 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOSS-CRS: Liberating AIxCC Cyber Reasoning Systems for Real-World Open-Source Security
Mar 09, 2026DARPA's AI Cyber Challenge (AIxCC) showed that cyber reasoning systems (CRSs) can go beyond vulnerability discovery to autonomously confirm and patch bugs: seven teams built such systems and open-sourced them after the competition. Yet all seven open-sourced CRSs remain largely unusable outside their original teams, each bound to the competition cloud infrastructure that no longer exists. We present OSS-CRS, an open, locally deployable framework for running and combining CRS techniques against real-world open-source projects, with budget-aware resource management. We ported the first-place system (Atlantis) and discovered 10 previously unknown bugs (three of high severity) across 8 OSS-Fuzz projects. OSS-CRS is publicly available.
MAPLE: Modality-Aware Post-training and Learning Ecosystem
Feb 12, 2026Multimodal language models now integrate text, audio, and video for unified reasoning. Yet existing RL post-training pipelines treat all input signals as equally relevant, ignoring which modalities each task actually requires. This modality-blind training inflates policy-gradient variance, slows convergence, and degrades robustness to real-world distribution shifts where signals may be missing, added, or reweighted. We introduce MAPLE, a complete modality-aware post-training and learning ecosystem comprising: (1) MAPLE-bench, the first benchmark explicitly annotating minimal signal combinations required per task; (2) MAPO, a modality-aware policy optimization framework that stratifies batches by modality requirement to reduce gradient variance from heterogeneous group advantages; (3) Adaptive weighting and curriculum scheduling that balances and prioritizes harder signal combinations. Systematic analysis across loss aggregation, clipping, sampling, and curriculum design establishes MAPO's optimal training strategy. Adaptive weighting and curriculum focused learning further boost performance across signal combinations. MAPLE narrows uni/multi-modal accuracy gaps by 30.24%, converges 3.18x faster, and maintains stability across all modality combinations under realistic reduced signal access. MAPLE constitutes a complete recipe for deployment-ready multimodal RL post-training.
SoK: DARPA's AI Cyber Challenge (AIxCC): Competition Design, Architectures, and Lessons Learned
Feb 07, 2026DARPA's AI Cyber Challenge (AIxCC, 2023--2025) is the largest competition to date for building fully autonomous cyber reasoning systems (CRSs) that leverage recent advances in AI -- particularly large language models (LLMs) -- to discover and remediate vulnerabilities in real-world open-source software. This paper presents the first systematic analysis of AIxCC. Drawing on design documents, source code, execution traces, and discussions with organizers and competing teams, we examine the competition's structure and key design decisions, characterize the architectural approaches of finalist CRSs, and analyze competition results beyond the final scoreboard. Our analysis reveals the factors that truly drove CRS performance, identifies genuine technical advances achieved by teams, and exposes limitations that remain open for future research. We conclude with lessons for organizing future competitions and broader insights toward deploying autonomous CRSs in practice.
ATLANTIS: AI-driven Threat Localization, Analysis, and Triage Intelligence System
Sep 18, 2025



We present ATLANTIS, the cyber reasoning system developed by Team Atlanta that won 1st place in the Final Competition of DARPA's AI Cyber Challenge (AIxCC) at DEF CON 33 (August 2025). AIxCC (2023-2025) challenged teams to build autonomous cyber reasoning systems capable of discovering and patching vulnerabilities at the speed and scale of modern software. ATLANTIS integrates large language models (LLMs) with program analysis -- combining symbolic execution, directed fuzzing, and static analysis -- to address limitations in automated vulnerability discovery and program repair. Developed by researchers at Georgia Institute of Technology, Samsung Research, KAIST, and POSTECH, the system addresses core challenges: scaling across diverse codebases from C to Java, achieving high precision while maintaining broad coverage, and producing semantically correct patches that preserve intended behavior. We detail the design philosophy, architectural decisions, and implementation strategies behind ATLANTIS, share lessons learned from pushing the boundaries of automated security when program analysis meets modern AI, and release artifacts to support reproducibility and future research.
An Effective Pipeline for a Real-world Clothes Retrieval System
May 26, 2020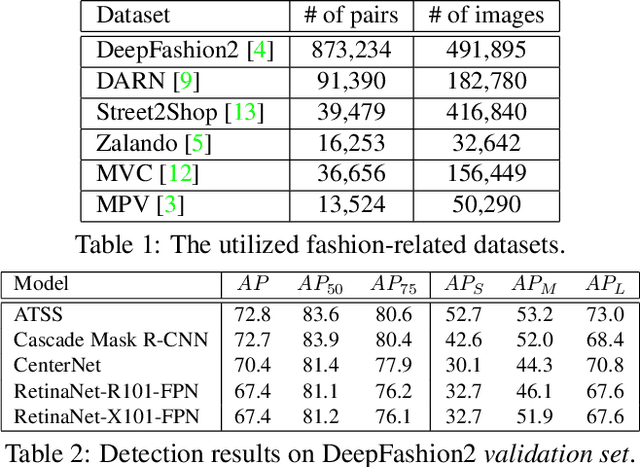

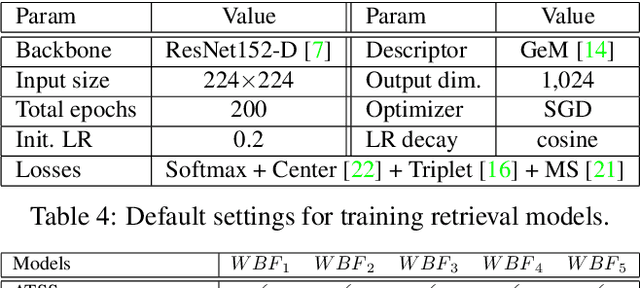
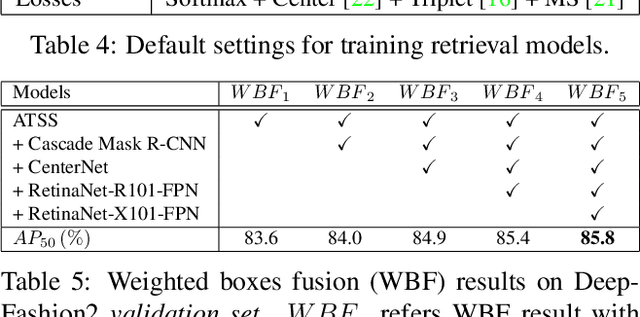
In this paper, we propose an effective pipeline for clothes retrieval system which has sturdiness on large-scale real-world fashion data. Our proposed method consists of three components: detection, retrieval, and post-processing. We firstly conduct a detection task for precise retrieval on target clothes, then retrieve the corresponding items with the metric learning-based model. To improve the retrieval robustness against noise and misleading bounding boxes, we apply post-processing methods such as weighted boxes fusion and feature concatenation. With the proposed methodology, we achieved 2nd place in the DeepFashion2 Clothes Retrieval 2020 challenge.
A Benchmark on Tricks for Large-scale Image Retrieval
Jul 27, 2019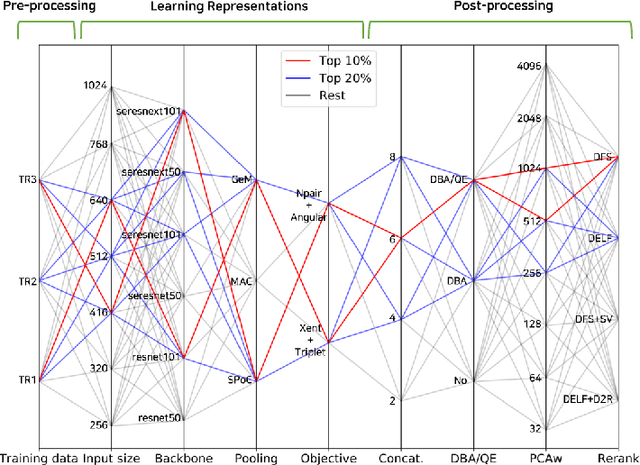
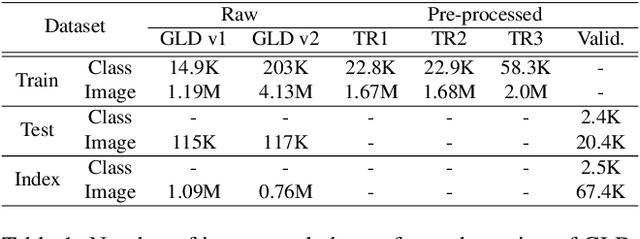

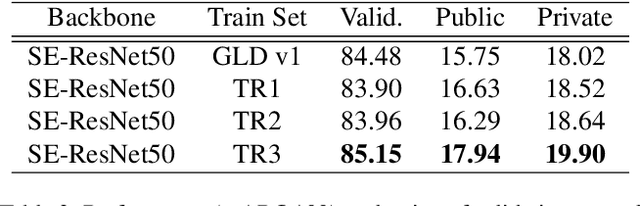
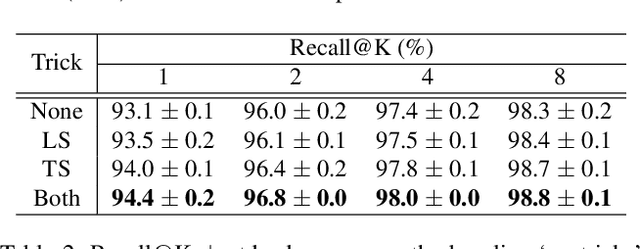
Many studies have been performed on metric learning, which has become a key ingredient in top-performing methods of instance-level image retrieval. Meanwhile, less attention has been paid to pre-processing and post-processing tricks that can significantly boost performance. Furthermore, we found that most previous studies used small scale datasets to simplify processing. Because the behavior of a feature representation in a deep learning model depends on both domain and data, it is important to understand how model behave in large-scale environments when a proper combination of retrieval tricks is used. In this paper, we extensively analyze the effect of well-known pre-processing, post-processing tricks, and their combination for large-scale image retrieval. We found that proper use of these tricks can significantly improve model performance without necessitating complex architecture or introducing loss, as confirmed by achieving a competitive result on the Google Landmark Retrieval Challenge 2019.
Combination of Multiple Global Descriptors for Image Retrieval
Mar 26, 2019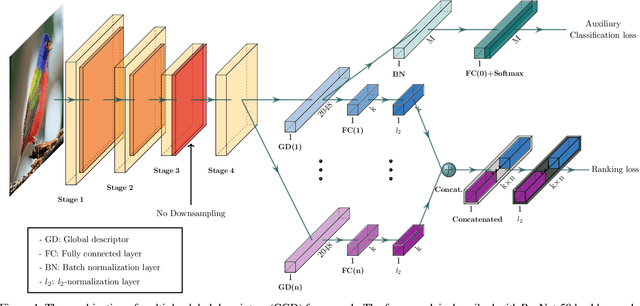

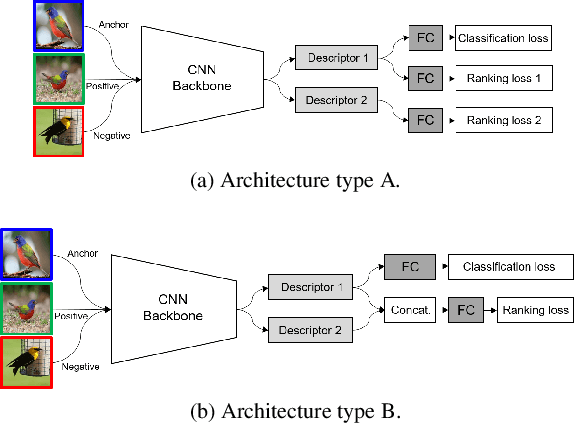
Recent studies in image retrieval task have shown that ensembling different models and combining multiple global descriptors lead to performance improvement. However, training different models for ensemble is not only difficult but also inefficient with respect to time or memory. In this paper, we propose a novel framework that exploits multiple global descriptors to get an ensemble-like effect while it can be trained in an end-to-end manner. The proposed framework is flexible and expandable by the global descriptor, CNN backbone, loss, and dataset. Moreover, we investigate the effectiveness of combining multiple global descriptors with quantitative and qualitative analysis. Our extensive experiments show that the combined descriptor outperforms a single global descriptor, as it can utilize different types of feature properties. In the benchmark evaluation, the proposed framework achieves the state-of-the-art performance on the CARS196, CUB200-2011, In-shop Clothes and Stanford Online Products on image retrieval tasks by a large margin compared to competing approaches.