 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQAGait: Revisit Gait Recognition from a Quality Perspective
Jan 24, 2024



Gait recognition is a promising biometric method that aims to identify pedestrians from their unique walking patterns. Silhouette modality, renowned for its easy acquisition, simple structure, sparse representation, and convenient modeling, has been widely employed in controlled in-the-lab research. However, as gait recognition rapidly advances from in-the-lab to in-the-wild scenarios, various conditions raise significant challenges for silhouette modality, including 1) unidentifiable low-quality silhouettes (abnormal segmentation, severe occlusion, or even non-human shape), and 2) identifiable but challenging silhouettes (background noise, non-standard posture, slight occlusion). To address these challenges, we revisit gait recognition pipeline and approach gait recognition from a quality perspective, namely QAGait. Specifically, we propose a series of cost-effective quality assessment strategies, including Maxmial Connect Area and Template Match to eliminate background noises and unidentifiable silhouettes, Alignment strategy to handle non-standard postures. We also propose two quality-aware loss functions to integrate silhouette quality into optimization within the embedding space. Extensive experiments demonstrate our QAGait can guarantee both gait reliability and performance enhancement. Furthermore, our quality assessment strategies can seamlessly integrate with existing gait datasets, showcasing our superiority. Code is available at https://github.com/wzb-bupt/QAGait.
Towards More Efficient Depression Risk Recognition via Gait
Oct 10, 2023



Depression, a highly prevalent mental illness, affects over 280 million individuals worldwide. Early detection and timely intervention are crucial for promoting remission, preventing relapse, and alleviating the emotional and financial burdens associated with depression. However, patients with depression often go undiagnosed in the primary care setting. Unlike many physiological illnesses, depression lacks objective indicators for recognizing depression risk, and existing methods for depression risk recognition are time-consuming and often encounter a shortage of trained medical professionals. The correlation between gait and depression risk has been empirically established. Gait can serve as a promising objective biomarker, offering the advantage of efficient and convenient data collection. However, current methods for recognizing depression risk based on gait have only been validated on small, private datasets, lacking large-scale publicly available datasets for research purposes. Additionally, these methods are primarily limited to hand-crafted approaches. Gait is a complex form of motion, and hand-crafted gait features often only capture a fraction of the intricate associations between gait and depression risk. Therefore, this study first constructs a large-scale gait database, encompassing over 1,200 individuals, 40,000 gait sequences, and covering six perspectives and three types of attire. Two commonly used psychological scales are provided as depression risk annotations. Subsequently, a deep learning-based depression risk recognition model is proposed, overcoming the limitations of hand-crafted approaches. Through experiments conducted on the constructed large-scale database, the effectiveness of the proposed method is validated, and numerous instructive insights are presented in the paper, highlighting the significant potential of gait-based depression risk recognition.
FastPoseGait: A Toolbox and Benchmark for Efficient Pose-based Gait Recognition
Sep 02, 2023We present FastPoseGait, an open-source toolbox for pose-based gait recognition based on PyTorch. Our toolbox supports a set of cutting-edge pose-based gait recognition algorithms and a variety of related benchmarks. Unlike other pose-based projects that focus on a single algorithm, FastPoseGait integrates several state-of-the-art (SOTA) algorithms under a unified framework, incorporating both the latest advancements and best practices to ease the comparison of effectiveness and efficiency. In addition, to promote future research on pose-based gait recognition, we provide numerous pre-trained models and detailed benchmark results, which offer valuable insights and serve as a reference for further investigations. By leveraging the highly modular structure and diverse methods offered by FastPoseGait, researchers can quickly delve into pose-based gait recognition and promote development in the field. In this paper, we outline various features of this toolbox, aiming that our toolbox and benchmarks can further foster collaboration, facilitate reproducibility, and encourage the development of innovative algorithms for pose-based gait recognition. FastPoseGait is available at https://github.com//BNU-IVC/FastPoseGait and is actively maintained. We will continue updating this report as we add new features.
Free Lunch for Gait Recognition: A Novel Relation Descriptor
Aug 28, 2023



Gait recognition is to seek correct matches for query individuals by their unique walking patterns. However, current methods focus solely on extracting individual-specific features, overlooking inter-personal relationships. In this paper, we propose a novel $\textbf{Relation Descriptor}$ that captures not only individual features but also relations between test gaits and pre-selected anchored gaits. Specifically, we reinterpret classifier weights as anchored gaits and compute similarity scores between test features and these anchors, which re-expresses individual gait features into a similarity relation distribution. In essence, the relation descriptor offers a holistic perspective that leverages the collective knowledge stored within the classifier's weights, emphasizing meaningful patterns and enhancing robustness. Despite its potential, relation descriptor poses dimensionality challenges since its dimension depends on the training set's identity count. To address this, we propose the Farthest Anchored-gait Selection to identify the most discriminative anchored gaits and an Orthogonal Regularization to increase diversity within anchored gaits. Compared to individual-specific features extracted from the backbone, our relation descriptor can boost the performances nearly without any extra costs. We evaluate the effectiveness of our method on the popular GREW, Gait3D, CASIA-B, and OU-MVLP, showing that our method consistently outperforms the baselines and achieves state-of-the-art performances.
Unsupervised Gait Recognition with Selective Fusion
Mar 19, 2023Previous gait recognition methods primarily trained on labeled datasets, which require painful labeling effort. However, using a pre-trained model on a new dataset without fine-tuning can lead to significant performance degradation. So to make the pre-trained gait recognition model able to be fine-tuned on unlabeled datasets, we propose a new task: Unsupervised Gait Recognition (UGR). We introduce a new cluster-based baseline to solve UGR with cluster-level contrastive learning. But we further find more challenges this task meets. First, sequences of the same person in different clothes tend to cluster separately due to the significant appearance changes. Second, sequences taken from 0 and 180 views lack walking postures and do not cluster with sequences taken from other views. To address these challenges, we propose a Selective Fusion method, which includes Selective Cluster Fusion (SCF) and Selective Sample Fusion (SSF). With SCF, we merge matched clusters of the same person wearing different clothes by updating the cluster-level memory bank with a multi-cluster update strategy. And in SSF, we merge sequences taken from front/back views gradually with curriculum learning. Extensive experiments show the effectiveness of our method in improving the rank-1 accuracy in walking with different coats condition and front/back views conditions.
GPGait: Generalized Pose-based Gait Recognition
Mar 09, 2023



Recent works on pose-based gait recognition have demonstrated the potential of using such simple information to achieve results comparable to silhouette-based methods. However, the generalization ability of pose-based methods on different datasets is undesirably inferior to that of silhouette-based ones, which has received little attention but hinders the application of these methods in real-world scenarios. To improve the generalization ability of pose-based methods across datasets, we propose a Generalized Pose-based Gait recognition (GPGait) framework. First, a Human-Oriented Transformation (HOT) and a series of Human-Oriented Descriptors (HOD) are proposed to obtain a unified pose representation with discriminative multi-features. Then, given the slight variations in the unified representation after HOT and HOD, it becomes crucial for the network to extract local-global relationships between the keypoints. To this end, a Part-Aware Graph Convolutional Network (PAGCN) is proposed to enable efficient graph partition and local-global spatial feature extraction. Experiments on four public gait recognition datasets, CASIA-B, OUMVLP-Pose, Gait3D and GREW, show that our model demonstrates better and more stable cross-domain capabilities compared to existing skeleton-based methods, achieving comparable recognition results to silhouette-based ones. The code will be released.
Exploring Deep Models for Practical Gait Recognition
Mar 09, 2023



Gait recognition is a rapidly advancing vision technique for person identification from a distance. Prior studies predominantly employed relatively small and shallow neural networks to extract subtle gait features, achieving impressive successes in indoor settings. Nevertheless, experiments revealed that these existing methods mostly produce unsatisfactory results when applied to newly released in-the-wild gait datasets. This paper presents a unified perspective to explore how to construct deep models for state-of-the-art outdoor gait recognition, including the classical CNN-based and emerging Transformer-based architectures. Consequently, we emphasize the importance of suitable network capacity, explicit temporal modeling, and deep transformer structure for discriminative gait representation learning. Our proposed CNN-based DeepGaitV2 series and Transformer-based SwinGait series exhibit significant performance gains in outdoor scenarios, \textit{e.g.}, about +30\% rank-1 accuracy compared with many state-of-the-art methods on the challenging GREW dataset. This work is expected to further boost the research and application of gait recognition. Code will be available at https://github.com/ShiqiYu/OpenGait.
OpenGait: Revisiting Gait Recognition Toward Better Practicality
Nov 19, 2022



Gait recognition is one of the most important long-distance identification technologies and increasingly gains popularity in both research and industry communities. Although significant progress has been made in indoor datasets, much evidence shows that gait recognition techniques perform poorly in the wild. More importantly, we also find that many conclusions from prior works change with the evaluation datasets. Therefore, the more critical goal of this paper is to present a comprehensive benchmark study for better practicality rather than only a particular model for better performance. To this end, we first develop a flexible and efficient gait recognition codebase named OpenGait. Based on OpenGait, we deeply revisit the recent development of gait recognition by re-conducting the ablative experiments. Encouragingly, we find many hidden troubles of prior works and new insights for future research. Inspired by these discoveries, we develop a structurally simple, empirically powerful and practically robust baseline model, GaitBase. Experimentally, we comprehensively compare GaitBase with many current gait recognition methods on multiple public datasets, and the results reflect that GaitBase achieves significantly strong performance in most cases regardless of indoor or outdoor situations. The source code is available at \url{https://github.com/ShiqiYu/OpenGait}.
Deep Learning-based Occluded Person Re-identification: A Survey
Jul 29, 2022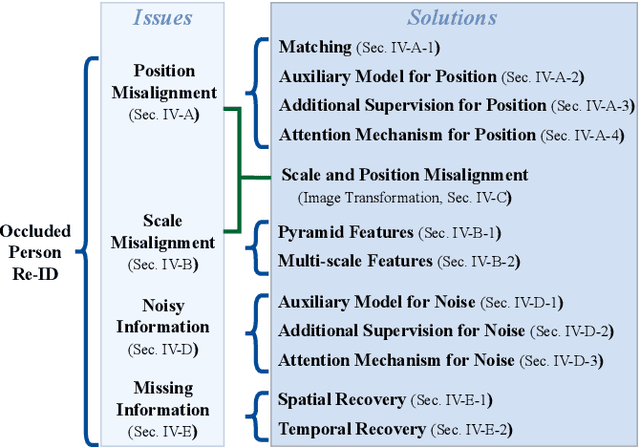
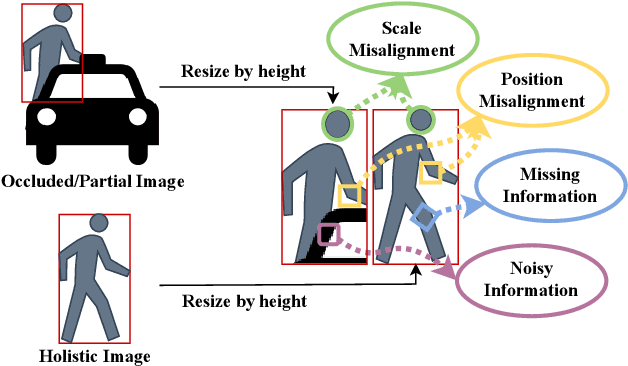

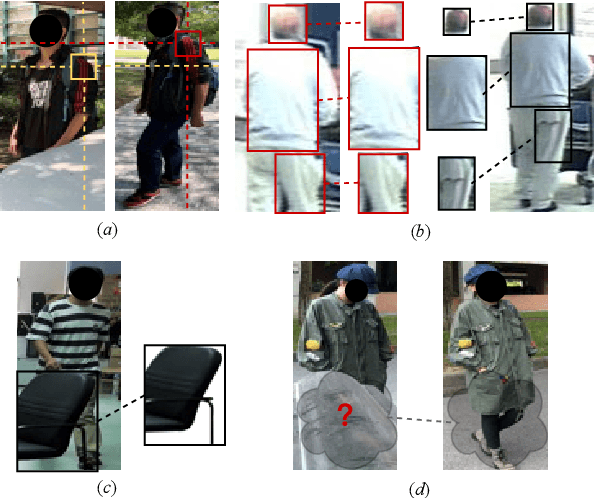
Occluded person re-identification (Re-ID) aims at addressing the occlusion problem when retrieving the person of interest across multiple cameras. With the promotion of deep learning technology and the increasing demand for intelligent video surveillance, the frequent occlusion in real-world applications has made occluded person Re-ID draw considerable interest from researchers. A large number of occluded person Re-ID methods have been proposed while there are few surveys that focus on occlusion. To fill this gap and help boost future research, this paper provides a systematic survey of occluded person Re-ID. Through an in-depth analysis of the occlusion in person Re-ID, most existing methods are found to only consider part of the problems brought by occlusion. Therefore, we review occlusion-related person Re-ID methods from the perspective of issues and solutions. We summarize four issues caused by occlusion in person Re-ID, i.e., position misalignment, scale misalignment, noisy information, and missing information. The occlusion-related methods addressing different issues are then categorized and introduced accordingly. After that, we summarize and compare the performance of recent occluded person Re-ID methods on four popular datasets: Partial-ReID, Partial-iLIDS, Occluded-ReID, and Occluded-DukeMTMC. Finally, we provide insights on promising future research directions.
Progressive Feature Learning for Realistic Cloth-Changing Gait Recognition
Jul 24, 2022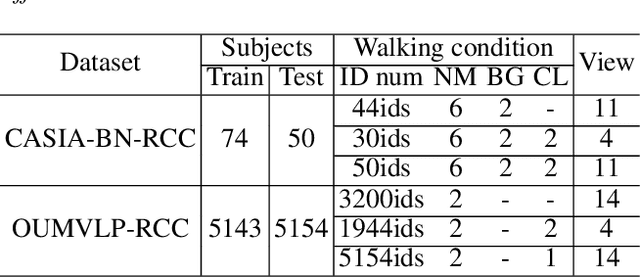
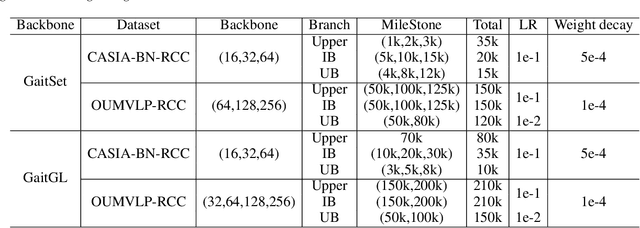
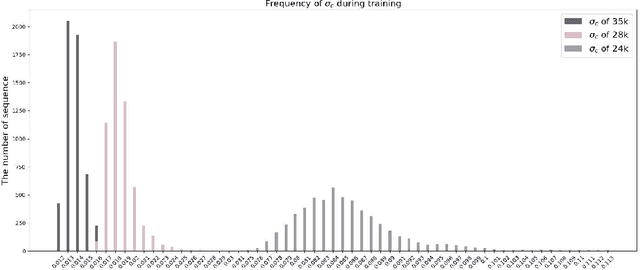
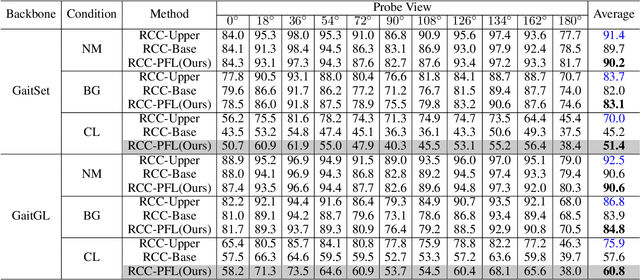
Gait recognition is instrumental in crime prevention and social security, for it can be conducted at a long distance without the cooperation of subjects. However, existing datasets and methods cannot deal with the most challenging problem in realistic gait recognition effectively: walking in different clothes (CL). In order to tackle this problem, we propose two benchmarks: CASIA-BN-RCC and OUMVLP-RCC, to simulate the cloth-changing condition in practice. The two benchmarks can force the algorithm to realize cross-view and cross-cloth with two sub-datasets. Furthermore, we propose a new framework that can be applied with off-the-shelf backbones to improve its performance in the Realistic Cloth-Changing problem with Progressive Feature Learning. Specifically, in our framework, we design Progressive Mapping and Progressive Uncertainty to extract the cross-view features and then extract cross-cloth features on the basis. In this way, the features from the cross-view sub-dataset can first dominate the feature space and relieve the uneven distribution caused by the adverse effect from the cross-cloth sub-dataset. The experiments on our benchmarks show that our framework can effectively improve the recognition performance in CL conditions. Our codes and datasets will be released after accepted.