of great significance to the diagnosis and treatment for kidney diseases. However, due to the unclear compartment boundary, thin compartment structure and large anatomy variation of 3D kidney CT images, deep-learning based renal compartment segmentation is a challenging task. We propose a novel weakly supervised learning framework, Cycle Prototype Network, for 3D renal compartment segmentation. It has three innovations: 1) A Cycle Prototype Learning (CPL) is proposed to learn consistency for generalization. It learns from pseudo labels through the forward process and learns consistency regularization through the reverse process. The two processes make the model robust to noise and label-efficient. 2) We propose a Bayes Weakly Supervised Module (BWSM) based on cross-period prior knowledge. It learns prior knowledge from cross-period unlabeled data and perform error correction automatically, thus generates accurate pseudo labels. 3) We present a Fine Decoding Feature Extractor (FDFE) for fine-grained feature extraction. It combines global morphology information and local detail information to obtain feature maps with sharp detail, so the model will achieve fine segmentation on thin structures. Our model achieves Dice of 79.1% and 78.7% with only four labeled images, achieving a significant improvement by about 20% than typical prototype model PANet.
EnMcGAN: Adversarial Ensemble Learning for 3D Complete Renal Structures Segmentation
Jun 08, 2021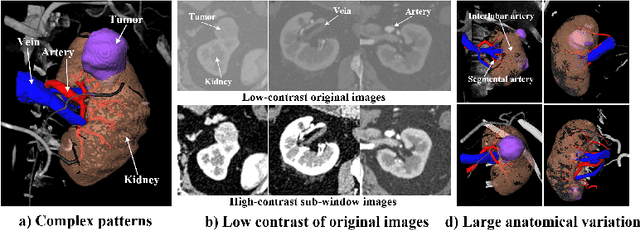

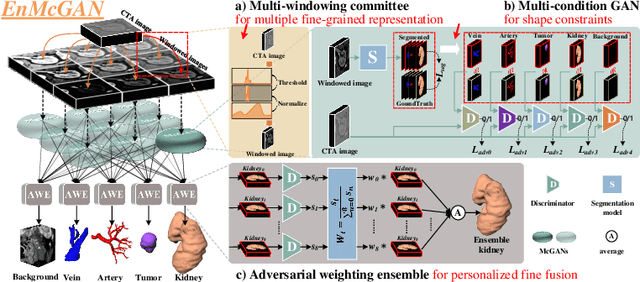
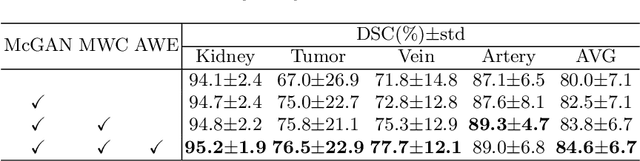
3D complete renal structures(CRS) segmentation targets on segmenting the kidneys, tumors, renal arteries and veins in one inference. Once successful, it will provide preoperative plans and intraoperative guidance for laparoscopic partial nephrectomy(LPN), playing a key role in the renal cancer treatment. However, no success has been reported in 3D CRS segmentation due to the complex shapes of renal structures, low contrast and large anatomical variation. In this study, we utilize the adversarial ensemble learning and propose Ensemble Multi-condition GAN(EnMcGAN) for 3D CRS segmentation for the first time. Its contribution is three-fold. 1)Inspired by windowing, we propose the multi-windowing committee which divides CTA image into multiple narrow windows with different window centers and widths enhancing the contrast for salient boundaries and soft tissues. And then, it builds an ensemble segmentation model on these narrow windows to fuse the segmentation superiorities and improve whole segmentation quality. 2)We propose the multi-condition GAN which equips the segmentation model with multiple discriminators to encourage the segmented structures meeting their real shape conditions, thus improving the shape feature extraction ability. 3)We propose the adversarial weighted ensemble module which uses the trained discriminators to evaluate the quality of segmented structures, and normalizes these evaluation scores for the ensemble weights directed at the input image, thus enhancing the ensemble results. 122 patients are enrolled in this study and the mean Dice coefficient of the renal structures achieves 84.6%. Extensive experiments with promising results on renal structures reveal powerful segmentation accuracy and great clinical significance in renal cancer treatment.
Deep Complementary Joint Model for Complex Scene Registration and Few-shot Segmentation on Medical Images
Aug 03, 2020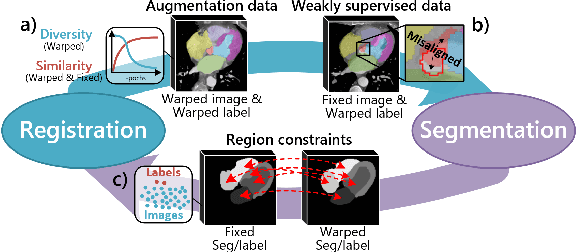

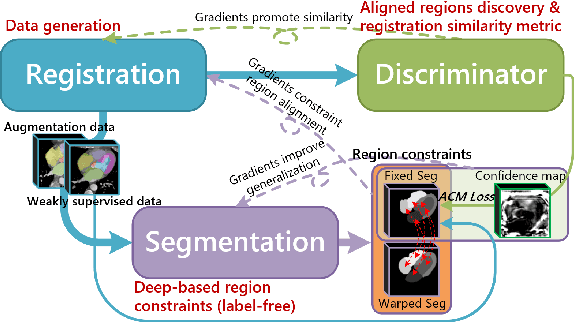
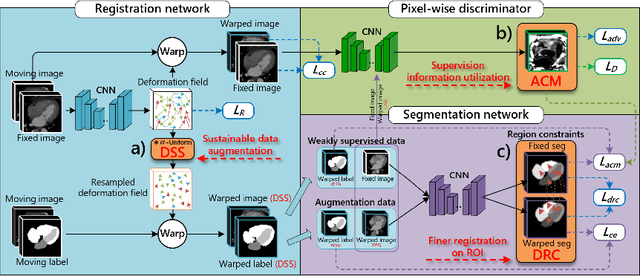
Deep learning-based medical image registration and segmentation joint models utilize the complementarity (augmentation data or weakly supervised data from registration, region constraints from segmentation) to bring mutual improvement in complex scene and few-shot situation. However, further adoption of the joint models are hindered: 1) the diversity of augmentation data is reduced limiting the further enhancement of segmentation, 2) misaligned regions in weakly supervised data disturb the training process, 3) lack of label-based region constraints in few-shot situation limits the registration performance. We propose a novel Deep Complementary Joint Model (DeepRS) for complex scene registration and few-shot segmentation. We embed a perturbation factor in the registration to increase the activity of deformation thus maintaining the augmentation data diversity. We take a pixel-wise discriminator to extract alignment confidence maps which highlight aligned regions in weakly supervised data so the misaligned regions' disturbance will be suppressed via weighting. The outputs from segmentation model are utilized to implement deep-based region constraints thus relieving the label requirements and bringing fine registration. Extensive experiments on the CT dataset of MM-WHS 2017 Challenge show great advantages of our DeepRS that outperforms the existing state-of-the-art models.
Generative networks as inverse problems with fractional wavelet scattering networks
Jul 28, 2020
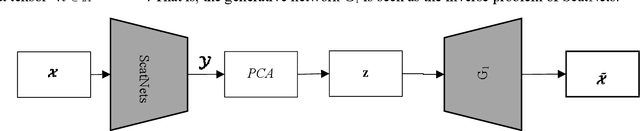
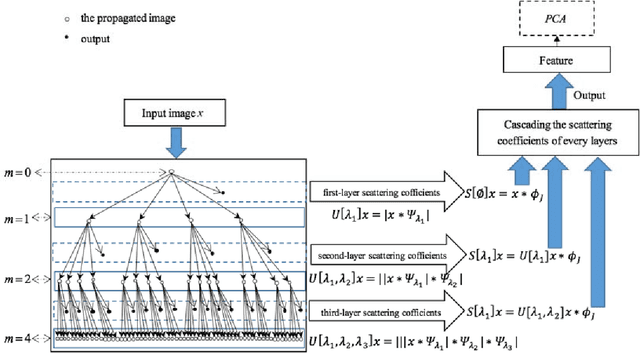
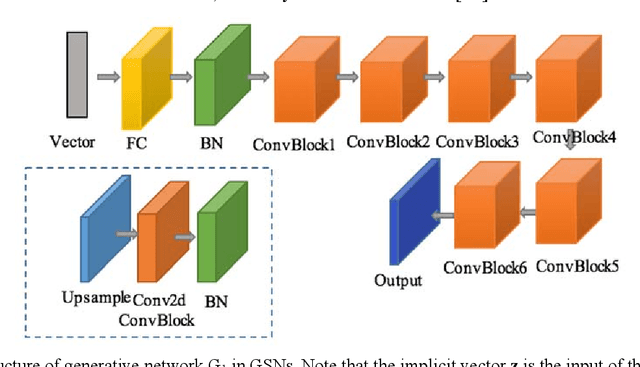
Deep learning is a hot research topic in the field of machine learning methods and applications. Generative Adversarial Networks (GANs) and Variational Auto-Encoders (VAEs) provide impressive image generations from Gaussian white noise, but both of them are difficult to train since they need to train the generator (or encoder) and the discriminator (or decoder) simultaneously, which is easy to cause unstable training. In order to solve or alleviate the synchronous training difficult problems of GANs and VAEs, recently, researchers propose Generative Scattering Networks (GSNs), which use wavelet scattering networks (ScatNets) as the encoder to obtain the features (or ScatNet embeddings) and convolutional neural networks (CNNs) as the decoder to generate the image. The advantage of GSNs is the parameters of ScatNets are not needed to learn, and the disadvantage of GSNs is that the expression ability of ScatNets is slightly weaker than CNNs and the dimensional reduction method of Principal Component Analysis (PCA) is easy to lead overfitting in the training of GSNs, and therefore affect the generated quality in the testing process. In order to further improve the quality of generated images while keep the advantages of GSNs, this paper proposes Generative Fractional Scattering Networks (GFRSNs), which use more expressive fractional wavelet scattering networks (FrScatNets) instead of ScatNets as the encoder to obtain the features (or FrScatNet embeddings) and use the similar CNNs of GSNs as the decoder to generate the image. Additionally, this paper develops a new dimensional reduction method named Feature-Map Fusion (FMF) instead of PCA for better keeping the information of FrScatNets and the effect of image fusion on the quality of image generation is also discussed.
SLNSpeech: solving extended speech separation problem by the help of sign language
Jul 21, 2020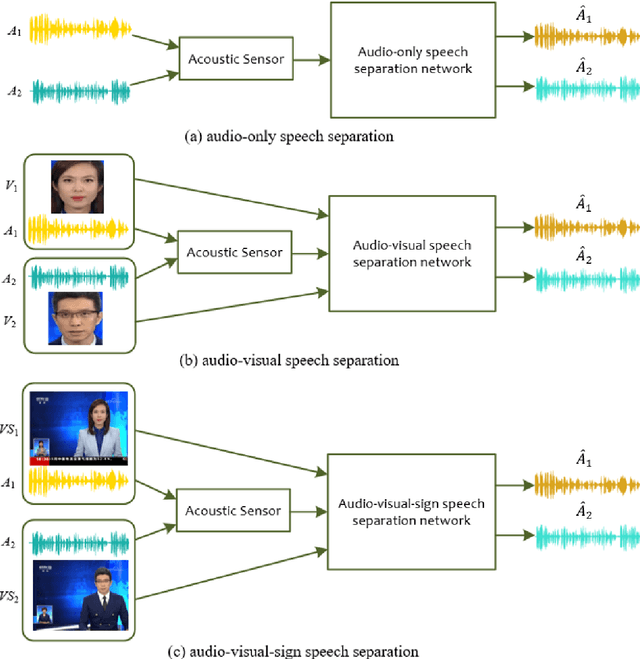


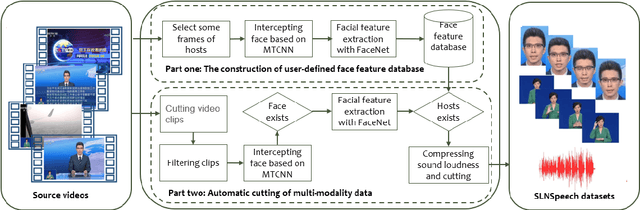
A speech separation task can be roughly divided into audio-only separation and audio-visual separation. In order to make speech separation technology applied in the real scenario of the disabled, this paper presents an extended speech separation problem which refers in particular to sign language assisted speech separation. However, most existing datasets for speech separation are audios and videos which contain audio and/or visual modalities. To address the extended speech separation problem, we introduce a large-scale dataset named Sign Language News Speech (SLNSpeech) dataset in which three modalities of audio, visual, and sign language are coexisted. Then, we design a general deep learning network for the self-supervised learning of three modalities, particularly, using sign language embeddings together with audio or audio-visual information for better solving the speech separation task. Specifically, we use 3D residual convolutional network to extract sign language features and use pretrained VGGNet model to exact visual features. After that, an improved U-Net with skip connections in feature extraction stage is applied for learning the embeddings among the mixed spectrogram transformed from source audios, the sign language features and visual features. Experiments results show that, besides visual modality, sign language modality can also be used alone to supervise speech separation task. Moreover, we also show the effectiveness of sign language assisted speech separation when the visual modality is disturbed. Source code will be released in http://cheertt.top/homepage/
Deep Octonion Networks
Mar 20, 2019
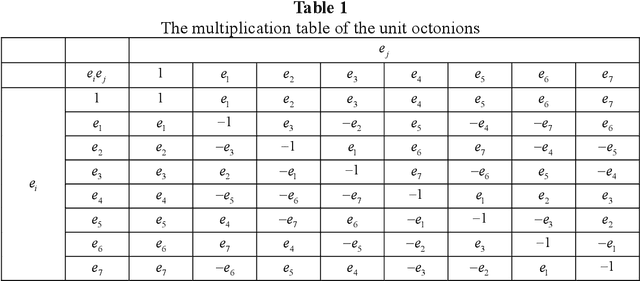
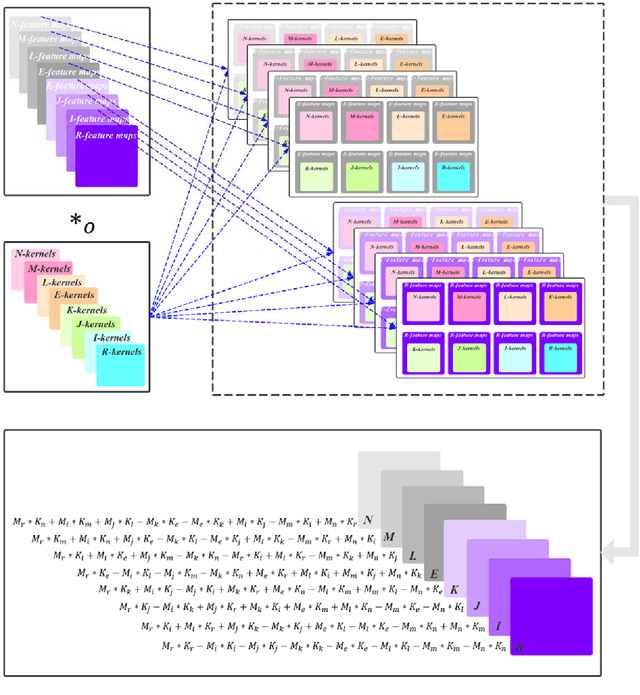
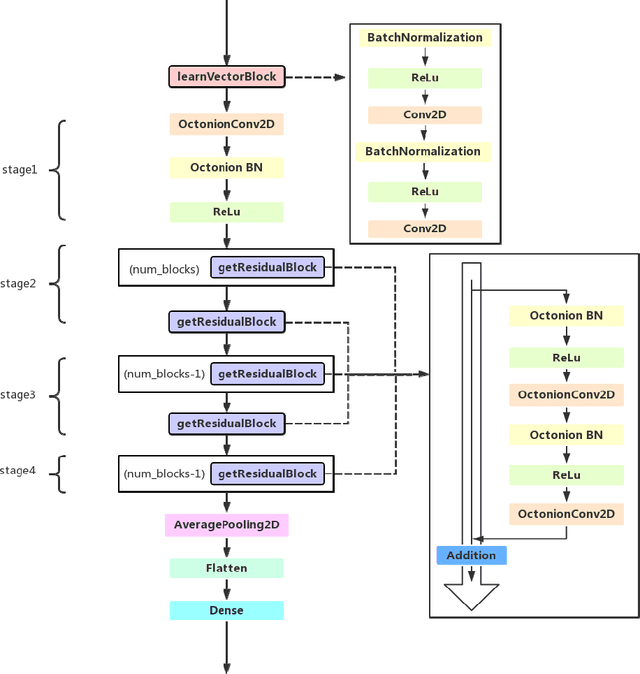
Deep learning is a research hot topic in the field of machine learning. Real-value neural networks (Real NNs), especially deep real networks (DRNs), have been widely used in many research fields. In recent years, the deep complex networks (DCNs) and the deep quaternion networks (DQNs) have attracted more and more attentions. The octonion algebra, which is an extension of complex algebra and quaternion algebra, can provide more efficient and compact expression. This paper constructs a general framework of deep octonion networks (DONs) and provides the main building blocks of DONs such as octonion convolution, octonion batch normalization and octonion weight initialization; DONs are then used in image classification tasks for CIFAR-10 and CIFAR-100 data sets. Compared with the DRNs, the DCNs, and the DQNs, the proposed DONs have better convergence and higher classification accuracy. The success of DONs is also explained by multi-task learning.
Compressing complex convolutional neural network based on an improved deep compression algorithm
Mar 06, 2019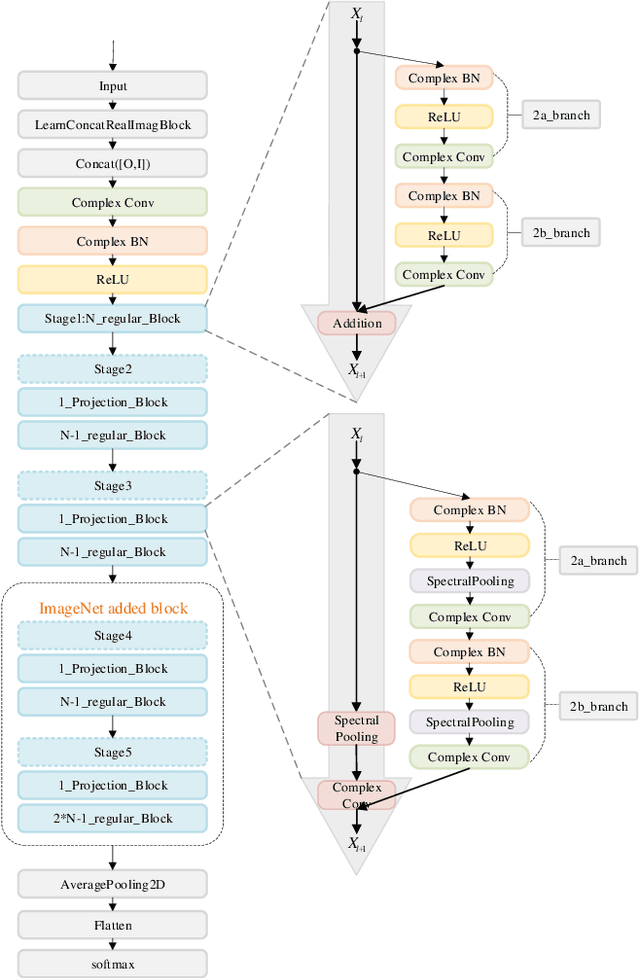
Although convolutional neural network (CNN) has made great progress, large redundant parameters restrict its deployment on embedded devices, especially mobile devices. The recent compression works are focused on real-value convolutional neural network (Real CNN), however, to our knowledge, there is no attempt for the compression of complex-value convolutional neural network (Complex CNN). Compared with the real-valued network, the complex-value neural network is easier to optimize, generalize, and has better learning potential. This paper extends the commonly used deep compression algorithm from real domain to complex domain and proposes an improved deep compression algorithm for the compression of Complex CNN. The proposed algorithm compresses the network about 8 times on CIFAR-10 dataset with less than 3% accuracy loss. On the ImageNet dataset, our method compresses the model about 16 times and the accuracy loss is about 2% without retraining.